各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
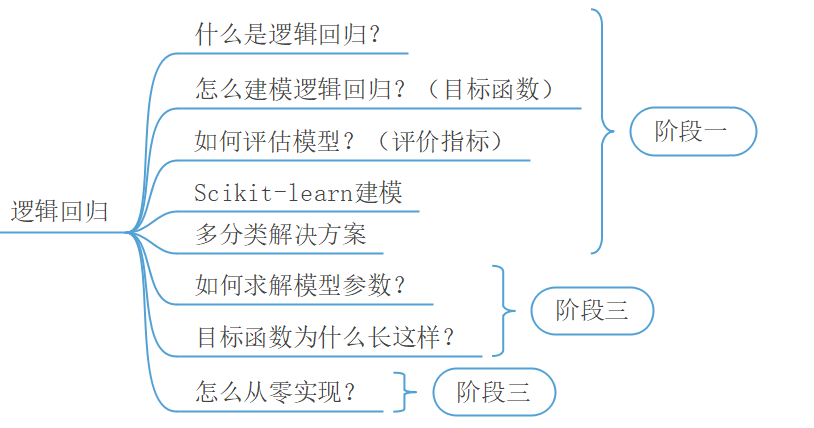
在第2章中,笔者详细的介绍了线性回归模型,那么本章开始将继续介绍下一个经典的机器学习算法逻辑回归(Logistics Regression)。如图3-1所示为逻辑回归模型学习的大致路线,其同样也分为三个阶段。在第一个阶段结束后,我们也就大致掌握了逻辑回归的基本原理。下面就开始正式进入逻辑回归模型的学习。
以下所有完整实现代码(包括作图)均可从仓库 https://github.com/moon-hotel/MachineLearningWithMe 中获取!公众号后台回复“跟我一起机器学习”即可获得本文高清PDF内容与教学PPT!
3.1模型的建立与求解3.1.1理解逻辑回归模型3.1.2建立逻辑回归模型3.1.3求解逻辑回归模型3.1.4逻辑回归示例代码3.1.5小结3.2多变量与多分类3.2.1多变量逻辑回归3.2.2多分类逻辑回归3.2.3多分类示例代码3.2.4小结3.3常见的分类评估指标3.3.1二分类场景3.3.2二分类指标示例代码3.3.3多分类场景3.3.4多分类指标示例代码3.3.5小结3.4目标函数推导3.4.1映射函数3.4.2概率表示3.4.3极大似然估计3.4.4求解梯度3.4.5从零实现二分类逻辑回归3.4.6从零实现多分类逻辑回归3.4.7小结引用
3.1模型的建立与求解
3.1.1理解逻辑回归模型
通常来讲,一个新算法的诞生要么用来改善已有的算法模型,要么就是首次提出用来解决一个新的问题。而逻辑回归模型恰恰属于后者,它是用来解决一类新的问题——分类(Classification)。那什么又是分类问题呢?
现在有两堆样本点,需要建立一个模型来对新输入的样本进行预测,判断其应该属于那个类别,即二分类问题(Binary Classification),如图3-2所示。
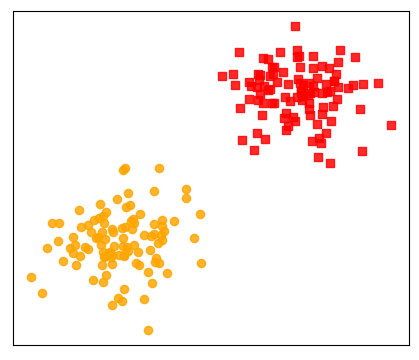
对于这个问题的描述用线性回归来解决肯定是不行的,因为两者本就属于不同类型的问题。退一步讲,即使是用线性回归来建模得到的估计也就是一条向右倾斜的直线,而我们这里需要的却是一条向左倾斜的且位于两堆样本点之间的直线。同时,回归模型的预测值都位于预测曲的线附近,而无法做到区分直线两边的东西。那既然用已有的线性回归解决不了,那我们可不可以在此基础上做一点改进以实现分类的目的呢?答案是当然可以。
3.1.2建立逻辑回归模型
既然是解决分类问题,那么完全可以通过建立一个模型用来预测每个样本点属于其中一个类别的概率,如果那我们就可以认为该样本点属于这个类别,这样就能解决上述的二分类问题。可该怎么建立这个模型呢?
在前面的线性回归中,通过建模来对新样本进行预测,其输出值为可能的任意实数。但此处既然是要得到一个样本所属类别的概率,那最直接的办法就是通过一个函数,将映射至[0,1]的范围即可。由此,便得到了逻辑回归中的预测模型
其中为未知参数;称为假设函数(Hypothesis)。当大于某个值(通常设为0.5)时,便可以认为样本属于正类,反之则认为属于负类。同时,也将称为两个类别间的决策边界(Decision Boundary)。当求解得到后,也就意味着得到了这个分类模型。
注意:回归模型一般来说都是指对连续值进行预测的一类模型,而分类模型都是指对离散值(类标)预测的一类模型。但是由于历史的原因虽然逻辑回归被称为回归,但它却是一个分类模型,这算是一个例外。
3.1.3求解逻辑回归模型
当建立好模型之后就需要找到一种方法来求解模型中的未知参数。同线性回归一样,此时也需要通过一种间接的方式,即通过目标函数来刻画预测标签(Label)与真实标签之间的差距。当最小化目标函数后,便能得到需要求解的参数。
同样,笔者先给出逻辑回归中的目标函数(第二阶段再讲来历):
其中,表示样本总数,表示第个样本,表示第个样本的真实标签,表示第个样本为正类的预测概率。
由式可以知道,当函数取得最小值的参数,就是我们要求的目标参数。原因在于,当取得最小值时就意味着此时所有样本的预测标签与真实标签之间的差距最小,这同时也是最小化目标函数的意义。因此,对于如何求解模型的问题就转化为了如何最小化目标函数的问题。
至此,对逻辑回归算法第一阶段核心内容的学习也就只差一步之遥了,那就是评价指标以及通过开源的框架来建模并进行预测。
3.1.4逻辑回归示例代码
首先,为了便于后续的可视化过程以及了解分类的实质,笔者这里首先采用人为的方式来构造一个数据集进行模型的训练;然后再通过sklearn中的LogisticRegression来完成模型的求解。完整代码见Chapter03/01_decision_boundary.py文件。
1) 构造数据集
这里需要用到sklearn中的make_blobs方法来构造数据集,代码如下:
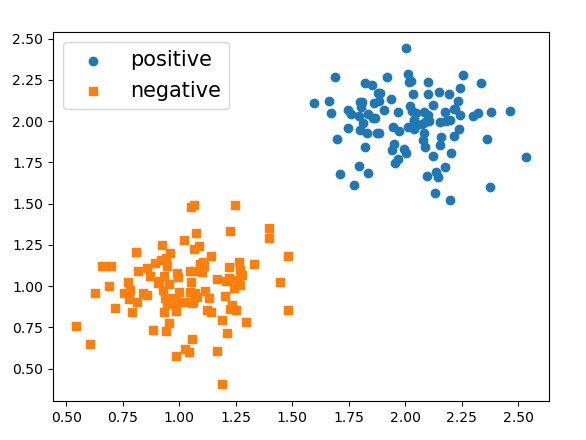
xxxxxxxxxx811 from sklearn.datasets import make_blobs22 def make_data():33 centers = [[1, 1], [2, 2]] # 指定中心44 x, y = make_blobs(n_samples=200, centers=centers,55 cluster_std=0.2, random_state=np.random.seed(10))66 index_pos, index_neg = (y == 1), (y == 0)77 x_pos, x_neg = x[index_pos], x[index_neg]88 return x, y 在上述代码中,第2行用来指定生成两个样本堆的中心;第3-4行则是根据指定的中心点生成两个不同类别的样本堆,其中n_samples表示样本的数量,cluster_std表示样本间的标准差(值越小样本点分布越集中),random_state表示用来指定一个固定的随机种子,以使得每次产生相同的样本点。
在这之后,就能生成一个数据集,如图3-3所示。
2) 训练模型
接着通过LogisticRegression来完成模型的训练和预测,代码如下:
xxxxxxxxxx711 from sklearn.linear_model import LogisticRegression22 def decision_boundary(x, y):33 model = LogisticRegression()44 model.fit(x, y)55 pred = model.predict([[1, 0.5], [3, 1.5]])66 print("样本点(1,0.5)所属的类标为{}\n"77 "样本点(3,1.5)所属的类标为{}".format(pred[0], pred[1]))在完成模型的训练之后,便可以绘制出模型所训练得到的决策面,用于样本点的分类,如图3-4所示。
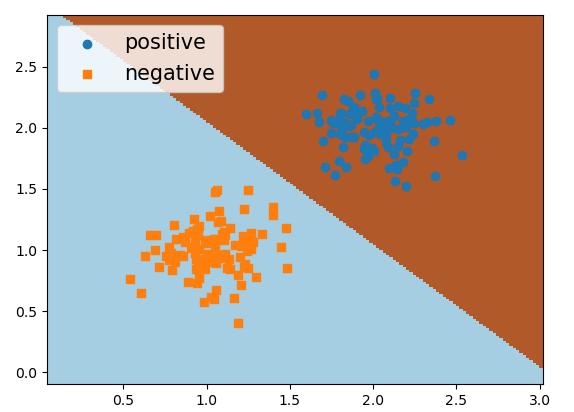
3.1.5小结
在本节中,笔者首先通过一个例子引入了什么是分类,然后介绍了为什么不能用线性回归模型进行建模的原因;其次,通过对线性回归的改进得到逻辑回归模型,并直接的给出了逻辑回归模型的目标函数;最后通过开源的sklearn框架搭建了一个简单的逻辑回归模型,并对决策面进行了可视化。虽然内容不多,也不复杂但却包含了逻辑回归算法的核心思想。同时,余下的内容也会在后续的章节中进行介绍。
3.2多变量与多分类
3.2.1多变量逻辑回归
如同多变量线性回归一样,所谓多变量逻辑回归其实就是一个样本点有多个特征属性,然后通过建立一个多变量的逻辑回归模型来完成分类的任务。实际上在现实情况中,几乎没有一个模型是单变量的,即每个样本点都有多个特征。由于这是刚入门学习的第2个机器学习算法,所以在这里再对多变量进行一次说明。在后续的算法介绍中,将不再单独提及“多变量模型”这一叫法,所有模型的输入都是一个向量(Vector)。
如式所示便为一个多变量逻辑回归模型的假设函数,其后续的所有步骤(求解、预测等)并没有任何的变化与不同,仅仅只是有了更多的特征属性。
3.2.2多分类逻辑回归
在3.1节中对于逻辑回归的介绍都仅仅局限在二分类任务中。但是在实际任务里,更多则是多分类的任务场景,也就是说最终的分类结果中类别数会大于2。那对于这样的问题该如何解决呢?
通常情况下在用逻辑回归处理多分类任务时,都会采样一种称为One-vs-all(也叫做 One-vs-rest)的方法,两者的缩写分别为'ova'与'ovr'。这种策略的核心思想就是每次将其中一个类和剩余其他的类看作是一个二分类任务进行训练,最后在预测过程中选择输出概率值最大那个类标作为该样本点所属的类别。
如图3-5所示为一个可视化的数据集,它一共包含有3个类别。
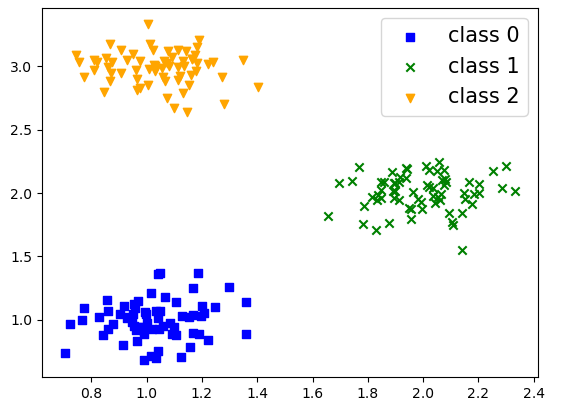
当利用One-vs-all的分类思想来解决图3-5中的多分类问题时,可以将可视化成如图3-6所示的情况。
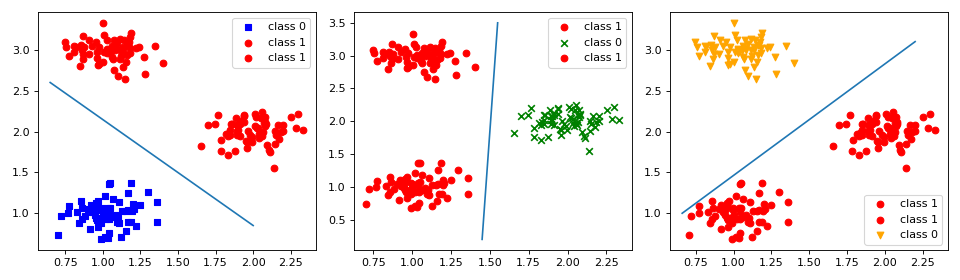
在图3-6中,以从左往右的划分方式划分数据集;然后分别训练3个二分类的逻辑回归模型、和,分别表示样本属于第0,1,2三个类别的概率;最后在预测的时候只要选择概率最大时分类模型所对应的类别即可。
3.2.3多分类示例代码
在sklearn中,可以借助LogisticRegression类中的multi_class='ovr'参数来完成整个多分类的建模任务,完整代码见Chapter03/02_one_vs_all_train.py文件。
1) 载入数据集
在这里,笔者同样也使用sklearn中内置的一个分类数据集iris来进行示例。首先需要载入这个数据集,代码如下:
xxxxxxxxxx511 from sklearn.datasets import load_iris22 def load_data():33 data = load_iris()44 x, y = data.data, data.target55 return x, yiris数据集一共包含有3个类别,每个类别中有50个样本,并且每个样本的有4个特征维度。同时,sklearn中也内置了很多丰富的其它数据集来方便初学者使用,具体信息可以参见官网[1]。
2) 训练模型
在数据集载入完成后,便可以通过sklearn中的LogisticRegression来完成整个建模求解过程,代码如下:
xxxxxxxxxx511 def train(x, y): 22 model = LogisticRegression(multi_class='ovr')33 model.fit(x,y)44 print("得分: ", model.score(x, y))55 # 得分:0.95到此,对于多变量逻辑回归的分类方法与建模过程就介绍完了。不过细心的读者可能发现,上面代码中的最后一行输出了一个0.95的得分,它表示什么含义呢?这里的0.95其实指的模型分类的准确率,意思是指有95%的样本都被模型分类正确了,具体计算原理可见3.3节内容。
3.2.4小结
在本节内容中,笔者首先介绍了什么是多变量逻辑回归,同时还提到对于“多变量”这个说法在以后均不会刻意提及,因为在现实中几乎不存在一个只包含一个变量的任务场景;其次,笔者还以图示的方式介绍了如何用One-vs-all的思想来用逻辑回归模型解决多分类的任务场景;最后,借助开源库skleanr也完成了整个建模过程的示例。接下来,我们将开始学习分类模型中的常见评估指标。
3.3常见的分类评估指标
如同回归模型一样,对于任何分类模型来讲同样需要通过一些评价指标来衡量模型的优与劣。在分类任务中,常见的评价指标有:准确率(Accuracy)、精确率(Precision)、召回率(Recall)与值(),其中应用最为广泛的就是准确率,接着是召回率。为了能够使读者更容易的理解与运用这4种评价指标,下面笔者将会由浅入深地从二分类到多分类的场景来对这4种指标进行介绍。
3.3.1二分类场景
首先以一个猫狗图片识别的任务场景为例,假设现在有一个猫狗图片分类器对100张图片进行分类,分类结果显示有38张图片是猫,62张图片是狗。经过与真实标签对比后发现,38张猫的图片中有20张是分类正确的,62张狗的图片中有57张是分类正确的。
根据上述这一情景,便能得到一张如下图3-7所示的矩阵,称之为混淆矩阵(Confusion Matrix)。
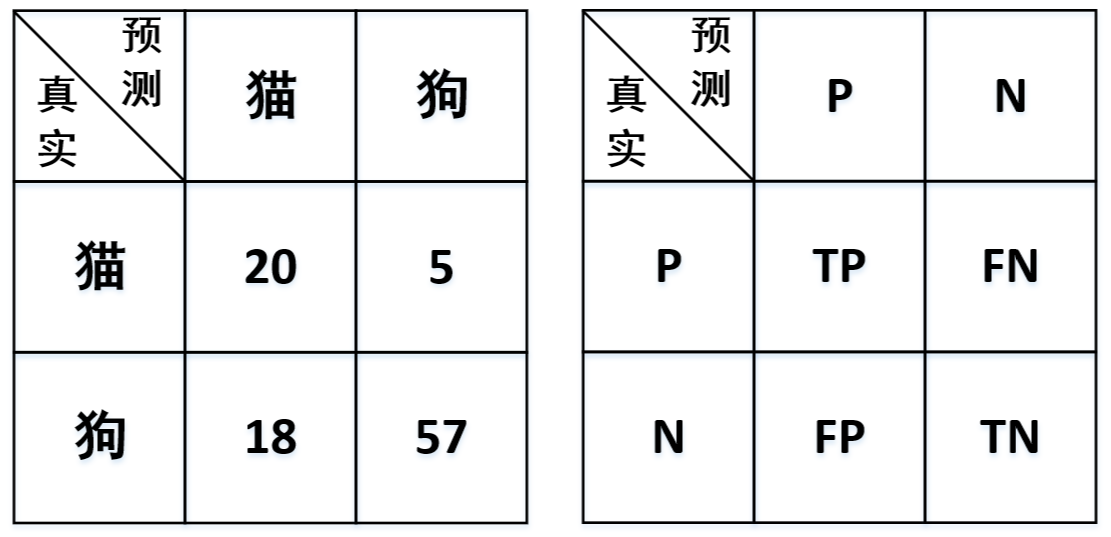
如何来读这个混淆矩阵呢?读的时候首先横向看,然后再纵向看。例如读TP的时候,首先横向表示真实的正样本,其次是纵向表示预测的正样本,因此TP表示的就是将正样本预测为正样本的个数,即预测正确。因此,同理有
- True Positive(TP):表示将正样本预测为正样本,即预测正确;
- False Negative(FN):表示将正样本预测为负样本,即预测错误;
- False Positive(FP):表示将负样本预测为正样本,即预测错误;
- True Negative(TN):表示将负样本预测为负样本,即预测正确
那如果此时突然问FP表示什么含义,又该怎么迅速的反映出来呢?我们知道FP(False Positive)从字面意思来看表示的是错误的正类,也就是说实际上它并不是正类,而是错误的正类,即实际上为负类。因此,FP表示的就是将负样本预测为正样本的含义。再看一个FN,其字面意思为错误的负类,也就是说实际上它表示的是正类,因此FN的含义就是将正样本预测为负样本。
在定义完上述4个类别的分类情况后就能够定义出各种场景下的计算指标,如式所示。
注意:当中时称为值,同时也是用得最多的评价指标。
可以看出准确率是最容易理解,即所有预测对的数量,除以总的数量。同时还可以看到,精确率计算的是预测对的正样本在整个预测为正样本中的比重,而召回率计算的是预测对的正样本在整个真实正样本中的比重。因此一般来说,召回率越高也就意味着这个模型寻找正样本的能力越强(例如在判断是否为癌细胞的时候,寻找正样本癌细胞的能力就十分重要),而则是精确率与召回率的调和平均。但值得注意的是,通常在绝大多数任务中并不会明确哪一类别是正样本,哪一类别又是负样本,所以对于每个类别来说都可以计算其各项指标(但是准确率只有一个)。
在得到式中各项评价指标的计算公式后,便可以分别计算出3.3.1节一开始的示例场景中,猫狗分类模型的各项评估值。
1) 准确率
2) 值
对于类别猫来说
对于类别狗来说
到这里,对于4种指标各自的原理以及计算方式就算是介绍完了。但是如果要来衡量整体的精确率与召回率或者是值又该怎么处理呢?对于分类结果整体的评估值,常见的做法有两种:第一种是取算术平均;第二种是加权平均[2]
1) 算术平均
所谓算术平均也叫做宏平均(Macro Average),也就是等权重的对各类别的评估值进行累加求和。例如对于上述两个类别来说,其精确率、召回率和值分别为
2) 加权平均
所谓加权平均也就是以不同的加权方式来对各类别的评估值进行累加求和。这里只介绍一种用得最多的加权方式,即按照各类别样本数在总样本中的占比来进行加权。对于图3-7中的分类结果来说,加权后的精确率、召回率和值分别为
3.3.2二分类指标示例代码
在弄清分类任务中各项指标的计算原理后,就可以选择其中的一些指标对模型的精度进行评估。从式可知,计算各项评估指标的关键就在于如何从分类结果中构造一个混淆矩阵。对于评估矩阵的构造,这里可以借助sklearn中提供的confusion_matrix方法来进行实现。完整代码见Chapter03/03_confusion_matrix.py文件。
1) 载入数据集
在这里,同样也使用sklearn中内置的一个分类数据集breast_cancer进行示例。首先需要载入这个数据集,代码如下:
xxxxxxxxxx511 from sklearn.datasets import load_breast_cancer22 def load_data():33 data = load_breast_cancer()44 x, y = data.data, data.target55 return x, ybreast_cancer数据集一共包含有2个类别(正样本与负样本),其中负样本212个,正样本357个,并且每个样本的有30个特征维度。
2) 指标计算
根据前面介绍的计算原理,可以实现各项指标的计算过程,代码如下:
xxxxxxxxxx121 1 def get_acc_rec_pre_f(y_true, y_pred, beta=1.0):2 2 (tn, fp), (fn, tp) = confusion_matrix(y_true, y_pred)3 3 p1, p2 = tp / (tp + fp), tn / (tn + fn) 4 4 r1, r2 = tp / (tp + fn), tn / (tn + fp) 5 5 f_beta1 = (1 + beta ** 2) * p1 * r1 / (beta ** 2 * p1 + r1) 6 6 f_beta2 = (1 + beta ** 2) * p2 * r2 / (beta ** 2 * p2 + r2)7 7 m_p, m_r, m_f = 0.5 * (p1+p2), 0.5 * (r1+r2), 0.5 * (f_beta1 + f_beta2) 8 8 count = np.bincount(y_true)9 9 w1, w2 = count[1]/sum(count), count[0]/sum(count)# 计算加权平均1010 w_p, w_r,w_f=w1 * p1+w2 * p2, w1 * r1+w2 * r2, w1 *f_beta1+w2 * f_beta21111 print(f"算术平均: 精确率:{m_p},召回率:{m_r},F值:{m_f}")1212 print(f"加权平均:精确率:{w_p},召回率:{w_r},F值:{w_f}")在上述代码中,第2行用来构造混淆矩阵;第3-4行分别用来计算两种类别各自的精确率和召回率;第5-6行分别用来计算两种类别的F值;第7行用来计算各个指标的算术平均;第8-10行用来计算各个指标的加权平均。
3) 训练模型
在完成上面两个步骤后,便可以通过LogisticRegression来完成整个建模求解过程,并输出对应的评价指标,代码如下:
xxxxxxxxxx611 def train(x, y):22 model = LogisticRegression()33 model.fit(x, y)44 y_pred = model.predict(x)55 print("准确率: ", model.score(x, y))66 get_acc_rec_pre_f(y, y_pred)经过上述代码后,便能够得到如下所示的评估结果,如下:
xxxxxxxxxx311 准确率: 0.9522 算术平均: 精确率:0.95,召回率:0.94,F值0.9433 加权平均: 精确率:0.95,召回率:0.95,F值0.953.3.3多分类场景
在3.3.1节中,笔者详细的介绍了在二分类场景下各种评价指标的计算方法。但是在现实场情况里更多的便是多分类场景,并且通常也会采用召回率、精确率或者F值来作为评价指标。那此时各个指标又该怎么计算呢?在接下来的这节内容中,笔者将会针对多分类的任务场景来介绍这些指标的计算方法。
假设有如下三分类任务的预测值与真实值,如下代码所示:
xxxxxxxxxx211 y_true = [1, 1, 1, 0, 0, 0, 2, 2, 2, 2]22 y_pred = [1, 0, 0, 0, 2, 1, 0, 0, 2, 2]根据这一结果,便可以得到一个混淆矩阵,如图3-8所示。
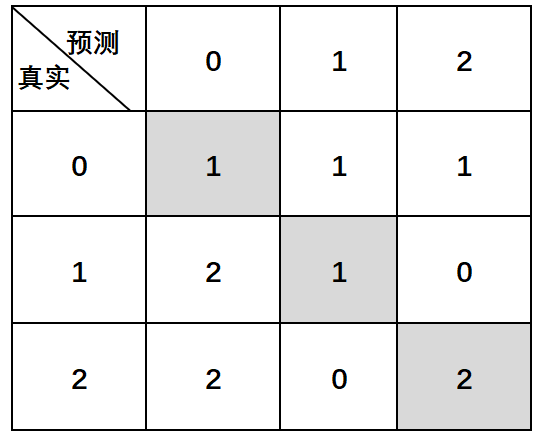
如图3-8所示,由于是多分类所以也就不止正样本和负样本两个类别,那这个表该怎么读呢?方法还是同3.3.1节中的一样,先横向看再纵向看。例如第1行灰色单元格中的1表示的就是将真实值0预测为0的个数(预测正确);接着右边的1表示的就是将真实值0预测为1的个数;第2行灰色单元格中的1表示的就是将真实值1预测为1的个数;第3行灰色单元格中的2表示的就是将真实值2预测为2的个数。也就是说只有这个对角线上的值才表示模型预测正确的样本的数量。接下来就开始对每个类别的各项指标进行一个计算。
1) 对于类别0来说
在上面笔者介绍到,精确率计算的是预测对的正样本在整个预测为正样本中的比重。根据图3-8可知,对于类别0来说,预测对的正样本(类别0)数量为1,而整个预测为正样本的数量为5。因此,类别0对应的精确率为
同时,召回率计算的是预测对的正样本在整个真实正样本中的比重。根据图3-8可知,对于类别0来说,预测对的正样本(类别0)数量为1,而整个真实正样本0的个数为3(图3-8中第2行的3个1)。因此,对于类别0来说其召回率为
因此,其值为
2) 对于类别1来说
对于类别1来说,预测对的正样本(类别1)的数量为1,而整个预测为类别1的样本数量为2。因此,其精确率为
同理,其召回率和值分别为
3) 对于类别2来说
最后,对于三个类别来说其加权后的准确率、召回率和值分别为
(1) 算术平均
(2) 加权平均
3.3.4多分类指标示例代码
对于这部分的代码实现,从上面的计算过程可以发现,最重要的依旧是要计算得到这个混淆矩阵。但是对于多分类任务来说,后续实现代码也略显繁杂,不过各位读者依旧可以仿照第3.3.2节中的代码自己来编码实现。不过这里,我们可以直接借助sklearn中的classification_report模块[2]来完成所有的计算过程,代码如下:
xxxxxxxxxx411 from sklearn.metrics import classification_report22 y_true = [1, 1, 1, 0, 0, 0, 2, 2, 2, 2]33 y_pred = [1, 0, 0, 0, 2, 1, 0, 0, 2, 2]44 print(classification_report(y_true, y_pred))在运行上述代码后,便能得到如下所示的结果:
xxxxxxxxxx711 precision recall f1-score support #分别表示精确、召回率、F值22 0 0.20 0.33 0.25 333 1 0.50 0.33 0.40 344 2 0.67 0.50 0.57 455 accuracy 0.40 10 #模型准确率66 macro avg 0.46 0.39 0.41 10 #算术平均(宏平均)77 weighted avg 0.48 0.40 0.42 10 #加权平均3.3.5小结
在本节中,笔者首先介绍了二分类任务场景下混淆矩阵的构造以及对应的含义;接着介绍了如何通过混淆矩阵来计算分类模型中的各项评估指标;其次是介绍了在多分类任务下混淆矩阵的构造以及对应各项指标的计算方法;最后还通过sklearn中的confusion_matrix和classification_report模块来示例完成了所有的计算过程。接下来让我们开始学习逻辑回归模型中最后两个阶段的内容。
3.4目标函数推导
在前面3节的内容中,笔者详细的介绍了什么是逻辑回归、如何进行多分类、以及分类任务对应的评价指标等,算是完成了前面阶段一的学习。但是到目前为止仍旧有一些问题没有解决,映射函数长什么样?逻辑回归的目标函数怎么来的?如何自己求解实现逻辑回归?只有在这3个问题解决后,整个逻辑回归算法的主要内容才算是学习完了。
3.4.1映射函数
前面笔者只是介绍了通过一个函数将特征的线性组合映射映射到区间[0,1]中去,那么这个长什么样呢?如图3-9所示便是的函数图像,其同时也被称为Sigmoid函数。
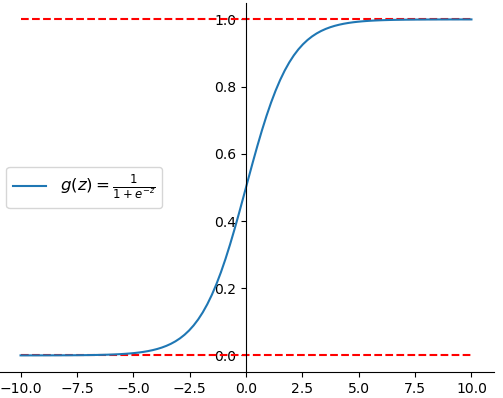
Sigmoid函数的数学定义如下
其中。而之所以选择Sigmoid的原因在于:①其连续光滑且处处可导;②Sigmoid函数关于点中心对称;③Sigmoid函数求导过程简单,其最后的求导结果为。
根据式可以得出其实现代码如下:
xxxxxxxxxx211 def g(z):22 return 1 / (1 + np.exp(-z))
可以看到对于Sigmoid的实现也非常简单,1行代码就能完成。
3.4.2概率表示
在介绍完Sigmoid函数后就需要弄清楚逻辑回归中的目标函数到底是怎么来的。此时,可以设
其中均为一个列向量,的含义为当给定参数时,样本属于这个类别的概率为。此时可以发现,对于每个样本来说都需要前面两个等式来衡量每一个样本所属类别的概率,为了更加方便的表示每个样本所属类别的概率,可以改写为如下形式
这样一来,不管样本属于哪个类别,都可以通过式来进行概率计算。
进一步,我们知道在机器学习中都是通过给定训练集,即来求得其中的未知参数。换句话说,对于每个给定的,我们已经知道了其所属的类别,即的这样一个分布结果我们是知道的。那么什么样的参数能够使得已知的这样一个结果(分布)最容易出现呢?也就是说给定什么样的参数,使得当输入这个样本时,最能够产生已知类别标签这一结果?
3.4.3极大似然估计
上面绕来绕去说了这么多目的就只有一个,即为什么要用似然函数进行下一步的计算。由3.4.2节内容分析可知,为了能够使得这样一个结果最容易出现,应该最大化如下似然函数[3]
对式两边同时取自然对数有
注意:
由于我们的目标是最大化式,也等价于最大化式。因此当式取得最大值时,其所对应的参数就是逻辑回归模型需要求解的参数。由此便得到了逻辑回归算法的目标函数
从式可以发现我们在前面加了一个负号,因此求解逻辑回归的最终目的就变成了最小化式。
3.4.4求解梯度
在求解线性回归中,笔者首次引入并讲解了梯度下降算法,知道可以通过梯度下降算法来最小化某个目标函数。当目标函数取得(或接近)其函数最小值时,我们便得到了目标函数中对应的未知参数。由此可知,欲通过梯度下降算法来最小化函数,则必须先计算得到其关于各个参数的梯度。所以接下来就需要求解得到目标函数关于各个参数的梯度。
目标函数对的梯度为
目标函数对的梯度为
进一步,对式矢量化可得
xxxxxxxxxx311 J(W,b)=-1/m * np.sum(y * np.log(h_x) + (1 - y) * np.log(1 - h_x)) 22 grad_w = (1 / m) * np.matmul(X.T, (h_x - y)) # [n,m] @ [m,1]33 grad_b = (1 / m) * np.sum(h_x - y)3.4.5从零实现二分类逻辑回归
这里依旧以breast_cancer这个二分类数据集为例来建立逻辑回归模型,完整代码见Chapter03/04_implementation.py文件。
1) 预测函数
在实现整个逻辑回归的建模与求解过程前,首先需要完成假设函数和预测函数的编码,代码如下:
xxxxxxxxxx411 def hypothesis(X, W, bias):22 z = np.matmul(X, W) + bias33 h_x = sigmoid(z)44 return h_x如上代码便是假设函数的实现,其中第2行代码是样本和权重的线性组合;第3行代码是通过映射函数将线性组合后的结果映射到[0,1]之间的概率值。接着便是根据一个阈值(这里默认设置为0.5,也可以是其它)将概率值转化未具体对应的类别,代码如下:
xxxxxxxxxx411 def prediction(X, W, bias, thre=0.5):22 h_x = hypothesis(X, W, bias)33 y_pre = (h_x > thre) * 1#将大于阈值的True和False结果转换为1和0的标签结果44 return y_pre2) 目标函数
为了更好的观察目标函数的收敛,同样需要计算每次参数更新后的损失值,具体实现代码如下:
xxxxxxxxxx511 def cost_function(X, y, W, bias):22 m, n = X.shape33 h_x = hypothesis(X, W, bias)44 cost = np.sum(y * np.log(h_x) + (1 - y) * np.log(1 - h_x))55 return -cost / m
3) 梯度下降
为了对整个模型进行求解,因此需要编程实现整个梯度下降的计算过程,代码如下:
xxxxxxxxxx811 def gradient_descent(X, y, W, bias, alpha):22 m, n = X.shape33 h_x = hypothesis(X, W, bias)44 grad_w = (1 / m) * np.matmul(X.T, (h_x - y)) # [n,m] @ [m,1]55 grad_b = (1 / m) * np.sum(h_x - y)66 W = W - alpha * grad_w # 梯度下降77 bias = bias - alpha * grad_b # 梯度下降88 return W, bias在上述代码中,第6-7行便是用来执行梯度下降的过程。
4) 训练模型
在完成上述各个部分函数的实现后便可以用来实现整个模型的训练过程,代码如下:
xxxxxxxxxx911 def train(X, y, ite=200):22 m, n = X.shape # 506,1333 W = np.random.uniform(-0.1, 0.1, n).reshape(n, 1)44 b, alpha, costs = 0.1, 0.08, []55 for i in range(ite):66 costs.append(cost_function(X, y, W, b))77 W, b = gradient_descent(X, y, W, b, alpha)88 y_pre = prediction(X, W, b)99 return costs
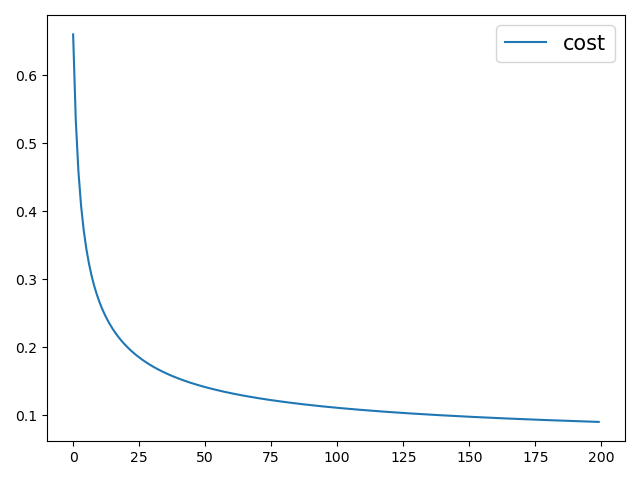
在上述代码中,第2行用来随机初始化权重参数, 然后通过梯度下降来进行迭代更新;第6行用来保存了参数每一次迭代更新后计算出来的损失值,并进行了返回。最后,该模型经过200次的迭代后,准确率能够在0.98左右。
根据返回后的损失值,还能画出整个训练过程中模型的收敛情况,如图3-10所示。
3.4.6从零实现多分类逻辑回归
在3.4.5节内容中,笔者从零开始实现了整个二分类逻辑回归的建模与求解过程。在接下来的这一小节中,笔者将继续介绍如何从零开始实现一个多分类的逻辑回归模型。完整代码见Chapter03/05_implementation_multi_class.py文件。
1) 载入数据集
由于是多分类任务,所以这里使用的是sklearn中的一个3分类数据集iris,具体信息在3.2.6节中已经介绍过,这里就不再赘述,载入代码如下:
xxxxxxxxxx511 from sklearn.datasets import load_iris22 def load_data():33 data = load_iris()44 x, y = data.data, data.target55 return x, y2) 定义二分类器
根据3.2.2节的内容可知,One-vs-all的本质就是训练多个二分类器,然后用每一个二分类器来对样本进行分类。因此这里需要定义一个函数来完成二分类器的训练,最后通过多次调用这个函数来实现多个二分类模型的训练,代码如下:
xxxxxxxxxx811 def train_binary(X, y, iter=200):22 m, n = X.shape # 506,1333 W = np.random.randn(n, 1)44 b,alpha,costs = 0.3,0.5,[]55 for i in range(iter):66 costs.append(cost_function(X, y, W, b))77 W, b = gradient_descent(X, y, W, b, alpha)88 return costs, W, b从上述代码可以看出,其整体上同3.4.5中训练模型部分的代码一致,只是这里还额外的返回了训练好的参数。
3) 训练多分类模型
在完成上述两部分的代码后就可以进行整个多分类模型的训练了,代码如下:
xxxxxxxxxx121 1 def train(x, y, iter=1000):2 2 class_type = np.unique(y)3 3 costs, W, b = [], [], []4 4 for c in class_type: 5 5 label = (y == c) * 16 6 tmp = train_binary(x, label, iter=iter)7 7 costs.append(tmp[0]) 8 8 W.append(tmp[1]) 9 9 b.append(tmp[2])1010 y_pre = prediction(x, W, b)1111 print(classification_report(y, y_pre))1212 return costs在上述代码中,第2行用来判断数据集中一共有多少个类别,即需要训练多少个二分类器;第4行用来循环训练多个二分类器;第7-9行用来记录每个模型训练后的损失值和对应的权重参数。待整个模型训练完成后,便能够得到如图3-11所示的模型收敛图。
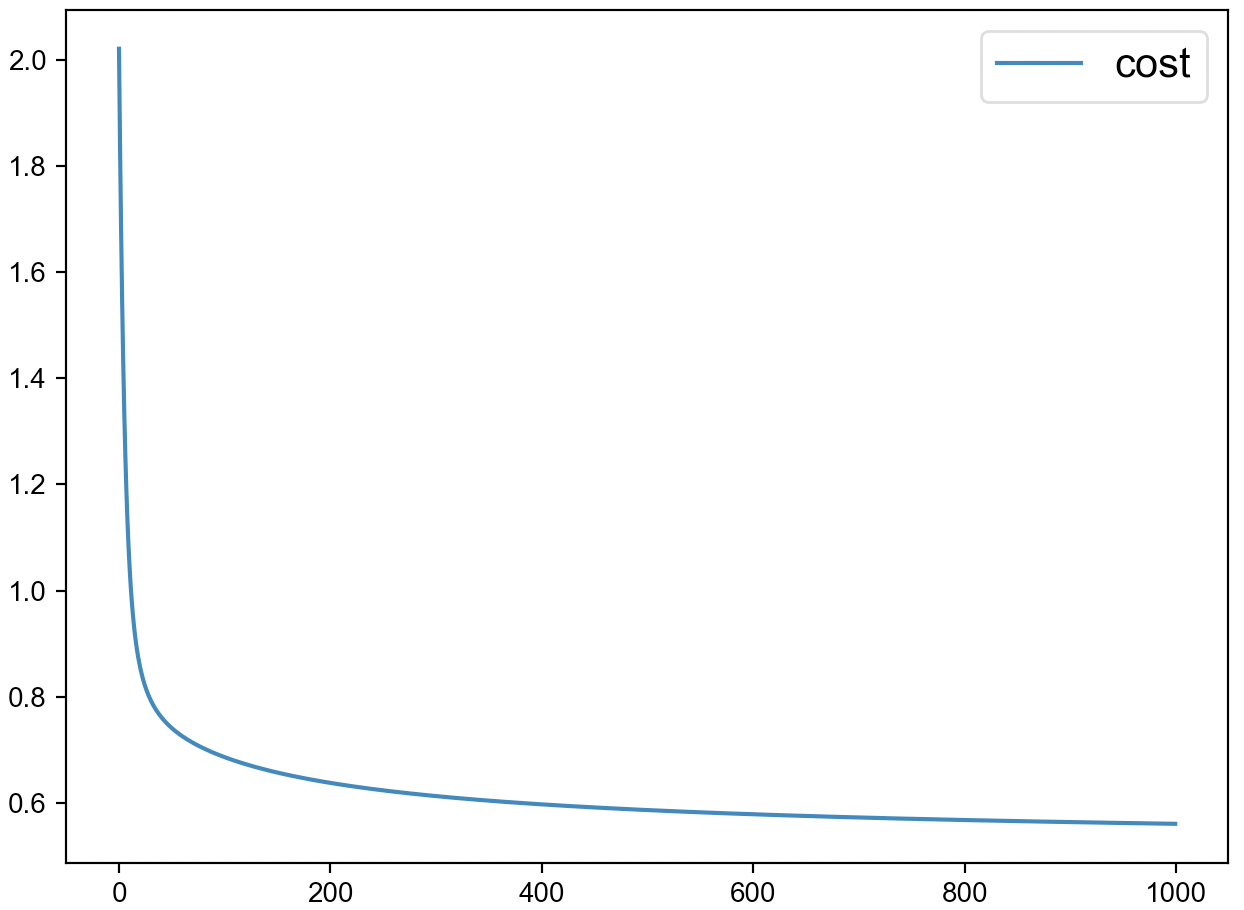
从图3-11可以看出,整个模型大约在第400次迭代后就进入了收敛状态,最终也得到了0.96的准确率。
公众号后台回复“跟我一起机器学习”即可获得本文高清PDF内容与教学PPT!
3.4.7小结
在本节中,笔者首先介绍了逻辑回归中的映射函数(即Sigmoid函数)和样本分类时的概率表示;接着介绍了如何通过极大似然估计来推导得到逻辑回归模型的目标函数;然后介绍了如何根据得到的目标函数来推导各个参数关于目标函数的梯度;最后,分别从零开始介绍了如何实现二分类模型和多分类逻辑回归模型。
总结一下,如图3-12所示,在本章中笔者首先通过一个示例引入了什么是分类模型,并通过在线性回归的基础上一步步的引出了什么是逻辑回归模型;然后笔者介绍了逻辑回归从建模到利用开源库进行求解的整个过程;接着介绍了如何通过逻辑回归来完成多分类任务以及分类任务中常见的4种评价指标,并完成了阶段一的学习。最后,笔者通过本节的内容详细介绍了逻辑回归算法目标函的推导以及梯度的迭代公式等,还动手从零开始实现了逻辑回归的分类代码,进一步完成了后面两个阶段的学习。到此,对于逻辑回归的主要内容也就介绍完毕了。
不过尽管如此,仍旧还有一些提升模型性能的方法(例如数据集划分、正则化等)没有阐述,这些内容笔者将在第4章中进行详细的介绍。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加笔者微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1]https://scikit-learn.org/stable.
[2]Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
[3]Andrew Ng, Machine Learning, Stanford University, CS229, Spring 2019.
[4]示例代码 https://github.com/moon-hotel/MachineLearningWithMe