1 决策树的基本思想1.1 冠军球队1.2 信息的度量1.3 小结2 决策树的生成之ID3与C4.52.1 基本概念与定义2) 条件熵2.2 计算示例2.3 ID3生成算法2.4 C4.5生成算法2.5 特征划分2.6 小结3 决策树生成与可视化3.1 ID3算法示例代码3.2 决策树可视化3.3 小结4 决策树剪枝4.1剪枝思想4.2 剪枝步骤4.3 剪枝示例4.4 小结引用推荐阅读
各位客官大家好,欢迎来到月来客栈,我是掌柜空字符。
经过前面几个章节的介绍,我们已经学习过了3个分类算法模型,包括逻辑回归、K近邻和朴素贝叶斯。今天掌柜将开始介绍下一个分类算法模型决策树(Decision Tree)。
1 决策树的基本思想
一说到决策树其实很读者或多或少都已经使用过,只是自己还不知道罢了。例如最简单的决策树就是通过输入年龄,判读其是否为成年人,即if age >= 18 return True,想想自己是不是经常用到这样的语句?
1.1 冠军球队
关于什么是决策树,我们先来看这么一个例子。假如掌柜错过了某次世界杯比赛,赛后掌柜问一个知道比赛结果的人“哪支球队是冠军”?但是对方并不愿意直接说出结果,而是让掌柜自己猜,且每猜一次对方都要收一元钱才肯告诉掌柜是否猜对了。那现在的问题是要掏多少钱才能知道谁是冠军球队呢[1]?
现在我可以把球队从1到16编上号,然后提问:“冠军球队在1-8号中吗?”。假如对方告诉我猜对了,掌柜就会接着问:“冠军在1-4号中吗?”。假如对方告诉我猜错了,那么掌柜也就自然知道冠军在5-8号中。这样只需要4次,掌柜就能知道哪支球队是冠军。上述过程背后所隐藏着的其实就是决策树的基本思想,并且还可以用更为直观的图来展示上述的过程,如图8-1所示。
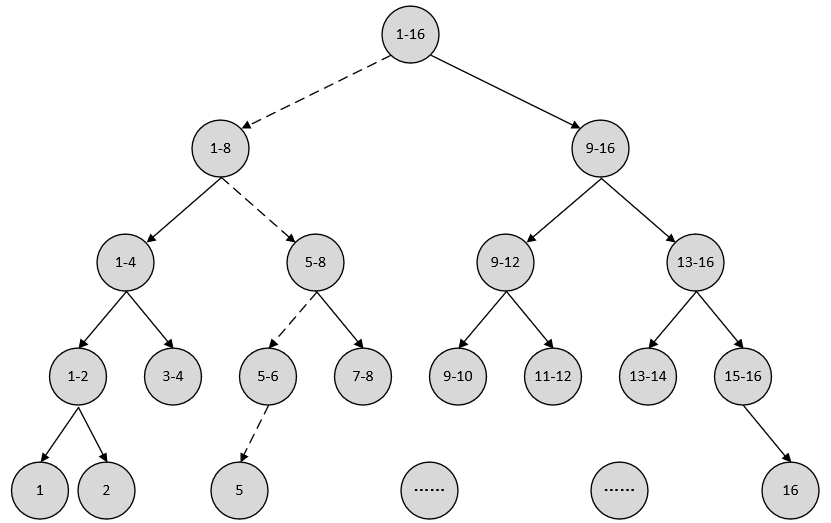
由此可以得出,决策树每一步的决策过程就是降低信息不确定性的过程,甚至还可以将这些决策看成是一个if-then的规则集合。如图8-1所示,冠军球队一开始有16种可能性,经过一次决策后变成了8种。这意味着每次决策都能得到更多确定的信息,而减少更多的不确定性。
不过现在的问题是,为什么要像图8-1这样来划分球队?对于熟悉足球的读者来说,这样的决策树似乎略显多余。因为事实上只有少数几支球队才有夺冠的希望,而大多数是没有的。因此,一种改进做法就是在一开始的时候就将几个热门的可能夺冠的球队分在一边,将剩余的放在另一边,这样就可以大大提高整个决策过程的效率。
例如最有可能夺冠的是1,2,3,4这4个球队,而其余球队夺冠的可能性远远小于这4个。那么一开始就可以将球队分成1-4和5-16。如果冠军是在1-4中,那么后面很快就能知道谁是冠军。退一万步,假如冠军真的是在5-16,那么接下来你同样可以按照类似的思路将剩余的球队划分成最有可能夺冠和最不可能夺冠这两个部分。这样也能快速的找出谁是冠军球队。
于是这时候可以发现,如何划分球队变成了建立这棵决策树的关键。如果存在一种划分,能够使得数据的“不确定性”减少得越多(谁不可能夺冠),也就意味着该划分能获取更多的信息,而我们也就更倾向于采取这样的划分。因此采用不同的划分就会得到不同的决策树。所以,现在的问题就变成了如何构建一棵“好”的决策树呢?要想回答这个问题,先来解决如何描述“信息”这个问题。
1.2 信息的度量
关于如何定量的来描述信息,几千年来都没有人给出很好的解答。直到1948年,香农在他著名的论文“通信的数学原理”中提出了信息熵(Information Entropy)的概念,这才解决了信息的度量问题,并且还量化出了信息的作用。
1) 信息熵
一条信息的信息量与其不确定性有着直接的关系。比如说,要搞清楚一件非常非常不确定的事,就需要了解大量的信息。相反,如果已经对某件事了解较多,则不需要太多的信息就能把它搞清楚。所以从这个角度来看可以认为,信息量就等于不确定性的多少。我们经常说,一句话包含有多少信息,其实就是指它不确定性的多与少。
于是,8.1.1节中第一种划分方式的不确定性(信息量)就等于“4块钱”,因为掌柜花4块钱就可以解决这个不确定性。当然,香农用的不是钱,而是用“比特”(Bit)这个概念来度量信息量,一个字节就是8比特。在上面的第一种情况中,“谁是冠军”这条消息的信息量就是4比特。那4比特是怎么计算来的呢?第二种情况的信息量又是多少呢?
香农指出,它的准确信息量应该是
其中
对于任意一个随机变量
其中
例如在二分类问题中:设
根据式还
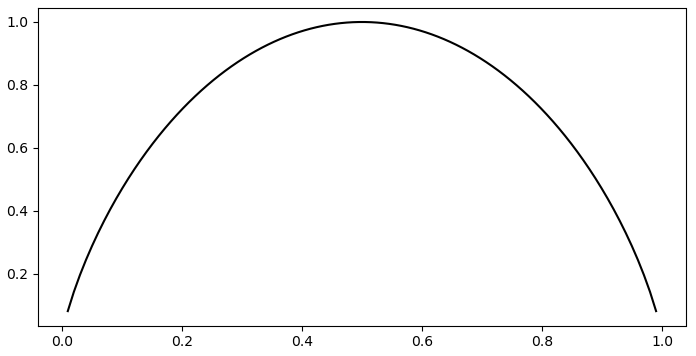
从图8-2可以发现,当两种情况发生的概率均等(
2) 条件熵
在谈条件熵(Condition Entropy)之前,我们先来看看信息的作用。一个事物(那只球队会得冠),其内部会存有随机性也就是不确定性,假定其为
到此,对于条件熵相信读者朋友们在感性上已经有了一定的认识。至于具体的数学定义将在决策树生成部分进行介绍。
3) 信息增益
在8.1.1节中掌柜介绍到,若一种划分能使数据的“不确定性”减少得越多,也就意味着该种划分能获取更多的信息,而我们也就更倾向于采取这样的划分。也是就说,存在某个事物
综上所述,采用不同的划分就会得到不同的决策树,而我们所希望得到的就是在每一次划分的时候都采取最优的方式,即局部最优解。这样每一步划分都能够使得当前的信息增益达到最大。因此可以得出,构建决策树的核心思想就是每次划分时,要选择使得信息增益达到最大时的划分方式,以此来递归构建决策树。
1.3 小结
在本节中,掌柜首先介绍了决策树的核心思想,即决策树的本质就是降低信息不确定性的过程;然后总结出构建一棵决策树的关键在于找到一种合适的划分,使得信息的“不确定性”能够降低得最多;最后掌柜介绍了如何以量化的方式来对信息进行度量。
2 决策树的生成之ID3与C4.5
在正式介绍决策树的生成算法前,掌柜先将8.1.1节中介绍的几个概念重新梳理一下;并且同时再通过一个例子来熟悉一下计算过程,以便于后续更好的理解决策树的生成算法。
2.1 基本概念与定义
1) 信息熵
设
其中,若
2) 条件熵
设有随机变量
其中,
同时,当信息熵和条件熵中的概率由样本数据估计(特别是极大似然估计)得到时,所对应的信息熵与条件熵分别称之为经验熵(Empirical Entropy)和经验条件熵(Empirical Conditional Entropy)。这里暂时看不懂没关系,请结合后续计算示例。
3) 信息增益
从8.1.1节的内容可知,所谓信息增益指的就是事物
定义:设训练集为
数据集
从式
数据集
从式
信息增益为
2.2 计算示例
如果仅看上面的公式肯定会不那么容易理解,下面掌柜再进行举例说明(将上面的公式同下面的计算过程对比看会更容易理解)。下表8-1同样是6.1.3节中用过的一个信用卡审批数据集,其一共包含15个样本和3个特征维度。其中特征
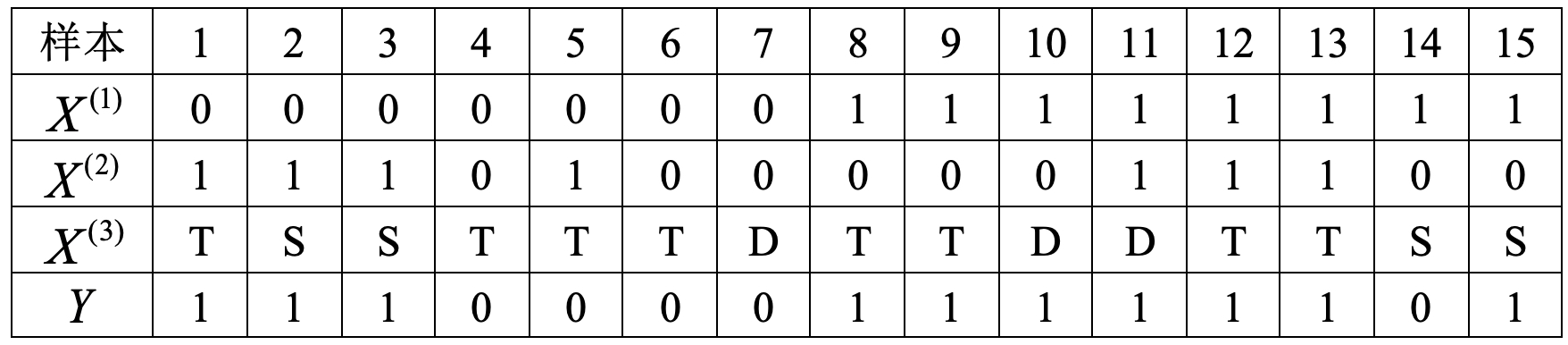
1) 计算信息熵
根据式
2) 计算条件熵
由表8-1可知,数据集有3个特征(工作、房子、学历)
已知外部信息“工作”的情况下有
式
已知外部信息“房子”的情况下有
式
已知外部信息“学历”的情况下有
式
3) 计算信息增益
根据上面的计算结果便可以计算得到各特征划分下的信息增益为
到目前为止,我们已经知道了在生成决策树的过程中所需要计算的关键步骤信息增益,接下来,掌柜就开始正式介绍如何生成一棵决策树。
2.3 ID3生成算法
在8.1节的末尾掌柜总结到,构建决策树的核心思想就是:每次划分时,要选择使得信息增益最大的划分方式,以此来递归构建决策树。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征没有分类能力。因此,对于决策树生成的一个关键步骤就是选取对训练数据具有分类能力的特征,这样可以提高决策树学习的效率,而通常对于特征选择的准则就是8.1节谈到的信息增益。
ID3(Interactive Dichotomizer-3)算法的核心思想是在选择决策树的各个节点时,采用信息增益来作为特征选择的标准,从而递归地构建决策树。其过程可以概括为,从根节点开始计算所有可能划分情况下的信息增益;然后选择信息增益最大的特征作为划分特征,由该特征的不同取值建立子节点;最后对子节点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有可以选择为止。例如根据8.2.2节最后的计算结果可知,首先应该将数据样本以特征
生成步骤
输入:训练数据集
输出:决策树[2]。
(1) 若
(2) 若
(3) 否则,计算
(4) 如果
(5) 否则,对
(6) 对于第
生成示例
下面就用ID3算法来对表8-1中的数据样本进行决策树生成示例。易知该数据集不满足步骤(1)(2)中的条件,所以开始执行步骤(3)。同时,根据8.2.2小节最后的计算结果可知,对于特征
由于本例中未设置阈值,所以接着执行步骤(5)按照
表8-2 第一次划分表 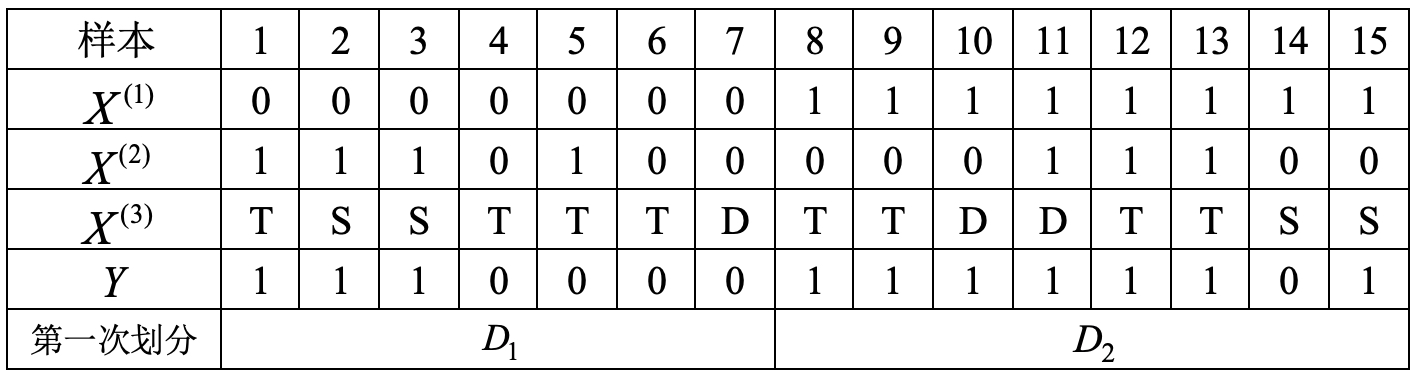
接着开始执行步骤(6),由于
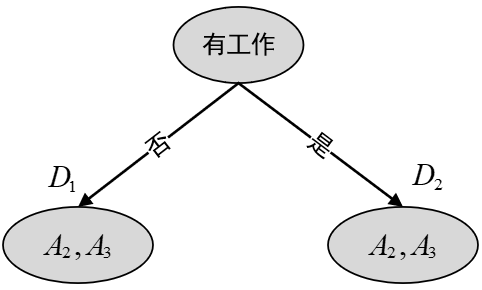
图8-3 第一次划分 此时,对于子集
1) 计算信息熵
2) 计算条件熵
根据式
同理,对于子集
1) 计算信息熵
2) 计算条件熵
3) 信息增益
根据式
到此,根据上述计算过程,便可以得到第二次划分后的结果,如表8-3所示。
表8-3 第二次划分表 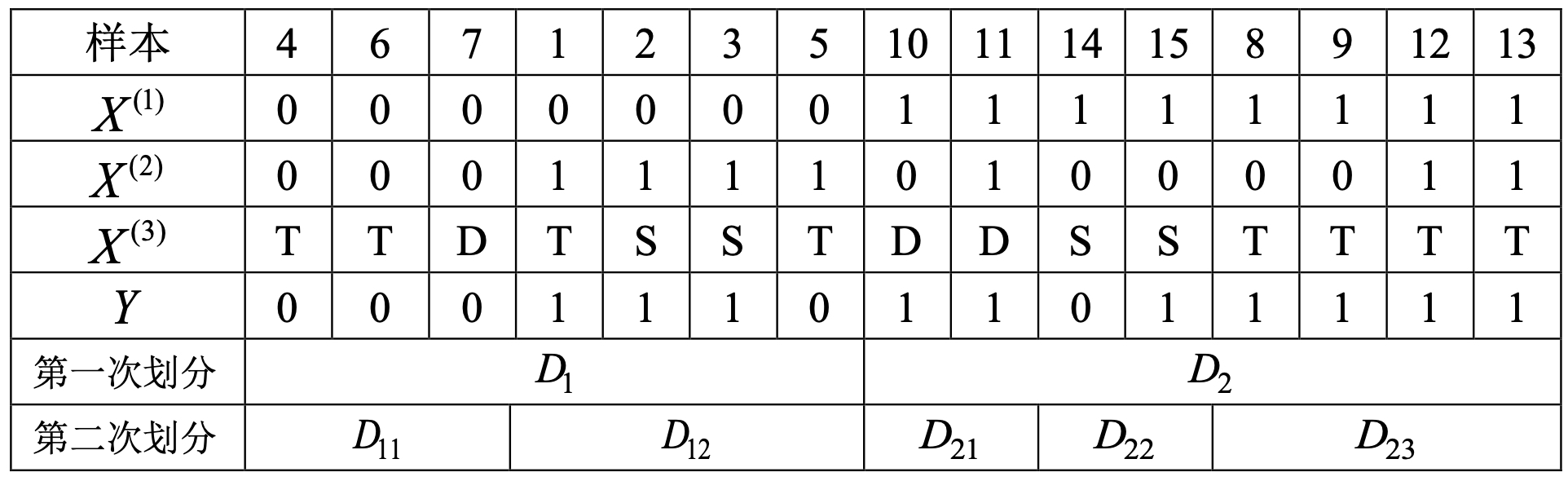
从表8-3中的结果可知,
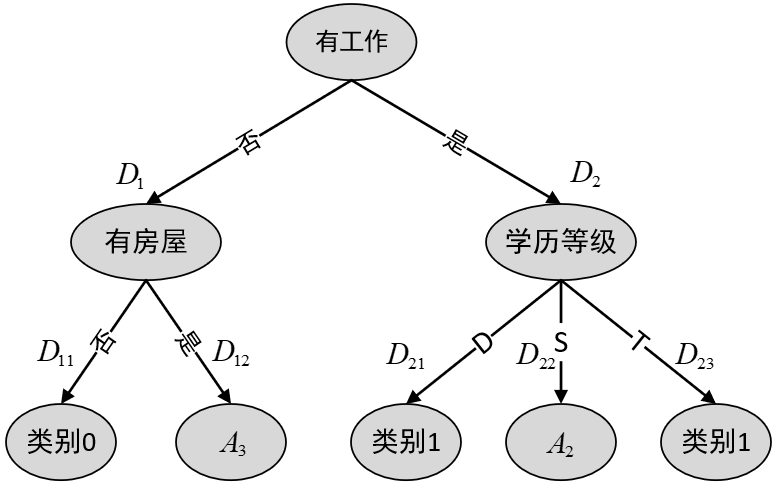
图8-4 第二次划分 由于子集
表8-4 第三次划分表 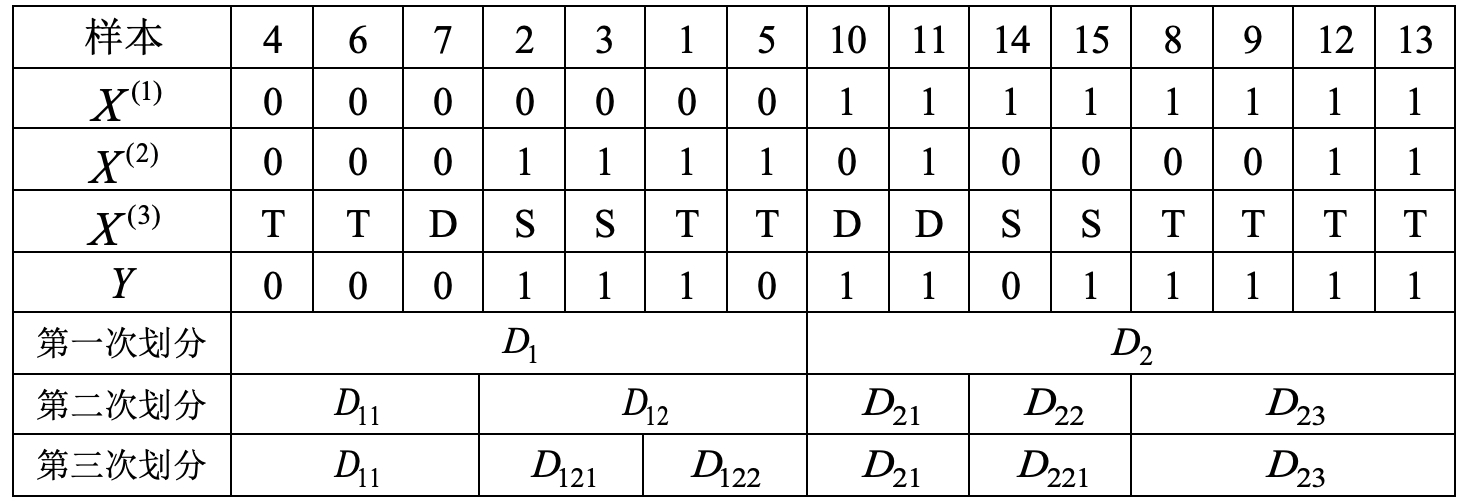
根据表8-4中的结果可知,子集
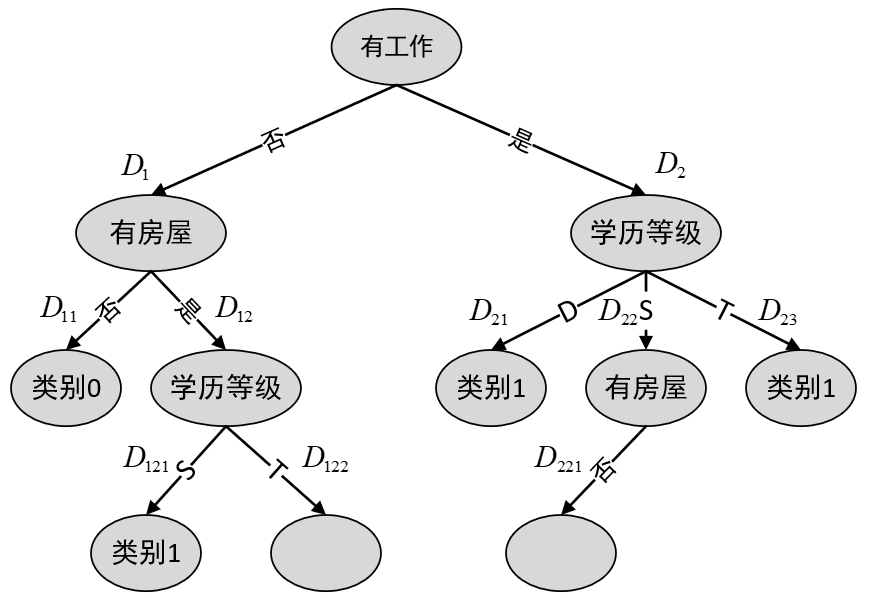
图8-5 第三次划分 此时,由于子集
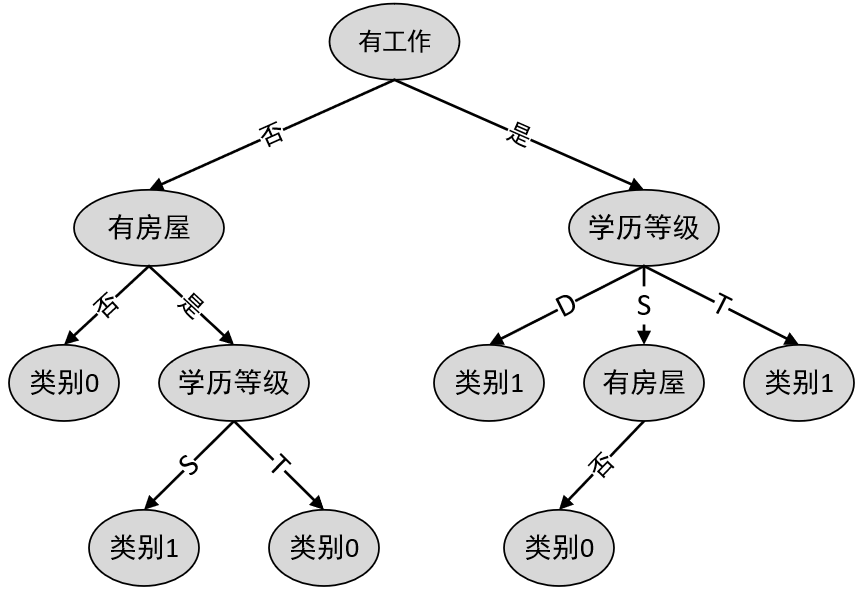
如上就是通过ID3算法生成整个决策树的详细过程。根据生成步骤可以发现,如果单纯以
2.4 C4.5生成算法
为了解决ID3算法的弊端,进而产生了C4.5算法。C4.5算法与ID3算法相似,不同之处仅在于C4.5算法在选择特征的时候采用了信息增益比作为标准,即选择信息增益比最大的特征作为当前样本集合的根节点。具体为,特征
其中,
因此,8.2.3节的例子中,对于选取根节点时其增益比计算如下:
- 计算得到信息增益
- 计算各特征的信息熵
- 计算信息增益比
根据式
由此,可以将利用C4.5算法来生成决策树的过程总结如下:
输入:训练数据集D,特征集A,阈值
输出:决策树。
(1) 若
(2) 若
(3) 否则,计算
(4) 如果
(5) 否则,对
(6) 对于第
从以上生成步骤可以看出,C4.5算法与ID3算法的唯一为别就是选择的标准不同,而其它的步骤均一样。到此为止,我们就学习完了决策树中的ID3与C4.5生成算法。在8.3节中,将来通过sklearn来完成决策树的建模工作。
2.5 特征划分
在经过上述两个小节的介绍之后,相信读者朋友们对于如何通过ID3和C4.5算法来构造一棵简单的决策树已经有了基本的了解。不过细心的读者可能会有这样一个疑问,那就是如何来处理连续型的特征变量。
从上面的示例数据集可以看出,工作、房子、学历这三个都属于离散型的特征变量(Discrete Variable),即每个特征的取值都属于某一个类别;而通常在实际建模过程中,更多的会是连续型的特征变量(Continuous Variable),例如年龄、身高等。在sklearn所实现的决策树算法中,对于这种连续型的特征变量,其具体做法便是先对其进行排序处理,然后取所有连续两个值的均值来离散化整个连续型特征变量[3]。
假设现在某数据集其中一个特征维度为
则首先需要对其进行排序处理,排序后的结果为
接着再计算所有连续两个值之间的平均值
这样,便得到了该特征离散化后结果。最后在构造决策树时,只需要使用式
2.6 小结
在本节中,掌柜首先回顾了决策树中几个重要的基本概念,并同时进行了相关示例计算;接着介绍了如何通过信息增益这一划分标准(即ID3算法)来构造生成决策树,并以一个真实的例子进行了计算示例;然后,介绍了通过引入信息增益比(即C4.5算法)这一划分标准来解决ID3算法在生成决策树时所存在的弊端;最后,介绍了在决策树生成时,如何处理连续型特征变量的一种常用方法。
3 决策树生成与可视化
在清楚决策树的相关生成算法后,再利用sklearn建模就变得十分容易了。下面使用的依旧是前面介绍的iris数据集,完整代码见Book\Chapter08\01_decision_tree_ID3.py文件。
3.1 ID3算法示例代码
在正式建模之前,掌柜先来对sklearn中类DecisionTreeClassifier里的几个常用参数进行简单的介绍。
xxxxxxxxxx811 def __init__(self, *,22 criterion="gini",33 splitter="best",44 max_depth=None,55 min_samples_split=2,66 min_samples_leaf=1,77 max_features=None,88 min_impurity_split=None): 在上述代码中,criterion用来选择划分时的度量标准,当criterion="entropy"时表示使用信息增益作为划分指标;splitter用来选择节点划分时的特征选择策略,当splitter="best"时则每次节点进行划分时均在所有特征中通过度量标准来选择最优划分方式,而当splitter="random"时则每次节点进行划分时只会随机选择max_features个特征,并在其中选择最优划分方式;max_depth表示决策树的最大深度,默认为None表示直到所有叶子节点的样本均为同一类别或者是样本数小于min_samples_split时停止划分;min_samples_leaf指定构成一个叶子节点所需要的最少样本数,即如果划分后叶子节点中的样本数小于该阈值,则不会进行划分;min_impurity_split用来提前停止节点划分的阈值,默认为None即无阈值。
1) 载入数据集
在介绍完类DecisionTreeClassifier的基本用法后,便可以通过其来完成决策树的生成。首先需要载入训练模型时所用到的数据集,同时为了后续更好的观察可视化后的决策树,所以这里也要返回各个特征的名称,代码如下:
xxxxxxxxxx711 def load_data():22 data = load_iris()33 X, y = data.data, data.target44 feature_names = data.feature_names55 X_train, X_test, y_train, y_test = \66 train_test_split(X, y, test_size=0.3, random_state=42)77 return X_train, X_test, y_train, y_test, feature_names在上述代码中,第4行代码便是得到特征维度的名称,其结果为:
xxxxxxxxxx111 ['sepal length(cm)','sepal width(cm)','petal length (cm)','petal width (cm)'] 2) 训练模型
在完成数据载入后,便可通过类DecisionTreeClassifier来完成决策树的生成。这里除了指定划分标准为'entropy'之外(即使用ID3算法),其它参数保持默认即可:
xxxxxxxxxx411 def train(X_train, X_test, y_train, y_test, feature_names):22 model = tree.DecisionTreeClassifier(criterion='entropy')33 model.fit(X_train, y_train)44 print("在测试集上的准确率为:",model.score(X_test, y_test))训练完成后,可以得到模型在测试集上的准确率为:
xxxxxxxxxx11在测试集上的准确率为: 1.03.2 决策树可视化
当拟合完成决策树后,还可以借助第三方工具graphviz [4]来对生成的决策树进行可视化。具体的,需要下载页面中Windows环境下的ZIP压缩包graphviz-2.46.1-win32.zip。在下载完成并解压成功后,可以得到一个名为Graphviz的文件夹。接着将文件夹Graphviz里的bin目录添加到环境变量中。步骤为右击“此电脑”,点击“属性”,再点击“高级系统设置”,继续点击“环境变量”,最后双击系统变量里的Path变量并新建一个变量输入内容为Graphviz中bin的路径即可,例如掌柜添加时的路径为C: \graphviz-2.46.1-win32\Graphviz\bin。
添加完成环境变量后,再安装graphviz包即可完成可视化的前期准备工作,命令为
xxxxxxxxxx11pip install graphviz要实现决策树的可视化,只需要在8.3.1节中train()函数后添加如下代码即可
xxxxxxxxxx611 dot_data = tree.export_graphviz(model, out_file=None,22 feature_names=feature_names,33 filled=True,rounded=True,44 special_characters=True)55 graph = graphviz.Source(dot_data)66 graph.render('iris')在整个代码运行结束后,便会在当前目录中生成一个名为iris.pdf的文件,这就是可视化后的结果,如图8-7所示。
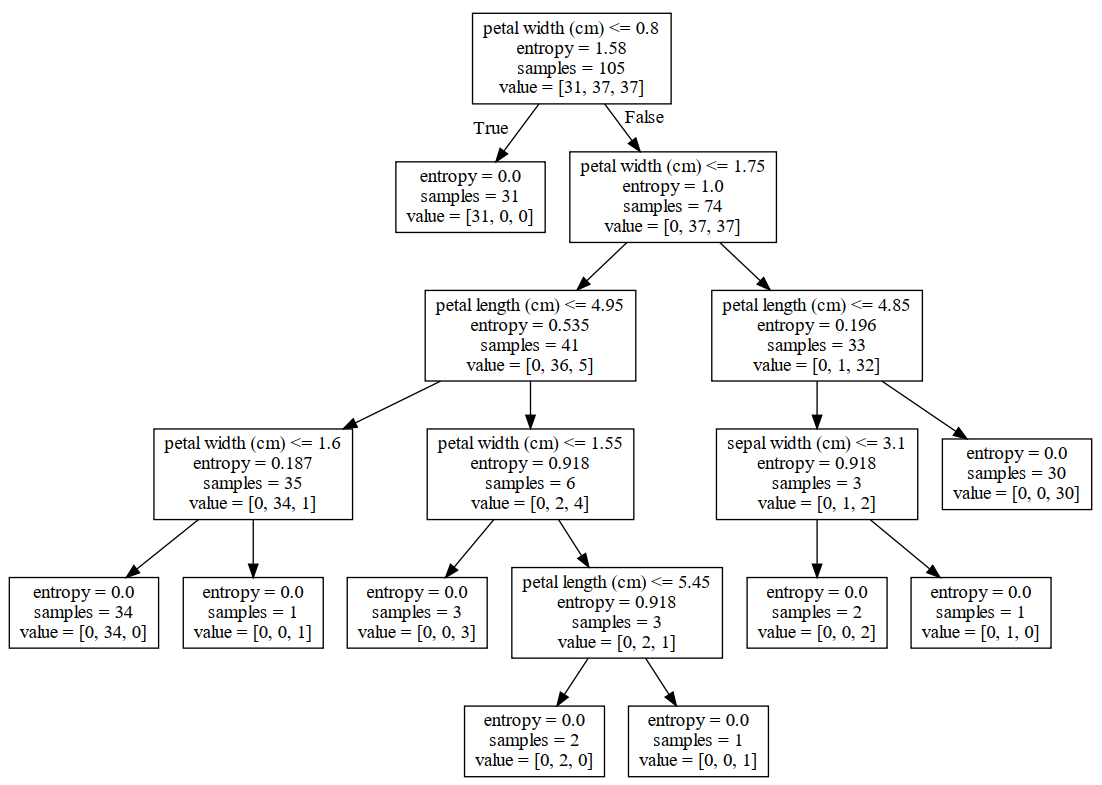
在图8-7中,samples表示当前节点的样本数,value为一个列表表示每个类别对应的样本数。从图中可以看出,随着决策树不断向下分裂,每个节点对应的信息熵总体上也在逐步减小,直到最终变成0结束。
3.3 小结
在本节中,掌柜首先介绍了类DecisionTreeClassifier的使用方法,包括其中一些常见的重要参数及其含义;接着介绍了如何根据现有的数据集来训练一个决策树模型;最后介绍了如何利用开源的graphviz工具来实现决策树的可视化。
4 决策树剪枝
4.1剪枝思想
在8.2节内容中掌柜介绍到,使用ID3算法进行构建决策树时容易产生过拟合现象,因此我们需要使用一种方法来缓解这一现象。通常,决策树过拟合的表现形式为这棵树有很多的叶子节点。想象一下如果这棵树为每个样本点都生成一个叶节点,那么也就代表着这棵树能够拟合所有的样本点,因为决策树的每个叶节点都表示一个分类类别。同时,出现过拟合的原因在于模型在学习时过多地考虑如何提高对训练数据的正确分类,从而构建出了过于复杂的决策树。因此,解决这一问题的办法就是考虑减少决策树的复杂度,对已经生成的决策树进行简化,也就是剪枝(Pruning)。
4.2 剪枝步骤
决策树的剪枝往是通过最小化决策树整体的损失函数或者代价函数来实现。设树
其中经验熵为
进一步有
此时损失函数可以写为
其中
具体的,决策树的剪枝步骤如下
输入:生成算法产生的整个树
输出:修剪后的子树
(1) 计算每个叶节点的经验(信息)熵;
(2) 递归地从树的叶节点往上回溯;设一组叶节点回溯到其父节点之前与之后的整体树分别为
(3) 返回(2),直到不能继续为止,得到损失函数最小的子树
当然,如果仅看这些步骤依旧会很模糊,下面掌柜再来通过一个实际计算示例进行说明。
4.3 剪枝示例
如图8-8所示,在考虑是否要减掉“学历等级”这个节点时,首先需要计算的就是剪枝前的损失函数数值
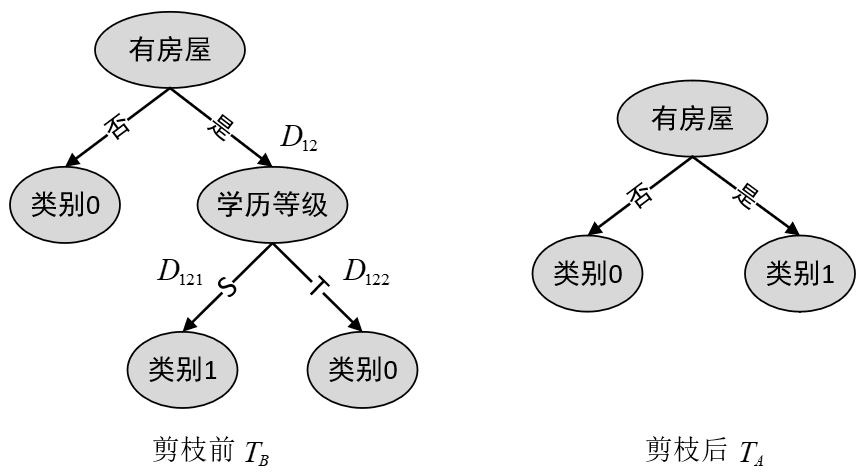
根据表8-3可知,“学历等级”这个节点对应的训练数据如表8-4所示。
根据式
进一步,根据式
同理可得,剪枝完成后树
由
从上述过程可以发现,通过剪枝来缓解决策树的过拟合现象算是一种事后补救的措施,即先生成决策树,然后进行简化处理。但实际上,还可以在决策树生成时就施加相应的条件来避免产生过拟合的现象。例如限制树的深度、限制每个叶节点的最少样本数等,当然这些都可以通过网格搜索来进行参数寻找。在图8-7所示的决策树中,如果将叶节点的最少数量设置为min_samples_leaf=10,那么便可以得到一个更加简单的决策树,如图8-9所示。

4.4 小结
在本节中,笔者首先介绍了决策树中的过拟合现象,阐述了为什么决策树会出现过拟合的现象;然后介绍了可以通过对决策树剪枝来实现缓解决策树过拟合的现象;最后进一步介绍了决策树剪枝的原理以及详细的剪枝计算过程,并且还提到可以通过在构建决策树时施加相应限制条件的方法来避免决策树产生过拟合现象。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞转发分享!若有任何疑问与建议,请添加掌柜微信nulls8或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1]吴军,数学之美,人民邮电出版社
[2] 李航,统计机器学习,清华大学出版社
[3]Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
[4] http://www.graphviz.org/download/
推荐阅读
[2] 第2章 从零认识线性回归(附高清PDF与教学PPT)
[3] 第3章 从零认识逻辑回归(附高清PDF与教学PPT)
[4] 第4章 模型的改善与泛化(附高清PDF与教学PPT)
[7]第7章 文本特征提取与模型复用(附高清PDF与教学PPT)