1 引言
各位朋友大家好,欢迎来到月来客栈。经过前面几篇文章的介绍,相信各位读者对于Transformer的基本原理以及实现过程已经有了一个较为清晰的认识。不过想要对一个网络模型有更加深刻的认识,那么最好的办法便是从数据预处理到模型训练,自己完完全全的经历一遍。因此,为了使得大家能够更加透彻的理解Transformer的整个工作流程,在本篇文章中笔者将继续带着大家一起来还原论文中的文本翻译模型。
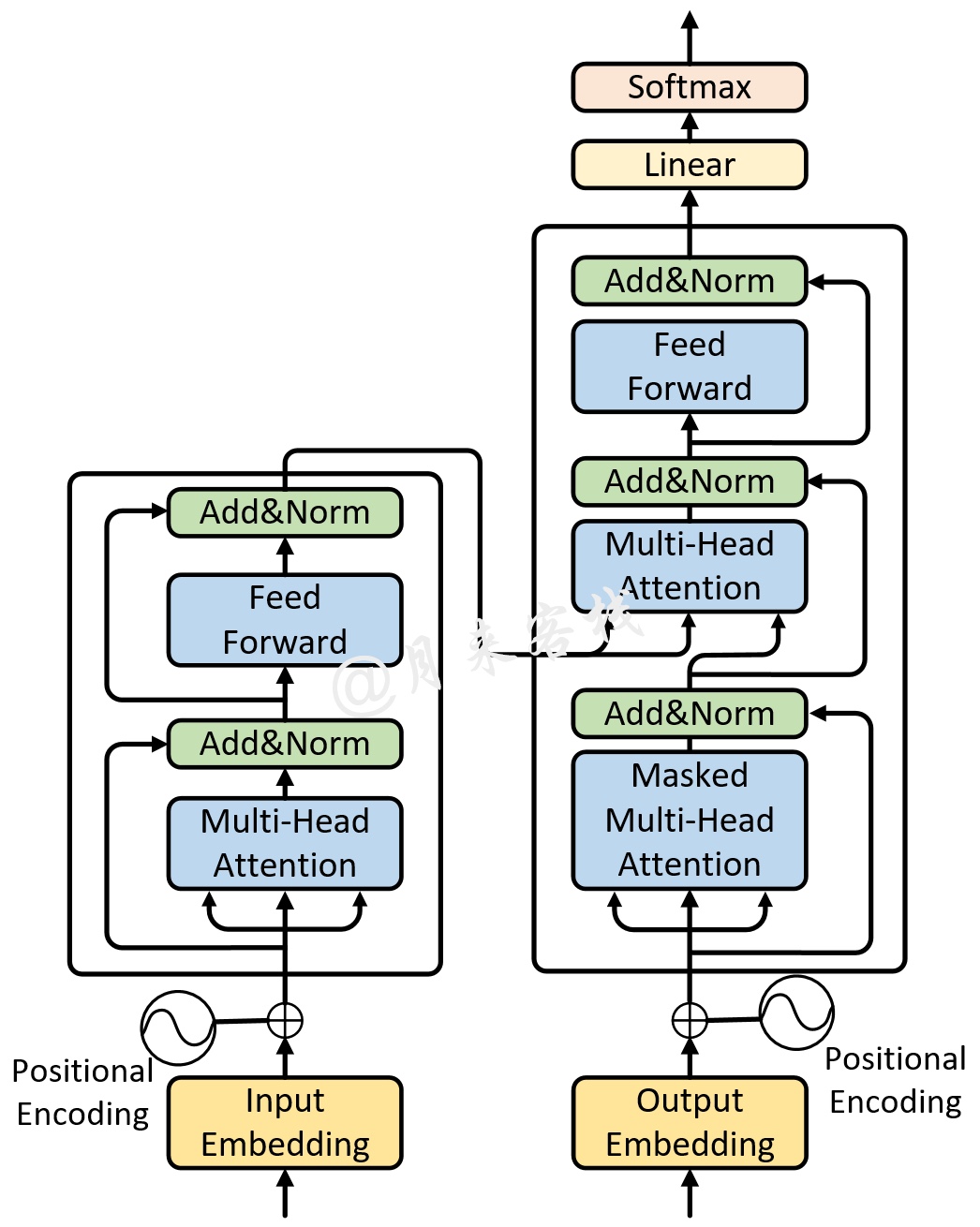
如图1所示便是Transformer网络的整体结构图,对于这部分内容在上一篇文章中总体上算是介绍完了,只是在数据预处理方面还未涉及。下面,笔者就以Multi30K[1]中的English-German平行语料为例进行介绍(注意这并不是论文中所用到数据集)。
2 数据预处理
2.1 语料介绍
在这里,我们使用到的平行语料一共包含有6个文件train.de、train.en、val.de、val.en、test_2016_flickr.de和test_2016_flickr.en,其分别为德语训练语料、英语训练语料、德语验证语料、英语验证语料、德语测试语料和英语测试语料。同时,这三部分的样本量分别为29000、1014和1000条。
如下所示便是一条平行预料数据,其中第1行为德语,第2行为英语,后续我们需要完成的就是搭建一个翻译模型将德语翻译为英语。
xxxxxxxxxx21Zwei junge weiße Männer sind im, Freien in der Nähe vieler Büsche.2Two young, White males are outside near many bushes.2.2 数据集预览
在正式介绍如何构建数据集之前,我们先通过几张图来了解一下整个构建的流程,以便做到心中有数,不会迷路。
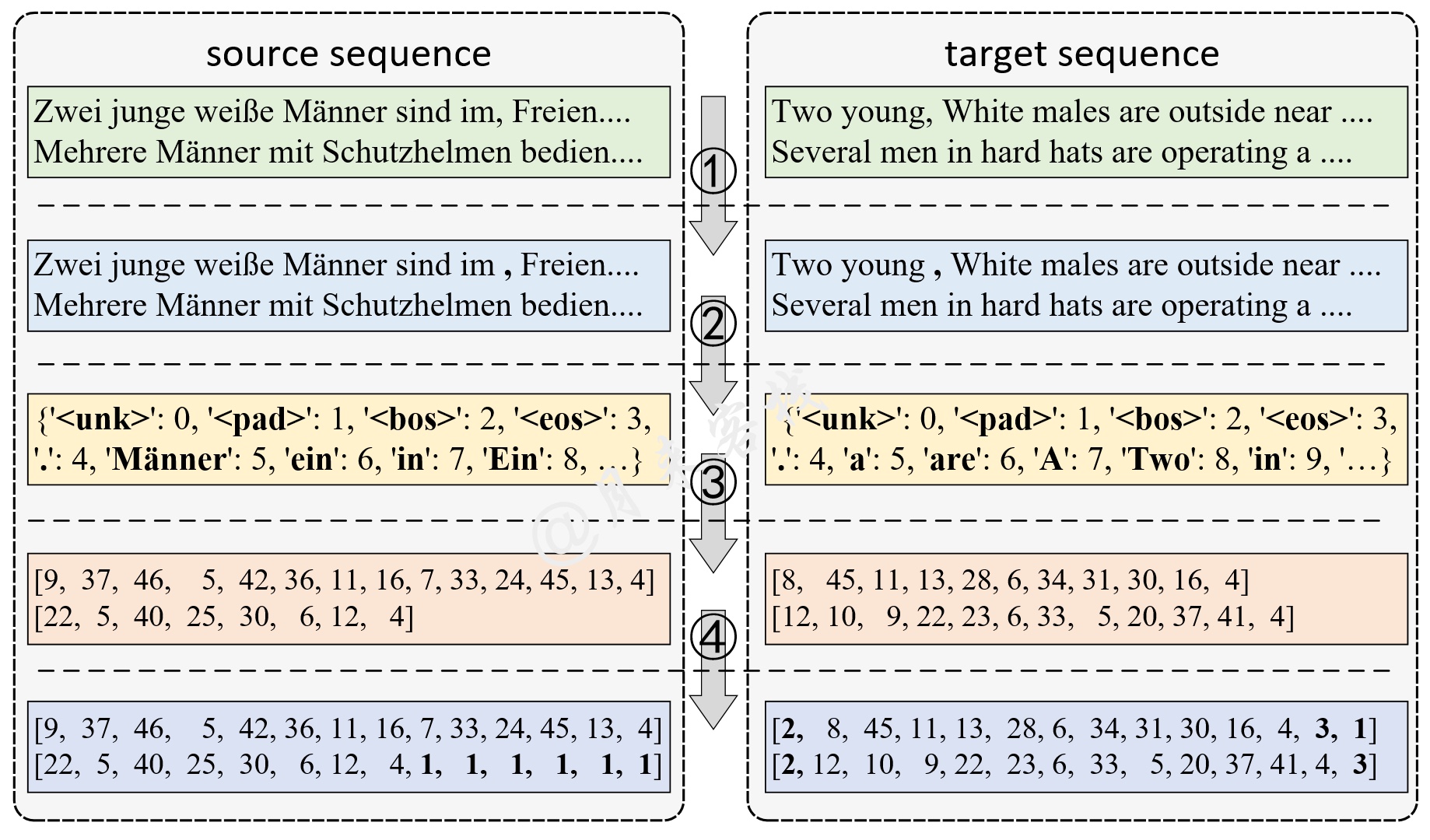
如图2所示,左边部分为原始输入,右边部分为目标输入。从图2可以看出,第1步需要完成的就是对原始语料进行tokenize操作。如果是对类似英文这样的语料进行处理,那就是直接按空格切分即可。但是需要注意的是要把其中的逗号和句号也给分割出来。第2步需要做的就是根据tokenize后的结果对原始输入和目标输入分别建立一个字典。第3步需要做的则是将tokenize后结果根据字典中的索引将其转换成token序列。第4步则是对同一个batch中的序列以最长的为标准其它样本进行padding,并且同时需要在目标输入序列的前后加上起止符(即'< bos >'和' < eos >') 。
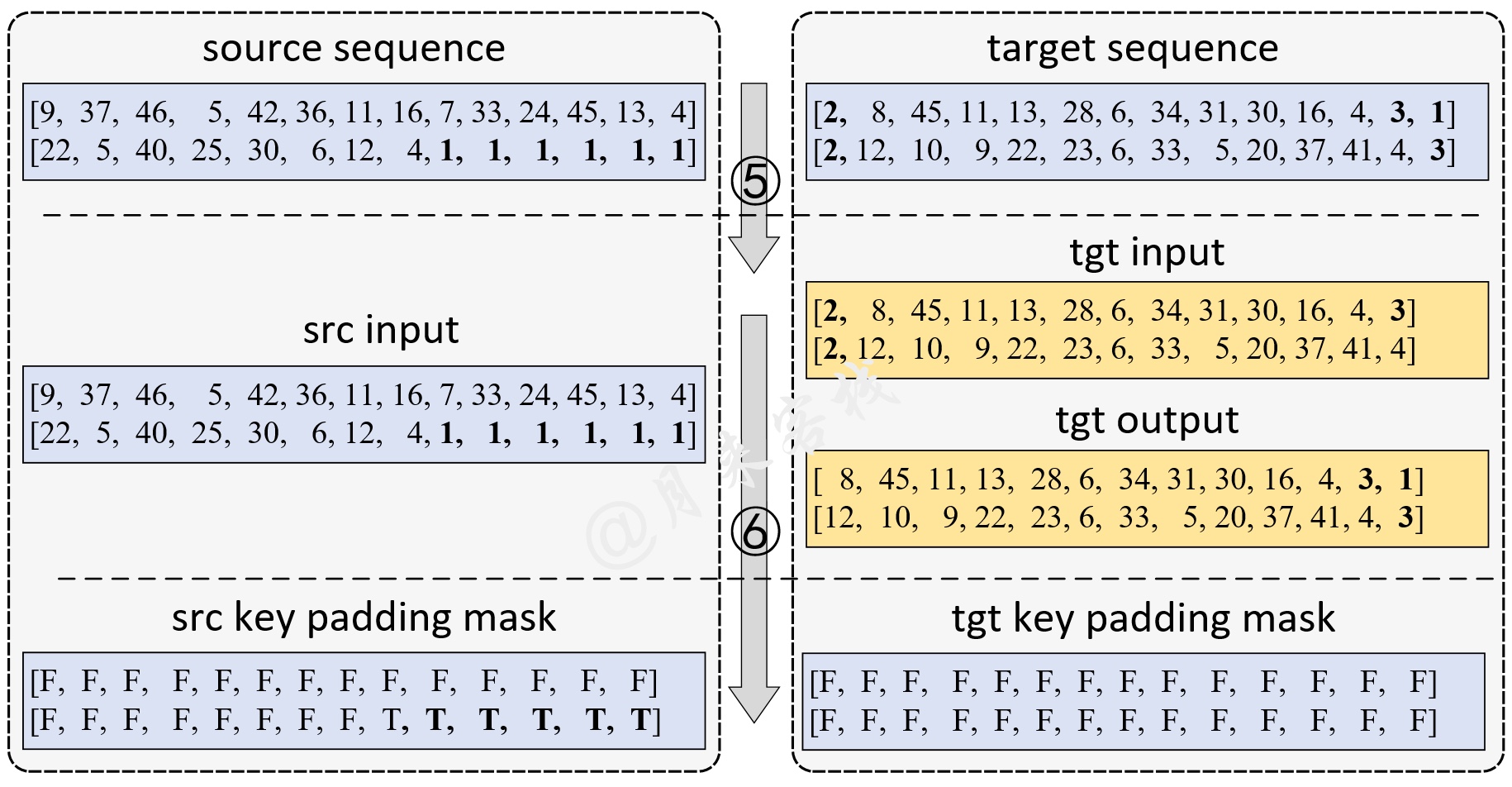
如图3所示,在完成前面4个步骤后,对于目标序列来说第5步需要做的就是将第4步处理后的结果划分成tgt_input和tgt_output。从图3右侧可以看出,tgt_input和tgt_output是相互对应起来的。例如对于第1个样本来说,解码第1个时刻的输入应该是"2",而此时刻对应的正确标签就应该是tgt_output中的'8';解码第2个时刻的输入应该是tgt_input中的'8',而此时刻对应的正确标签就应该是tgt_output中的'45',以此类推下去。最后,第6步则是根据src_input和tgt_input各自的padding情况,得到一个padding mask向量(注意由于这里tgt_input中的两个样本长度一样,所以并不需要padding),其中'T'表示padding的位置。当然,这里的tgt_mask并没有画出。
同时,图3中各个部分的结果体现在Transformer网络中的情况如图4所示。
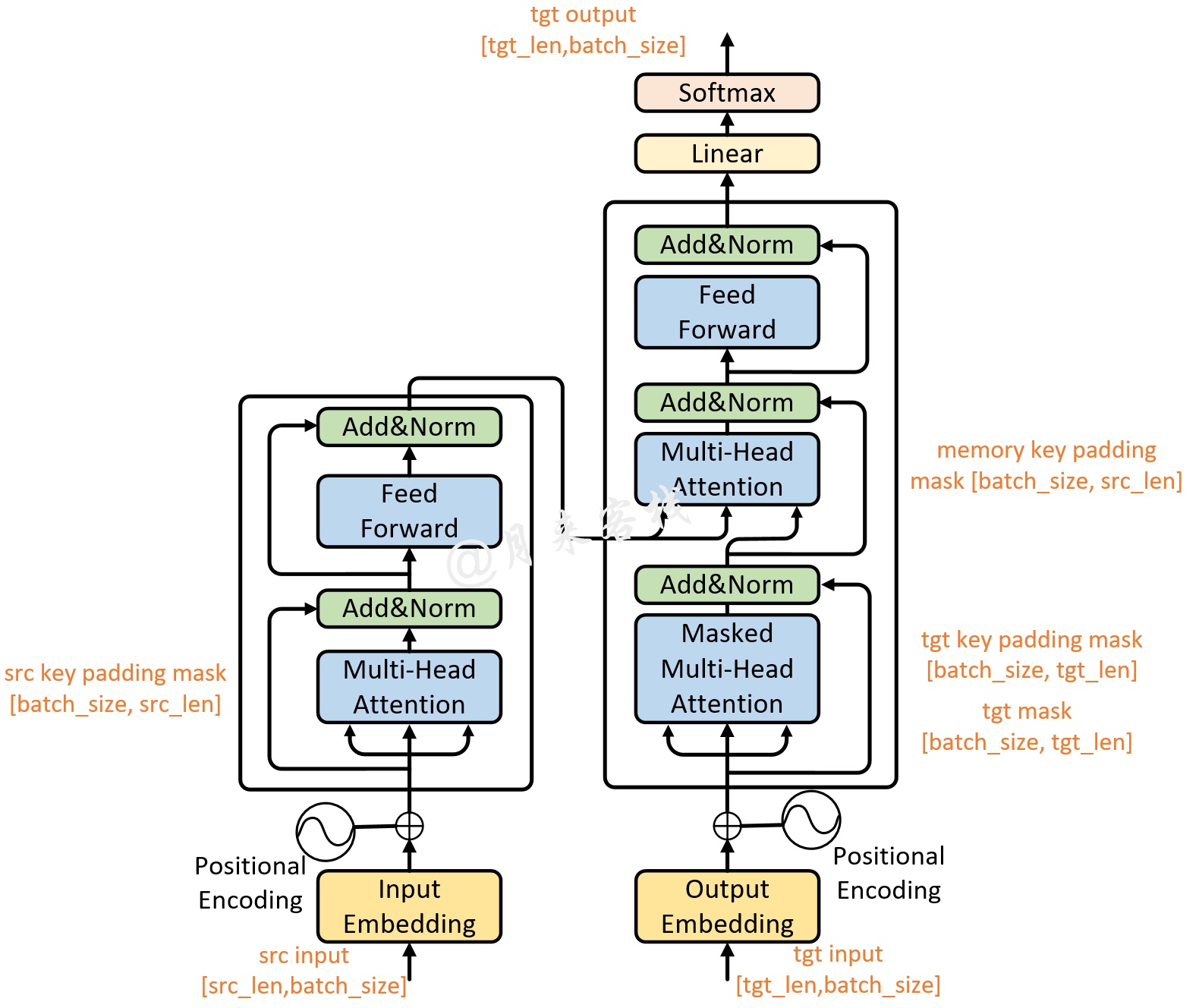
以上就是基于Transformer架构的翻译模型数据预处理的整个大致流程,下面我们开始正式来通过编码实现这一过程。
2.3 数据集构建
第1步:定义tokenize
如果是对类似英文这样的语料进行处理,那就是直接按空格切分即可。但是需要注意的是要把其中的逗号和句号也给分割出来。因此,这部分代码可以根据如下方式进行实现:
xxxxxxxxxx61def my_tokenizer(s):2 """3 返回tokenize后的结果4 """5 s = s.replace(',', " ,").replace(".", " .")6 return s.split()可以看到,其实也非常简单。例如对于如下文本来说
xxxxxxxxxx11Two young, White males are outside near many bushes.其tokenize后的结果为:
xxxxxxxxxx11['Two', 'young', ',', 'White', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']第2步:建立词表
在介绍完tokenize的实现方法后,我们就可以正式通过torchtext.vocab中的Vocab方法来构建词典了,代码如下:
xxxxxxxxxx81def build_vocab(tokenizer, filepath, word, min_freq, specials=None):2 if specials is None:3 specials = ['<unk>', '<pad>', '<bos>', '<eos>']4 counter = Counter()5 with open(filepath, encoding='utf8') as f:6 for string_ in f:7 counter.update(tokenizer(string_.strip(), word))8 return Vocab(counter, min_freq=min_freq, specials=specials)在上述代码中,第3行代码用来指定特殊的字符;第5-7行代码用来遍历文件中的每一个样本(每行一个)并进行tokenize和计数,其中对于counter.update进行介绍可以参考[2];第8行则是返回最后得到词典。
在完成上述过程后,我们将得到两个Vocab类的实例化对象。
一个为原始序列的字典:
xxxxxxxxxx11{'<unk>': 0, '<pad>': 1, '<bos>': 2, '<eos>': 3, '.': 4, 'Männer': 5, 'ein': 6, 'in': 7, 'Ein': 8, 'Zwei': 9, 'und': 10, ',': 11, ......}一个为目标序列的字典:
xxxxxxxxxx11{'<unk>': 0, '<pad>': 1, '<bos>': 2, '<eos>': 3, '.': 4, 'a': 5, 'are': 6, 'A': 7, 'Two': 8, 'in': 9, 'men': 10, ',': 11, 'Several': 12,......}此时,我们就需要定义一个类,并在类的初始化过程中根据训练语料完成字典的构建,代码如下:
xxxxxxxxxx111class LoadEnglishGermanDataset():2 def __init__(self, train_file_paths=None, tokenizer=None, batch_size=2):3 # 根据训练预料建立英语和德语各自的字典4 self.tokenizer = tokenizer5 self.de_vocab = build_vocab(self.tokenizer, filepath=train_file_paths[0])6 self.en_vocab = build_vocab(self.tokenizer, filepath=train_file_paths[1])7 self.specials = ['<unk>', '<pad>', '<bos>', '<eos>']8 self.PAD_IDX = self.de_vocab['<pad>']9 self.BOS_IDX = self.de_vocab['<bos>']10 self.EOS_IDX = self.de_vocab['<eos>']11 self.batch_size = batch_size第3步:转换为Token序列
在得到构建的字典后,便可以通过如下函数来将训练集、验证集和测试集转换成Token序列:
xxxxxxxxxx161 def data_process(self, filepaths):2 """3 将每一句话中的每一个词根据字典转换成索引的形式4 :param filepaths:5 :return:6 """7 raw_de_iter = iter(open(filepaths[0], encoding="utf8"))8 raw_en_iter = iter(open(filepaths[1], encoding="utf8"))9 data = []10 for (raw_de, raw_en) in zip(raw_de_iter, raw_en_iter):11 de_tensor_ = torch.tensor([self.de_vocab[token] for token in12 self.tokenizer(raw_de.rstrip("\n"))], dtype=torch.long)13 en_tensor_ = torch.tensor([self.en_vocab[token] for token in14 self.tokenizer(raw_en.rstrip("\n"))], dtype=torch.long)15 data.append((de_tensor_, en_tensor_))16 return data在上述代码中,第11-4行分别用来将原始序列和目标序列转换为对应词表中的Token形式。在处理完成后,就会得到类似如下的结果:
xxxxxxxxxx41 [(tensor([9,37, 46, 5, 42, 36, 11, 16,7, 33, 24, 45, 13,4]),tensor([8,45, 11, 13,28, 6, 34,31, 30,16, 4])),2 (tensor([22, 5, 40, 25, 30, 6, 12, 4]), tensor([12, 10, 9, 22, 23, 6, 33, 5, 20, 37, 41, 4])),3 (tensor([8, 38, 23, 39, 7, 6, 26, 29, 19, 4]), tensor([ 7, 27, 21, 18, 24, 5, 44, 35, 4])),4 (tensor([ 9, 5, 43, 27, 18, 10, 31, 14, 47, 4]), tensor([ 8, 10, 6, 14, 42, 40, 36, 19, 4])) ]其中左边的一列就是原始序列的Token形式,右边一列就是目标序列的Token形式,每一行构成一个样本。
第4步:padding处理
从上面的输出结果(以及图2中第③步后的结果)可以看到,无论是对于原始序列来说还是目标序列来说,在不同的样本中其对应长度都不尽相同。但是在将数据输入到相应模型时却需要保持同样的长度,因此在这里我们就需要对Token序列化后的样本进行padding处理。同时需要注意的是,一般在这种生成模型中,模型在训练过程中只需要保证同一个batch中所有的原始序列等长,所有的目标序列等长即可,也就是说不需要在整个数据集中所有样本都保证等长。
因此,在实际处理过程中无论是原始序列还是目标序列都会以每个batch中最长的样本为标准对其它样本进行padding,具体代码如下:
xxxxxxxxxx111 def generate_batch(self, data_batch):2 de_batch, en_batch = [], []3 for (de_item, en_item) in data_batch: # 开始对一个batch中的每一个样本进行处理。4 de_batch.append(de_item) # 编码器输入序列不需要加起止符5 # 在每个idx序列的首位加上 起始token 和 结束 token6 en = torch.cat([torch.tensor([self.BOS_IDX]), en_item, torch.tensor([self.EOS_IDX])], dim=0)7 en_batch.append(en)8 # 以最长的序列为标准进行填充9 de_batch = pad_sequence(de_batch, padding_value=self.PAD_IDX) # [de_len,batch_size]10 en_batch = pad_sequence(en_batch, padding_value=self.PAD_IDX) # [en_len,batch_size]11 return de_batch, en_batch在上述代码中,第6-7行用来在目标序列的首尾加上特定的起止符;第9-10行则是分别对一个batch中的原始序列和目标序列以各自当中最长的样本为标准进行padding(这里的pad_sequence导入自torch.nn.utils.rnn)。
第5步:构造mask向量
在处理完成图2中的第④步后,对于图3中的第⑤步来说就是简单的切片操作,因此就不作介绍。进一步需要根据src_input和tgt_input来构造相关的mask向量,具体代码如下:
xxxxxxxxxx171 def generate_square_subsequent_mask(self, sz, device):2 mask = (torch.triu(torch.ones((sz, sz), device=device)) == 1).transpose(0, 1)3 mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))4 return mask56 def create_mask(self, src, tgt, device='cpu'):7 src_seq_len = src.shape[0]8 tgt_seq_len = tgt.shape[0]9 tgt_mask = self.generate_square_subsequent_mask(tgt_seq_len, device) # [tgt_len,tgt_len]10 # Decoder的注意力Mask输入,用于掩盖当前position之后的position,所以这里是一个对称矩阵11 src_mask = torch.zeros((src_seq_len, src_seq_len), device=device).type(torch.bool)12 # Encoder的注意力Mask输入,这部分其实对于Encoder来说是没有用的,所以这里全是013 src_padding_mask = (src == self.PAD_IDX).transpose(0, 1)14 # 用于mask掉Encoder的Token序列中的padding部分,[batch_size, src_len]15 tgt_padding_mask = (tgt == self.PAD_IDX).transpose(0, 1)16 # 用于mask掉Decoder的Token序列中的padding部分,batch_size, tgt_len17 return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask在上述代码中,第1-4行是用来生成一个形状为[sz,sz]的注意力掩码矩阵,用于在解码过程中掩盖当前position之后的position;第6-17行用来返回Transformer中各种情况下的mask矩阵,其中src_mask在这里并没有作用。
第6步:构造DataLoade与使用示
经过前面5步的操作,整个数据集的构建就算是已经基本完成了,只需要再构造一个DataLoader迭代器即可,代码如下:
xxxxxxxxxx111 def load_train_val_test_data(self, train_file_paths, val_file_paths, test_file_paths):2 train_data = self.data_process(train_file_paths)3 val_data = self.data_process(val_file_paths)4 test_data = self.data_process(test_file_paths)5 train_iter = DataLoader(train_data, batch_size=self.batch_size,6 shuffle=True, collate_fn=self.generate_batch)7 valid_iter = DataLoader(val_data, batch_size=self.batch_size,8 shuffle=True, collate_fn=self.generate_batch)9 test_iter = DataLoader(test_data, batch_size=self.batch_size,10 shuffle=True, collate_fn=self.generate_batch)11 return train_iter, valid_iter, test_iter在上述代码中,第2-4行便是分别用来将训练集、验证集和测试集转换为Token序列;第5-10行则是分别构造3个DataLoader,其中generate_batch将作为一个参数传入来对每个batch的样本进行处理。在完成类LoadEnglishGermanDataset所有的编码过程后,便可以通过如下形式进行使用:
xxxxxxxxxx201if __name__ == '__main__':2 train_filepath = ['data/train_.de',3 'data/train_.en']45 data_loader = LoadEnglishGermanDataset(train_filepath, tokenizer=my_tokenizer, batch_size=2)6 train_iter, valid_iter, test_iter = data_loader.load_train_val_test_data(train_filepath,7 train_filepath,8 train_filepath)9 print(data_loader.PAD_IDX)10 for src, tgt in train_iter:11 tgt_input = tgt[:-1, :]12 tgt_out = tgt[1:, :]13 src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = data_loader.create_mask(src, tgt_input)14 print("src shape:", src.shape) # [de_tensor_len,batch_size]15 print("src_padding_mask shape (batch_size, src_len): ", src_padding_mask.shape)16 print("tgt input shape:", tgt_input.shape)17 print("tgt_padding_mask shape: (batch_size, tgt_len) ", tgt_padding_mask.shape)18 print("tgt output shape:", tgt_out.shape)19 print("tgt_mask shape (tgt_len,tgt_len): ", tgt_mask.shape)20 break各位读者在阅读这部分代码时最好是能够结合图2-4进行理解,这样效果可能会更好。在介绍完数据集构建的整个过程后,下面就开始正式进入到翻译模型的构建中。
3 基于Transformer的翻译模型
3.1 网络结构
总体来说,基于Transformer的翻译模型的网络结构其实就是图4所展示的所有部分,只是在前面介绍Transformer网络结构时笔者并没有把Embedding部分的实现给加进去。这是因为对于不同的文本生成模型,其Embedding部分会不一样(例如在诗歌生成这一情景中编码器和解码器共用一个TokenEmbedding即可,而在翻译模型中就需要两个),所以将两者进行了拆分。同时,待模型训练完成后,在inference过程中Encoder只需要执行一次,所以在此过程中也需要单独使用Transformer中的Encoder和Decoder。
首先,我们需要定义一个名为TranslationModel的类,其前向传播过程代码如下所示:
xxxxxxxxxx401class TranslationModel(nn.Module):2 def __init__(self, src_vocab_size, tgt_vocab_size, 3 d_model=512, nhead=8, num_encoder_layers=6,4 num_decoder_layers=6, dim_feedforward=2048, 5 dropout=0.1):6 super(TranslationModel, self).__init__()7 self.my_transformer = MyTransformer(d_model=d_model,8 nhead=nhead,9 num_encoder_layers=num_encoder_layers,10 num_decoder_layers=num_decoder_layers,11 dim_feedforward=dim_feedforward,12 dropout=dropout)13 self.pos_embedding = PositionalEncoding(d_model=d_model, dropout=dropout)14 self.src_token_embedding = TokenEmbedding(src_vocab_size, d_model)15 self.tgt_token_embedding = TokenEmbedding(tgt_vocab_size, d_model)16 self.classification = nn.Linear(d_model, tgt_vocab_size)1718 def forward(self, src=None, tgt=None, src_mask=None, 19 tgt_mask=None, memory_mask=None, src_key_padding_mask=None,20 tgt_key_padding_mask=None, memory_key_padding_mask=None):21 """22 src: Encoder的输入 [src_len,batch_size]23 tgt: Decoder的输入 [tgt_len,batch_size]24 src_key_padding_mask: 用来Mask掉Encoder中不同序列的padding部分,[batch_size, src_len]25 tgt_key_padding_mask: 用来Mask掉Decoder中不同序列的padding部分 [batch_size, tgt_len]26 memory_key_padding_mask: 用来Mask掉Encoder输出的memory中不同序列的padding部分 [batch_size, src_len]27 :return:28 """29 src_embed = self.src_token_embedding(src) # [src_len, batch_size, embed_dim]30 src_embed = self.pos_embedding(src_embed) # [src_len, batch_size, embed_dim]31 tgt_embed = self.tgt_token_embedding(tgt) # [tgt_len, batch_size, embed_dim]32 tgt_embed = self.pos_embedding(tgt_embed) # [tgt_len, batch_size, embed_dim]33 outs = self.my_transformer(src=src_embed, tgt=tgt_embed, src_mask=src_mask, 34 tgt_mask=tgt_mask,memory_mask=memory_mask, 35 src_key_padding_mask=src_key_padding_mask,36 tgt_key_padding_mask=tgt_key_padding_mask,37 memory_key_padding_mask=memory_key_padding_mask) 38 # [tgt_len,batch_size,embed_dim]39 logits = self.classification(outs) # [tgt_len,batch_size,tgt_vocab_size]40 return logits在上述代码中,第7-12行便是用来定义一个Transformer结构;第13-16分别用来定义Positional Embedding、Token Embedding和最后的分类器;第29-39行便是用来执行整个前向传播过程,其中Transformer的整个前向传播过程在前一篇文章中已经介绍过,在这里就不再赘述。
在定义完logits的前向传播过后,便可以通过如下形式进行使用:
xxxxxxxxxx241if __name__ == '__main__':2 src_len = 73 batch_size = 24 dmodel = 325 tgt_len = 86 num_head = 47 src = torch.tensor([[4, 3, 2, 6, 0, 0, 0],8 [5, 7, 8, 2, 4, 0, 0]]).transpose(0, 1) # 转换成 [src_len, batch_size]9 src_key_padding_mask = torch.tensor([[True, True, True, True, False, False, False],10 [True, True, True, True, True, False, False]])1112 tgt = torch.tensor([[1, 3, 3, 5, 4, 3, 0, 0],13 [1, 6, 8, 2, 9, 1, 0, 0]]).transpose(0, 1)14 tgt_key_padding_mask = torch.tensor([[True, True, True, True, True, True, False, False],15 [True, True, True, True, True, True, False, False]])1617 trans_model = TranslationModel(src_vocab_size=10, tgt_vocab_size=15,18 d_model=dmodel,nhead=num_head,num_encoder_layers=6,19 num_decoder_layers=6, dim_feedforward=30, dropout=0.1)20 tgt_mask = trans_model.my_transformer.generate_square_subsequent_mask(tgt_len)21 logits = trans_model(src, tgt=tgt, tgt_mask=tgt_mask, src_key_padding_mask=src_key_padding_mask,22 tgt_key_padding_mask=tgt_key_padding_mask,23 memory_key_padding_mask=src_key_padding_mask)24 print(logits.shape) # torch.Size([8, 2, 15]) [tgt_len,batch_size,tgt_vocab_size]接着,我们需要再定义一个Encoder和Decoder在inference中使用,代码如下:
xxxxxxxxxx121 def encoder(self, src):2 src_embed = self.src_token_embedding(src) # [src_len, batch_size, embed_dim]3 src_embed = self.pos_embedding(src_embed) # [src_len, batch_size, embed_dim]4 memory = self.my_transformer.encoder(src_embed)5 return memory67 def decoder(self, tgt, memory, tgt_mask):8 tgt_embed = self.tgt_token_embedding(tgt) # [tgt_len, batch_size, embed_dim]9 tgt_embed = self.pos_embedding(tgt_embed) # [tgt_len, batch_size, embed_dim]10 outs = self.my_transformer.decoder(tgt_embed, memory=memory,11 tgt_mask=tgt_mask) # [tgt_len,batch_size,embed_dim]12 return outs在上述代码中,第1-5行用于在inference时对输入序列进行编码并得到memory(只需要执行一次);第7-11行用于根据memory和当前解码时刻的输入对输出进行预测,需要循环执行多次,这部分内容详见模型预测部分。
3.2 模型训练
在定义完成整个翻译模型的网络结构后下面就可以开始训练模型了。由于这部分代码较长,所以下面笔者依旧以分块的形式进行介绍:
第1步:载入数据集
xxxxxxxxxx81def train_model(config):2 data_loader = LoadEnglishGermanDataset(config.train_corpus_file_paths,3 batch_size=config.batch_size,4 tokenizer=my_tokenizer)5 train_iter, valid_iter, test_iter = \6 data_loader.load_train_val_test_data(config.train_corpus_file_paths,7 config.val_corpus_file_paths,8 config.test_corpus_file_paths)首先我们可以根据前面的介绍,通过类LoadEnglishGermanDataset来载入数据集,其中config中定义了模型所涉及到的所有配置参数。
第2步:定义模型并初始化权重
xxxxxxxxxx111 translation_model = TranslationModel(src_vocab_size=len(data_loader.de_vocab),2 tgt_vocab_size=len(data_loader.en_vocab),3 d_model=config.d_model,4 nhead=config.num_head,5 num_encoder_layers=config.num_encoder_layers,6 num_decoder_layers=config.num_decoder_layers,7 dim_feedforward=config.dim_feedforward,8 dropout=config.dropout)9 for p in translation_model.parameters():10 if p.dim() > 1:11 nn.init.xavier_uniform_(p)在载入数据后,便可以定义一个翻译模型TranslationModel,并根据相关参数对其进行实例化;同时,可以对整个模型中的所有参数进行一个初始化操作。
第3步:定义损失学习率与优化器
xxxxxxxxxx51 loss_fn = torch.nn.CrossEntropyLoss(ignore_index=data_loader.PAD_IDX)2 learning_rate = CustomSchedule(config.d_model)3 optimizer = torch.optim.Adam(translation_model.parameters(),4 lr=config.warm_up_learning_rate,5 betas=(config.beta1, config.beta2), eps=config.epsilon)在上述代码中,第1行是定义交叉熵损失函数,并同时指定需要忽略的索引ignore_index。因为根据图3的tgt_output可知,有些位置上的标签值其实是Padding后的结果,因此在计算损失的时候需要将这些位置给忽略掉。第2行代码则是论文中所提出来的动态学习率计算过程,其计算公式为:
具体实现代码为:
xxxxxxxxxx121class CustomSchedule(nn.Module):2 def __init__(self, d_model, warmup_steps=4000):3 super(CustomSchedule, self).__init__()4 self.d_model = torch.tensor(d_model, dtype=torch.float32)5 self.warmup_steps = warmup_steps6 self.step = 1.78 def __call__(self):9 arg1 = self.step ** -0.510 arg2 = self.step * (self.warmup_steps ** -1.5)11 self.step += 1.12 return (self.d_model ** -0.5) * min(arg1, arg2)通过CustomSchedule,就能够在训练过程中动态的调整学习率。学习率随step增加而变换的结果如图5所示:
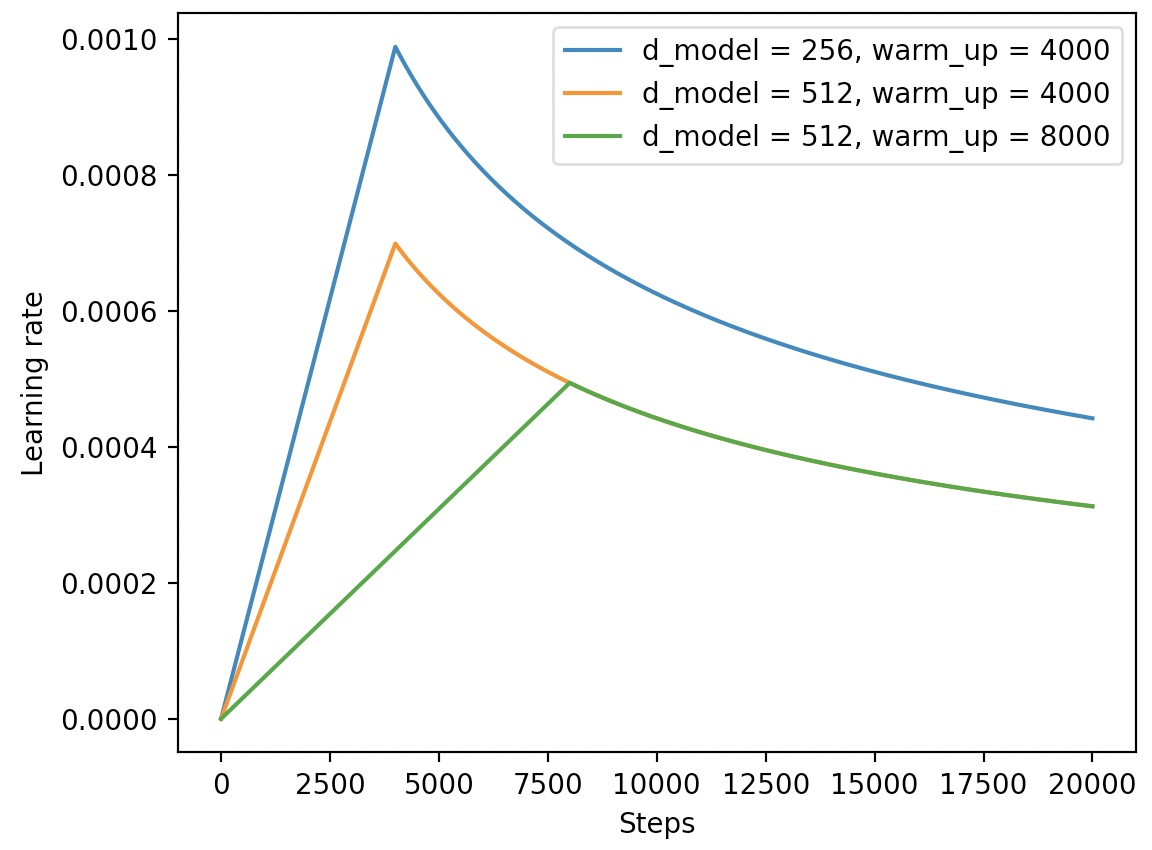
从图5可以看出,在前warm_up个step中,学习率是线性增长的,在这之后便是非线性下降,直至收敛与0.0004。
第4步:开始训练
xxxxxxxxxx321 for epoch in range(config.epochs):2 losses = 03 start_time = time.time()4 for idx, (src, tgt) in enumerate(train_iter):5 src = src.to(config.device) # [src_len, batch_size]6 tgt = tgt.to(config.device)7 tgt_input = tgt[:-1, :] # 解码部分的输入, [tgt_len,batch_size]8 src_mask, tgt_mask, src_padding_mask, tgt_padding_mask \9 = data_loader.create_mask(src, tgt_input, config.device)10 logits = translation_model(11 src=src, # Encoder的token序列输入,[src_len,batch_size]12 tgt=tgt_input, # Decoder的token序列输入,[tgt_len,batch_size]13 src_mask=src_mask, # Encoder的注意力Mask输入,这部分其实对于Encoder来说是没有用的14 tgt_mask=tgt_mask,15 # Decoder的注意力Mask输入,用于掩盖当前position之后的position [tgt_len,tgt_len]16 src_key_padding_mask=src_padding_mask, # 用于mask掉Encoder的Token序列中的padding部分17 tgt_key_padding_mask=tgt_padding_mask, # 用于mask掉Decoder的Token序列中的padding部分18 memory_key_padding_mask=src_padding_mask) # 用于mask掉Encoder的Token序列中的padding部分19 # logits 输出shape为[tgt_len,batch_size,tgt_vocab_size]20 21 optimizer.zero_grad()22 tgt_out = tgt[1:, :] # 解码部分的真实值 shape: [tgt_len,batch_size]23 loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))24 # [tgt_len*batch_size, tgt_vocab_size] with [tgt_len*batch_size, ]25 loss.backward()26 lr = learning_rate()27 for p in optimizer.param_groups:28 p['lr'] = lr29 optimizer.step()30 losses += loss.item()31 acc, _, _ = accuracy(logits, tgt_out, data_loader.PAD_IDX)32 print(f"Epoch: {epoch}, Train loss :{loss.item():.3f}, Train acc: {acc}")在上述代码中,第5-9行是用来得到模型各个部分的输入;第10-18行是计算模型整个前向传播的过程;第21-25行则是执行损失计算与反向传播;第27-29则是将每个step更新后的学习率送入到模型中并更新参数;第31行是用来计算模型预测的准确率,具体过程将在后续文章中进行介绍。以下便是模型训练过程中的输出:
xxxxxxxxxx61Epoch: 2, Train loss: 5.685, Train acc: 0.2409472Epoch: 2, Train loss: 5.668, Train acc: 0.2414933Epoch: 2, Train loss: 5.714, Train acc: 0.2246824Epoch: 2, Train loss: 5.660, Train acc: 0.2358885Epoch: 2, Train loss: 5.584, Train acc: 0.2420526Epoch: 2, Train loss: 5.611, Train acc: 0.2434283.3 模型预测
在介绍完模型的训练过程后接下来就来看模型的预测部分。生成模型的预测部分不像普通的分类任务只需要将网络最后的输出做argmax操作即可,生成模型在预测过程中往往需要按时刻一步步进行来进行。因此,下面我们这里定义一个translate函数来执行这一过程,具体代码如下:
xxxxxxxxxx121def translate(model, src, data_loader, config):2 src_vocab = data_loader.de_vocab3 tgt_vocab = data_loader.en_vocab4 src_tokenizer = data_loader.tokenizer5 model.eval()6 tokens = [src_vocab.stoi[tok] for tok in src_tokenizer(src)] # 构造一个样本7 num_tokens = len(tokens)8 src = (torch.LongTensor(tokens).reshape(num_tokens, 1)) # 将src_len 作为第一个维度9 tgt_tokens = greedy_decode(model, src, max_len=num_tokens + 5,10 start_symbol=data_loader.BOS_IDX, config=config,11 data_loader=data_loader).flatten() # 解码的预测结果12 return " ".join([tgt_vocab.itos[tok] for tok in tgt_tokens]).replace("<bos>", "").replace("<eos>", "")在上述代码中,第6行是将待翻译的源序列进行序列化操作;第8-11行则是通过函数greedy_decode函数来对输入进行解码;第12行则是将最后解码后的结果由Token序列在转换成实际的目标语言。同时,greedy_decode函数的实现如下:
xxxxxxxxxx191def greedy_decode(model, src, max_len, start_symbol, config, data_loader):2 src = src.to(config.device)3 memory = model.encoder(src) # 对输入的Token序列进行解码翻译4 ys = torch.ones(1, 1).fill_(start_symbol). \5 type(torch.long).to(config.device) # 解码的第一个输入,起始符号6 for i in range(max_len - 1):7 memory = memory.to(config.device)8 tgt_mask = (model.my_transformer.generate_square_subsequent_mask(ys.size(0))9 .type(torch.bool)).to(config.device) # 根据tgt_len产生一个注意力mask矩阵(对称的)10 out = model.decoder(ys, memory, tgt_mask) # [tgt_len,tgt_vocab_size]11 out = out.transpose(0, 1) # [tgt_vocab_size, tgt_len]12 prob = model.classification(out[:, -1]) # 只对对预测的下一个词进行分类13 _, next_word = torch.max(prob, dim=1) # 选择概率最大者14 next_word = next_word.item()15 ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)16 # 将当前时刻解码的预测输出结果,同之前所有的结果堆叠作为输入再去预测下一个词。17 if next_word == data_loader.EOS_IDX: # 如果当前时刻的预测输出为结束标志,则跳出循环结束预测。18 break19 return ys在上述代码中,第3行是将源序列输入到Transformer的编码器中进行编码并得到Memory;第4-5行是初始化解码阶段输入的第1个时刻的,在这里也就是' EOS_IDX或者达到最大长度后停止;第8-9行是根据当前解码器输入的长度生成注意力掩码矩阵tgt_mask;第10行是根据memory以及当前时刻的输入对当前时刻的输出进行解码;第12-14行则是分类得到当前时刻的解码输出结果;第15行则是将当前时刻的解码输出结果头当前时刻之前所有的输入进行拼接,以此再对下一个时刻的输出进行预测。
最后,我们只需要调用如下函数便可以完成对原始输入语言的翻译任务:
xxxxxxxxxx281def translate_german_to_english(src, config):2 data_loader = LoadEnglishGermanDataset(config.train_corpus_file_paths,3 batch_size=config.batch_size,4 tokenizer=my_tokenizer)5 translation_model = TranslationModel(src_vocab_size=len(data_loader.de_vocab),6 tgt_vocab_size=len(data_loader.en_vocab),7 d_model=config.d_model,8 nhead=config.num_head,9 num_encoder_layers=config.num_encoder_layers,10 num_decoder_layers=config.num_decoder_layers,11 dim_feedforward=config.dim_feedforward,12 dropout=config.dropout)13 translation_model = translation_model.to(config.device)14 torch.load(config.model_save_dir + '/model.pkl')15 r = translate(translation_model, src, data_loader, config)16 return r1718if __name__ == '__main__':19 srcs = ["Eine Gruppe von Menschen steht vor einem Iglu.",20 "Ein Mann in einem blauen Hemd steht auf einer Leiter und putzt ein Fenster."]21 tgts = ["A group of people are facing an igloo.",22 "A man in a blue shirt is standing on a ladder cleaning a window."]23 config = Config()24 for i, src in enumerate(srcs):25 r = translate_german_to_english(src, config)26 print(f"德语:{src}")27 print(f"翻译:{r}")28 print(f"英语:{tgts[i]}")在上述代码中,第5-14行是定义网络结构,以及恢复本地保存的网络权重;第15行则是开始执行翻译任务;第19-28行为翻译示例,其输出结果为:
xxxxxxxxxx71德语:Eine Gruppe von Menschen steht vor einem Iglu.2翻译:A group of people standing in fraon of an igloo .3英语:A group of people are facing an igloo.4=========5德语:Ein Mann in einem blauen Hemd steht auf einer Leiter und putzt ein Fenster.6翻译:A man in a blue shirt is standing on a ladder cleaning a window.7英语:A man in a blue shirt is standing on a ladder cleaning a window.其中第一句德语为训练集之外的数据。
以上完整代码可参见[3]。
4 总结
在这篇文章中,笔者首先介绍了翻译模型的整个数据预处理过程,包括首先以图示的方式对整个过程进行了说明,然后再一步步地通过编码实现了整个数据集的构造过程;接着笔者介绍了基于Transformer结构的翻译模型的整体构成,然后循序渐进地带着各位读者来实现了整个翻译模型,包括基础结构的搭建、模型训练的详细实现、动态学习率的调整实现等;最后介绍了如何来实现模型在实际预测过程中的处理流程等,包括源输入序列的构建、解码时刻输入序列的构建等。在下一篇文章中,笔者将会介绍如何基于Transformer结构来搭建一个简单的文本分类模型。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加笔者微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] https://github.com/multi30k/dataset
[3] https://github.com/moon-hotel/TransformerTranslation
推荐阅读
[1] This post is all you need(①多头注意力机制原理)
[2] This post is all you need(②位置编码与编码解码过程)


