1 引言
各位朋友大家好,欢迎来到月来客栈。在前面的多篇文章中笔者分别介绍了多种不同的决策树生成算法,从决策树的构造原理便可以看出,越是靠近决策树顶端的特征维度越能够对不同类别的样本进行区分,也就意味着越是接近于根节点的特征维度越重要。因此,在sklearn中的类DecisionTreeClassifier里面,同样也有feature_importances_方法来输出每个特征的重要性值。只是通过随机森林来进行特征重要性评估更加准确。不过想要弄清楚随机森林中的特征重要性评估过程,还得从决策树说起。
2 随机森林
在正式介绍特征重要性评估的计算过程之前,我们先来简单回顾一下随机森林的构造原理。
2.1 随机森林原理
随机森林本质上也就是基于决策树的Bagging集成学习模型。因此,随机森林的建模过程总体上可以分为三步[1]:
第一步,对原始数据集进行随机采样,得到多个训练子集;
第二步,在各个训练子集上训练得到不同的决策树模型;
第三步,将训练得到的多个决策树模型进行组合,然后得到最后的输出结果。
如图1所示为随机对样本点和特征采样后训练得到的若干决策树模型组成的随机森林。从图中可以看出,即使同一个样本在不同树中所归属的叶子节点也不尽相同,甚至连类别也可能不同。但是这也充分体现了Bagging集成模型的优点,通过“平均”来提高模型的泛化能力。
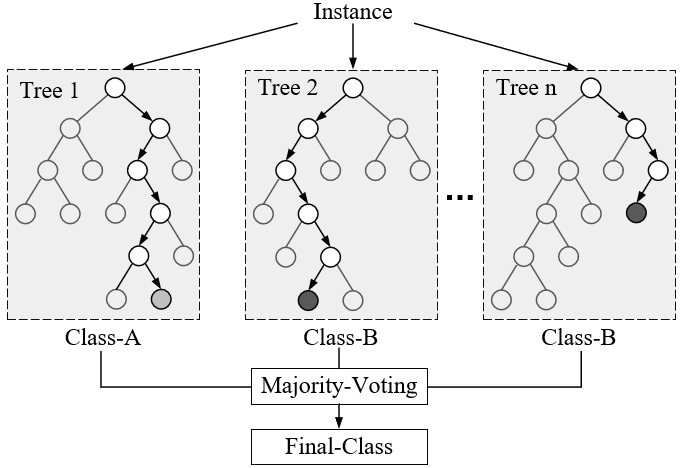
在图1中,多个不同结构的决策树模型构成了随机森林,并且在模型输出时将会以投票的方式决策出最终的输出类别。同时,随机森林与普通Bagging集成学习方法存在的一点差别就是,随机森林中每一个决策树在每次划分节点的过程中,还会有一个随机的过程[1],即只会从已有的特征中再随机选择部分特征参与节点划分,这一过程也被称为“Feature Bagging”。之所以要这么做是为了减小各个树模型之间的关联性。例如训练数据中存在着某些差异性较大的特征,那么所有的决策树在节点划分时就会选择同样的特征,使得最终得到的决策树之间具有较强的关联性,即每棵树都类似。
2.2 随机森林示例代码
介绍完随机森林的基本原理后,我们再来看一看如何通过sklearn完成随机森林的建模任务。在sklearn中,可以通过sklearn.ensemble中的RandomForestClassifier模块来导入模块随机森林。下面先来介绍一下RandomForestClassifier类中常见的重要参数及其含义。
1def __init__(self,2 n_estimators=100,3 criterion="gini",4 max_depth=None,5 min_samples_split=2,6 min_samples_leaf=1,7 max_features="auto",8 bootstrap=True,9 max_samples=None):上述代码是类RandomForestClassifier初始化方法中的部分参数,其中n_estimators表示在随机森林中决策树的数量;criterion表示指定构建决策树的算法;max_depth表示允许决策树的最大深度;min_samples_split表示节点允许继续划分的最少样本数,即如果划分后的节点中样本数少于该值,将不会进行划分;min_samples_leaf叶子节点所需要的最少样本数;max_features表示每次对节点进行划分时候选特征的最大数量,即节点每次在进行划分时会先在原始特征中随机的选取max_features个候选特征,然后在候选特征中选择最佳特征;bootstrap表示是否对原始数据集进行采样,如果为False则所有决策树在构造时均使用相同的样本; max_samples表示每个训练子集中样本数量的最大值(当bootstrap=True时),其默认值为None,即等于原始样本的数量。
注意:max_samples=None仅仅只是表示采样的样本数等于原始训练集的样本数,不代表抽样后的子训练集等同于原始训练集,因为采样时样本可以重复。
一般来说,在sklearn的各个模型中,对于大多数参数来说保持默认即可,对于少部分关键参数可采样交叉验证进行选择。
下面以iris数据集为例来进行RandomForestClassifier的集成学习建模任务,完整代码见[2]。
xxxxxxxxxx61if __name__ == '__main__':2 x_train, x_test, y_train, y_test = load_data()3 model = RandomForestClassifier(n_estimators=2, max_features=3, 4 random_state=2)5 model.fit(x_train, y_train)6 print(model.score(x_test, y_test)) # 0.95可以看到,尽管随机森林这么复杂的一个模型,在sklearn中同样可以通过几行代码来完成建模。同时,在完成随机森林的训练后,可以通过model.estimators_方法来得到所有的决策树对象,然后分别对其进行可视化就可以得到整个随机森林可视化结果。当然,最重要的是可以通过model.feature_importances_方法来得到每个特征的重要性程度以进行特征筛选去掉无关特征。
3 特征重要性评估
3.1 决策树中的特征评估
在sklearn中,决策树是通过基于基尼纯度的减少量来对特征进行重要性评估,当然基尼纯度也可以换成信息增益或者是信息增益比。具体的,对于决策树中划分每个节点的特征来说,其特征重要性计算公式为[3]
其中表 的样本数;表示当前节点的样本数;表示当前节点的纯度;表示当前节点左孩子中的样本数;表示当前节点左孩子的纯度;表示当前节点右孩子中的样本数;表示当前节点右孩子的纯度。
以上面第2节中随机森林里的其中一棵决策树为例,其在每次进行节点划分时的各项信息如图2所示。
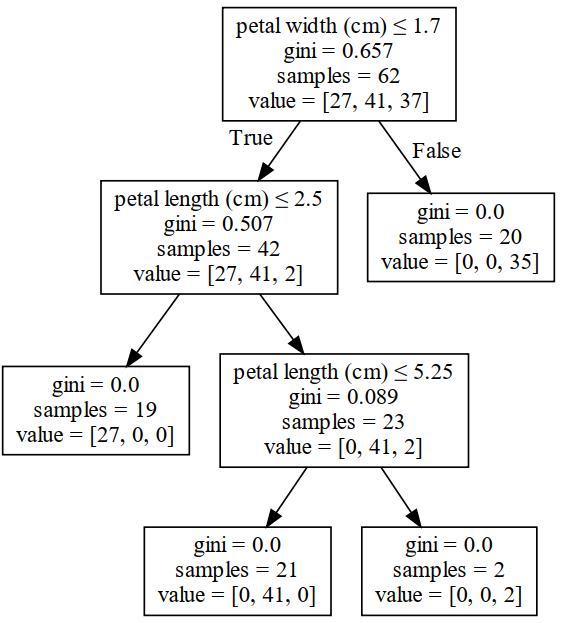
这里有一个小细节需要注意的地方便是,在图2中每个节点里samples的数量指的是不重复的样本数(因为采样会有重复),而列表value中的值则包含有重复样本。例如在根节点中,samples=62表示一共有62个不同的样本点,但实际上该节点中有105个样本点,即有43个重复出现。
此时,对于特征petal width来说,根据式可知其特征重要性值为
对于特征petal length来说,由于其在两次节点划分中均有参与,所以它的特征重要性为
对于另外两个特征sepal length和sepal width来说,由于两者并没有参与决策树节点的划分,所以其重要性均为0。因此,根据图2所示的决策树我们就得到了各个特征的重要性评估结果。
3.2 随机森林中的特征评估
在介绍完决策树中的特征重要性评估后,再来看随机森林中的特征重要性评估过程就相对容易了。在sklearn中,随机森林的特征重要性评估主要也是基于多棵决策树的特征重要性结果计算而来,称为平均纯度减少量(Mean Decrease in Impurity,MDI)。MDI的主要计算过程就是将多棵决策树的特征重要性值取了一次平均。
对于第2节中的随机森林来说,其另外一棵决策树在每次进行节点划分时的各项信息如图3所示。
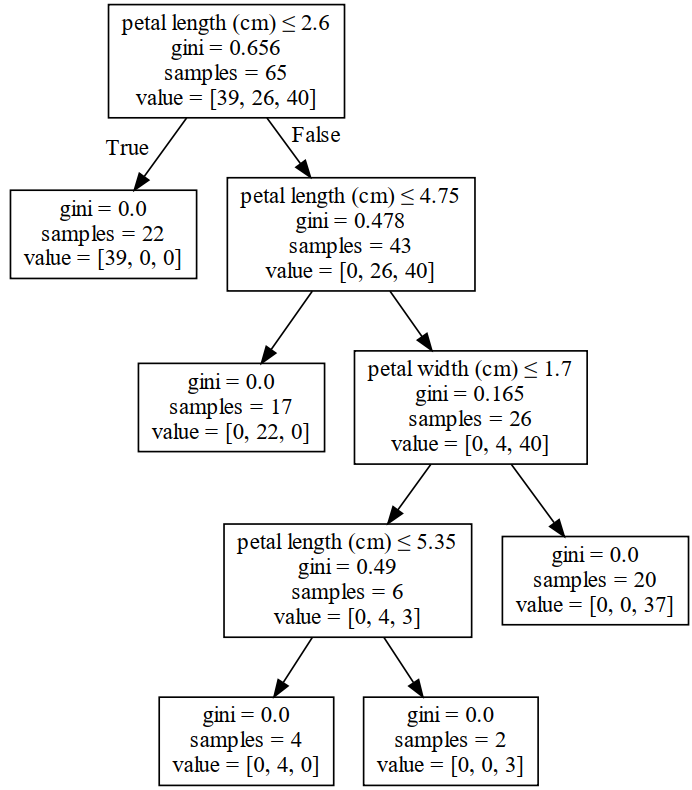
从图3可以看出,一共有2个特征参与到了节点的划分过程中。根据式可知,特征petal length的重要性为
特征petal width的重要性为
到此为止,对于第2节中的随机森林,其两棵决策树对应的计算得到特征重要性如下表所示。
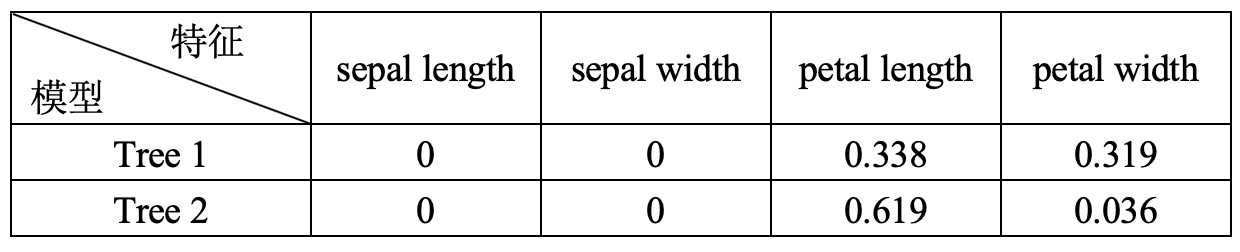
在sklearn中,对于决策树计算得到的特征重要性值默认情况下还会进行标准化,即每个维度均会除以所有维度的和。进一步,对于随机森林来说,其各个特征的重要性值则为所有决策树对应特征重要性的平均值在进行标准化。因此,对于上表中的结果来说,最终每个特征重要性值如下表所示。

上述详细的计算过程可以参见代码[2]。
从最后的结果可以看出,在数据集iris中对分类起决定性作用的为最后两个特征维度。因此,各位读者也可以进行一个对比,只用最后两个维度来进行分类并观察其准确率,对比代码参见[2]。
4 总结
在这篇文章中,笔者首先和大家一起简单回顾了一下随机森林的构造原理;然后介绍了在决策树中如何来进行特征的重要性评估;最后详细介绍了在随机森林中是如何进行特征的重要性评估计算过程。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加笔者微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] https://en.wikipedia.org/wiki/Random_forest
[2] https://github.com/moon-hotel/MachineLearningWithMe
[3]https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html