各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在前4章内容中,笔者已经分别介绍了线性回归、逻辑回归、模型的改善与泛化以及K近邻算法。从这章开始,我们将继续开始学习下一个新的有监督算法模型——朴素贝叶斯(Naive Bayes, NB)。
以下为内容目录,大家可以根据需要进行定位。
6.1朴素贝叶斯算法6.1.1概念介绍6.1.2理解朴素贝叶斯6.1.3计算示例6.1.4 求解步骤6.1.5 小结6.2 贝叶斯估计6.2.1 平滑处理6.2.2 计算示例6.2.3 小结引用推荐阅读
6.1朴素贝叶斯算法
那么什么又是朴素贝叶斯呢?从名字也可以看出,朴素贝叶斯算法与贝叶斯公式有着莫大的关联,说得简单点朴素贝叶斯就是由贝叶斯公式加“朴素”这一条件所构成。
在看贝叶斯算法的相关内容时,相信各位读者一定会被突如其来的数学概念搞得头昏脑胀。比如先验概率(Prior Probability)、后验概率(Posteriori Probability,) 极大似然估计(Maximum Likelihood Estimation ),极大后验概率估计(Maximum A Posteriori Estimation),等。所以下面,笔者将先简单的介绍一下这几个概念,让读者先对这部分内容有一个感性的认识,然后再继续介绍后面的内容。
6.1.1概念介绍
1) 先验概率
所谓先验概率指的就是根据历史经验得出来的概率。例如可以通过西瓜的颜色、敲的声音来判断其是否成熟。因为你已经有了通过颜色和声音来判断的“经验”,不管这个经验是你自己学会的还是别人告诉你的。又如在某2分类数据集中,其中正样本有4个,负样本有6个,那么通过这个数据集能够学习到的先验知识便是任取一个样本,其为正样本的可能性为40%,为负样本的可能性为60%。最后举个例子,假如办公室失窃了,理论上每个人都可能是小偷。但可以根据对每个人的了解分析得出一个可能性,比如张三偷窃的可能性为20%,李四偷窃的可能性为30%,王五偷窃的可能性为50%,而这就被称之为先验概率,它是通过历史经验得来的。
2) 后验概率
所谓后验概率指的就是通过贝叶斯公式推断得到的结果。例如上述例子中,不可能因为负样本出现的可能性为60%就判定任意取出的样本为负样本;也不能因为王五偷窃的可能性最大就判定每次办公室失窃都是他所为。先验知识只能帮助我们先取得一个大致的判断,而事实情况需要根据先验概率和条件概率来进行计算。
3) 极大后验概率估计
一言以蔽之,极大后验概率指的是在所有后验概率中选择其中最大的一个。例如上述例子中,根据先验概率和条件概率便可以计算出每个样本属于正样本还是负样本的后验概率。最后在判断该样本属于何种类别时,挑选后验概率最大的类别即可。
4) 极大似然估计
所谓极大似然估计(即最大似然估计)指的是用来估计使得当前已知结果最有可能发生的模型参数值(可以参见3.4.3节中的介绍)。例如上述例子中,已知的当前结果为正样本有4个,负样本有6个。那么什么样的模型参数能够使得这一结果最可能发生呢?此时只需要最大化式即可。
其中为属于正样本的概率。
6.1.2理解朴素贝叶斯
由贝叶斯公式可知
假设为最终的分类标签,为一系列的特征属性,那么在使用朴素贝叶斯进行样本分类的时候,实际计算的应该就是每个样本在当前的特征取值为的情况下,它属于类别的概率。因此,进一步当计算出特征值属于每个类别的概率后,再挑选概率值最大时所对应的类别即可作为该样本的分类。但是,在实际情况中对于之间的联合概率分布是不知道的,说得直白点就是我们并不知道数据集的生成规则。但是,好在可通过先验概率分布乘以条件概率分布来得到联合分布,即将公式转换为
现在假设输入空间,为维向量的集合,输出空间为类标记,输入为特征向量,输出为类标记。同时,是定义在输入空间上的随机变量,是定义在输出空间上的随机变量,也就是说是一个的矩阵,为类标签。是和的联合概率分布,训练集由独立同分布产生。
其中表示该类别一共有多少个样本,表示样本总数。
同时,对于已知类标下的条件概率分布为
其中表示第个特征的取值。
从式可知,在实际情况中想要知道其条件概率是不能的。因此朴素贝叶斯对条件概率分布又做了条件独立性假设,即,而这也是“朴素”一词的由来。故式可改写为
由此,根据公式的分析可知,对于已知特征属性的条件下,其属于类别的后验概率为
进一步,将式代入可得
于是,朴素贝叶斯分类器可以表示为
即通过计算出任意样本属于类别的概率后,选择其中概率最大者作为其分类的类标。但是,我们发现在式中,对于每个样本的后验概率的计算来说,其都有相同的分母。因此,式可进一步简化为
注意:的含义是,使得取最大值时的取值
虽然朴素贝叶斯算法看似做了一个及其简单的假设,但是其在实际的运用过程中却都有着不错的效果,尤其是在文档分类和垃圾邮件分类场景下仅需要少量数据集就能获得不错的效果[1]。
6.1.3计算示例
通过6.1.2节内容的介绍, 朴素贝叶斯算法的整个原理过程就算是介绍完了。下面再来通过一个实际的计算示例来体会一下朴素贝叶斯分类器的计算流程。
如表6-1所示为一个信用卡审批数据集,其中表示有无工作,表示是否有房,表示学历等级,表示是否审批通过的类标记。试由表6-1中的训练集学习一个朴素贝叶斯分类器,并确定的类标记。
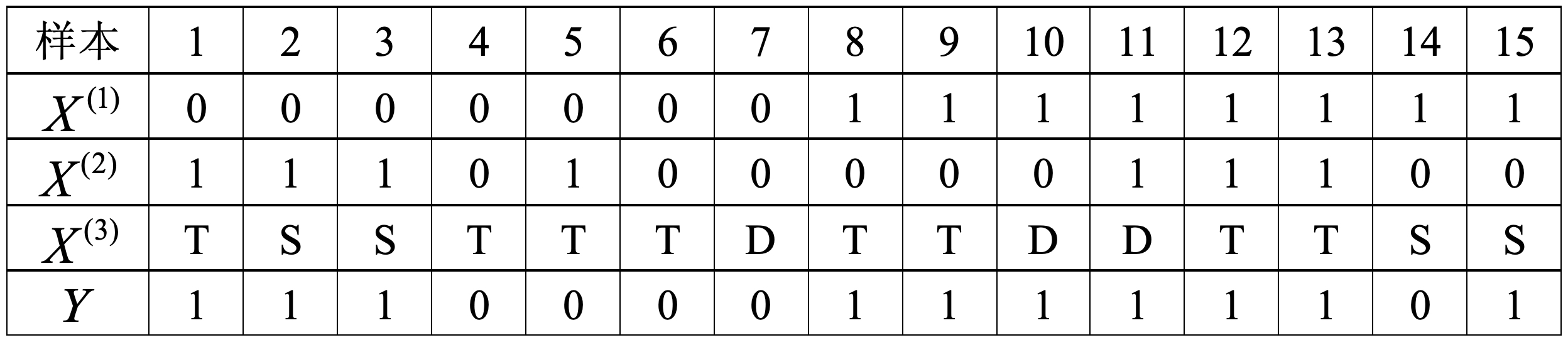
根据式,由表6-1易知,各个类别的先验概率为
条件概率为
以上计算过程便是根据训练集训练朴素贝叶斯分类器模型参数的过程。根据这些参数,便可以对给定的进行预测。
首先根据式分别计算出其属于各个类别的后验概率为
于是便可以知道,样本属于的可能性最大。
6.1.4 求解步骤
根据上面两节的介绍,可以将朴素贝叶斯分类算法的求解步骤总结如下:
输入:训练数据,其中,是第个样本的第维特征,,是第维特征可能取得的第个值。同时,,,;以及实例;
输出:实例的分类[2]。
1) 计算先验概率与条件概率
根据极大似然估计,用给定的数据集来计算各类别的先验概率和条件概率。
其中指示函数,当时输出值为1,反之则为0。
2) 计算各特征取值下的后验概率
3) 极大化后验概率确定类别
到此,对于朴素贝叶斯算法的原理及计算过程就介绍完了。根据6.1.4节的介绍可以知道,朴素贝叶斯算法所接受的特征输入都是离散型特征(Discrete Features),也就非连续性的特征取值,例如基于词袋模型的文本特征表示等。因此,对于这部分的示例代码将放在第7章中进行介绍。
6.1.5 小结
在本节中,笔者首先介绍了朴素贝叶斯算法中的几个基本概念;然后详细介绍了朴素贝叶斯算法的原理,知道了“朴素”一词的含义以及为什么可以通过贝叶斯算法来完成分类任务;最后对朴素贝叶斯算法的具体计算流程进行了总结。
6.2 贝叶斯估计
在介绍完6.1节中的内容后算是对朴素贝叶斯算法的原理有了清楚的认识,但还有一个不能忽略的问题就是,当训练集不充分的情况下,某个维度的条件概率缺失时该怎么处理。例如在6.1.3节的示例中,如果条件概率,即训练集中不存在这一情况,而在测试的数据样本中却存在这种情况。如果此时仍旧将这种情况下的条件概率看作是是0,那么在预测的时候将会产生很大的错差。面对这样的情况该怎么办呢?
6.2.1 平滑处理
通常,解决这类问题的一个有效办法就是在各个估计中加入一个平滑项(Smoothing Parameter)。那么,此时先验概率和条件概率的计算方法为
其中表示数据集分类的类别数;表示第维特征的取值情况数;,且当时称为拉普拉斯平滑(Laplace Smoothing),这也是常用的做法。
同时,当时分别称式和为先验概率和条件概率的贝叶斯估计。并且可以发现,当时,就是极大似然估计;
6.2.2 计算示例
接下来,将6.1.3节中的数据用拉普拉斯平滑()再来计算一次。在计算之前我们知道,此时类别数,。
根据式表6-1和式易知,各类别的先验概率分别为
条件概率为
计算出属于各个类别的后验概率为
于是我们同样可以得出,样本属于的可能性最大。
到此,对于朴素贝叶斯算法的原理及计算过程就介绍完了。对于这部分的sklearn示例代码也将在第7章中进行介绍。由于在不同的书中对于一些算法原理有着不同的称谓,这也导致读者在初学翻阅各种资料时候发现一会儿又多了这个概念,一会儿又多了那个概念极为苦恼。不过名称并不太重要,重要的是要知道具体指代的具体东西。如图6-1所示是笔者对遇到的各种“叫法”进行的总结,仅供参考。

6.2.3 小结
在本节中,笔者介绍了如何处理在贝叶斯算法中条件概率为0时的处理方法,即贝叶斯估计;然后也辨析了几个在贝叶斯算法中容易混淆的概念。值得一提的是,其实平滑处理这种做法不仅仅可以用于此处,在其它任何类似的情况中都可以借鉴这种做法。例如在下一章将要介绍的TF-IDF中同样也会用到。亦或是编写含有除运算的程序中,为了防止分母出现零的情况,都可以采用这样的做法。
总结一下,在本章中笔者首先介绍了朴素贝叶斯算法中的几个基本概念,包括先验概率、后验概率、极大后验概率和极大似然估计等,因为只有在对这些概率有了感性的认识才更加有利于对后续算法原理的理解;接着笔者介绍了朴素贝叶斯算法的基本原理,并且还以一个真实的示例对整个算法计算过程进行了演示;然后介绍了以平滑处理的方式来处理贝叶斯算法中可能存在的条件概率为0的情况,即贝叶斯估计;最后还对贝叶斯算法中几种常见的算法名称进行了总结。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加笔者微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1]Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
[2]李航,统计机器学习,清华大学出版社
推荐阅读
[2] 第2章 从零认识线性回归(附高清PDF与教学PPT)
[3] 第3章 从零认识逻辑回归(附高清PDF与教学PPT)
[4] 第4章 模型的改善与泛化(附高清PDF与教学PPT)