1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
在上一篇文章中掌柜说到,对于BERT技术实现这部分内容将会分为三个大的部分来进行介绍。第一部分主要介绍BERT的网络结构原理以及MLM和NSP这两种任务的具体原理;第二部分将主要介绍如何实现BERT以及BERT预训练模型在下游任务中的使用;第三部分则是介绍如何利用MLM和NSP这两个任务来训练BERT模型(可以是从头开始,也可以是基于开源的BERT预训练模型开始)。第一部分内容在上一篇文章中已经介绍完了,在本篇文章中掌柜将开始详细来介绍第二部分的内容。
以下所有完整实现代码均可从仓库 https://github.com/moon-hotel/BertWithPretrained 中获取!
2 BERT实现
2.1 BERT网络结构回顾
经过上一篇文章[1]的介绍相信大家对于BERT模型的整体结构已经有了一定的了解。如图1所示,本质上来说BERT就是由多个不同的Transformer结构堆叠而来,同时在Embedding部分多加入了一个Segment Embedding。
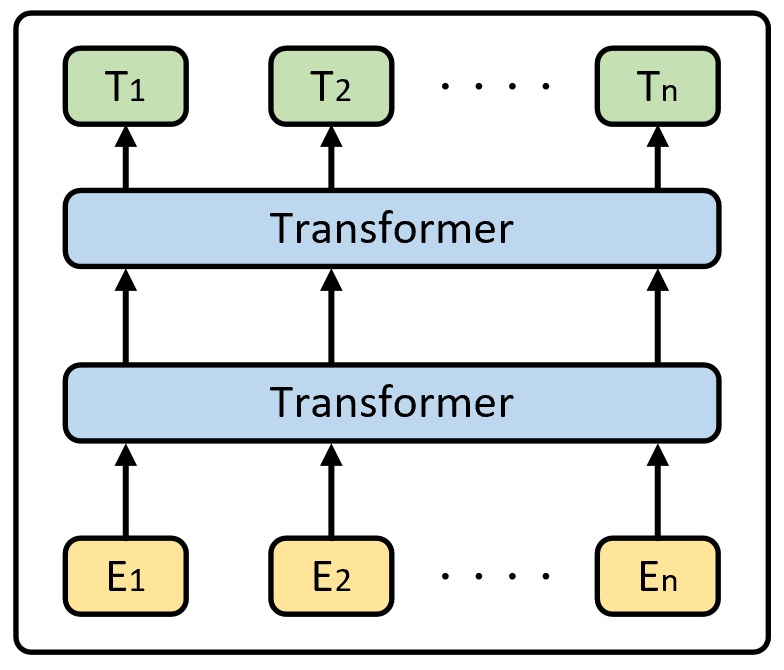
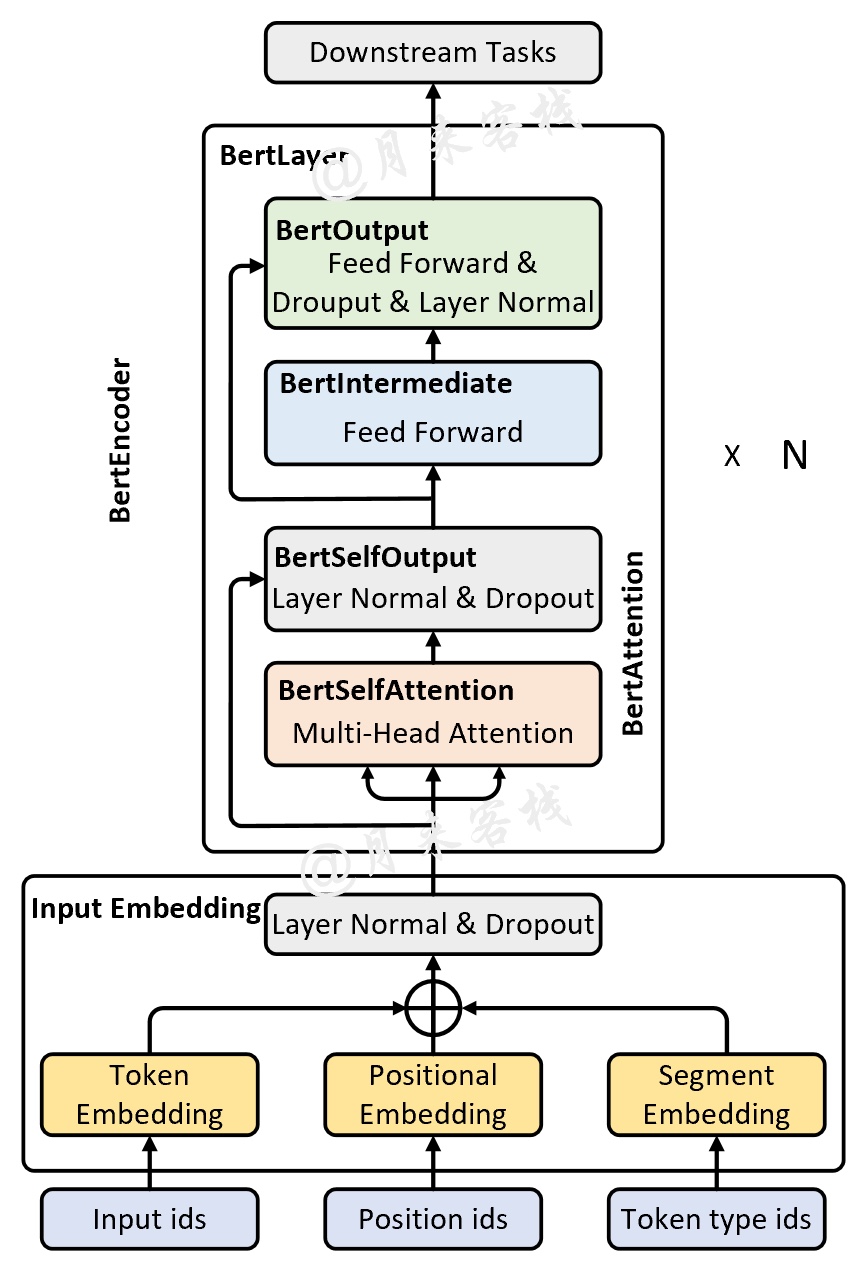
进一步,如果将图1所示的网络结构展开,将会得到如图2所示的样子。在接下来的代码实现过程中,掌柜将会以图2中黑色加粗字体所示的部分为一个类进行实现。
2.2 Input Embedding实现
首先,我们先来看看Input Embedding的实现过程。为了复用之前在介绍Transformer实现时所用到的这部分代码,我们直接在这基础上再加一个Segment Embedding即可。
2.2.1 Token Embedding
Token Embedding算是NLP中将文本表示为向量的一个基本操作,其原理就不再赘述,具体实现如下:
1 class TokenEmbedding(nn.Module): 2 def __init__(self, vocab_size, hidden_size, pad_token_id=0, initializer_range=0.02): 3 super(TokenEmbedding, self).__init__() 4 self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=pad_token_id) 5 self._reset_parameters(initializer_range) 6 7 def forward(self, input_ids): 8 """ 9 :param input_ids: shape : [input_ids_len, batch_size]10 :return: shape: [input_ids_len, batch_size, hidden_size]11 """12 return self.embedding(input_ids)13 14 def _reset_parameters(self, initializer_range):15 for p in self.parameters():16 if p.dim() > 1:17 normal_(p, mean=0.0, std=initializer_range)在上述代码中,第4行中的padding_idx是用来指定序列中用于padding处理的索引编号,一般来说默认都是0。在指定padding_idx后,如果输入序列中有0,那么对应位置的向量就会全是0。当然,这一步掌柜认为不做也可以,因为在计算自主力权重的时候会通过padding_mask向量来去掉这部分内容,具体可参见[2]。第5行代码便是用给定的方式来初始化参数,当然这几乎不会用到。因为不管是在下游任务中微调,还是继续通过NSL和MLM这两个任务来训练模型参数,我们大多数情况下都会再开源的BERT模型参数上进行,而不是从头再来。
2.2.2 Positional Embedding
对于Positional Embedding来说,其作用便是用来解决自注意力机制不能捕捉到文本序列内部各个位置之间顺序的问题。关于这部分内容原理的介绍,可以参见文章[3]。不同于Transformer中Positional Embedding的实现方式,在BERT中Positional Embedding并没有采用固定的变换公式来计算每个位置上的值,而是采用了类似普通Embedding的方式来为每个位置生成一个向量,然后随着模型一起训练。因此,这一操作就限制了在使用预训练的中文BERT模型时,最大的序列长度只能是512,因为在训练时只初始化了512个位置向量。具体地,其实现代码如下:
xxxxxxxxxx 1 class PositionalEmbedding(nn.Module): 2 """ 3 位置编码。 4 *** 注意: Bert中的位置编码完全不同于Transformer中的位置编码, 5 前者本质上也是一个普通的Embedding层,而后者是通过公式计算得到, 6 而这也是为什么Bert只能接受长度为512字符的原因,因为位置编码的最大size为512 *** 7 # Since the position embedding table is a learned variable, we create it 8 # using a (long) sequence length `max_position_embeddings`. The actual 9 # sequence length might be shorter than this, for faster training of10 # tasks that do not have long sequences.11 ———————— GoogleResearch12 https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/modeling.py13 """14 def __init__(self, hidden_size, max_position_embeddings=512, initializer_range=0.02):15 super(PositionalEmbedding, self).__init__()16 self.embedding = nn.Embedding(max_position_embeddings, hidden_size)17 18 def forward(self, position_ids):19 """20 :param position_ids: [1,position_ids_len]21 :return: [position_ids_len, 1, hidden_size]22 """23 return self.embedding(position_ids).transpose(0, 1)从上述代码可以看出,其本质上就是一个普通的Embedding层,只是在这一场景下作者赋予了它另外的含义,即序列中的每一个位置有自己独属的向量表示。同时, 在默认配置中,第16行中的max_position_embeddings值为512。
2.2.3 Segment Embedding
Segment Embedding的原理及目的掌柜在上一篇文章中[1]已经详细介绍过,总结起来就是为了满足下游任务中存在需要两句话同时输入到模型中的场景,即可以看成是对输入的两个序列分别赋予一个位置向量用以区分各自所在的位置。这一点可以和上面的Positional Embedding进行类比。具体地,其实现代码如下:
xxxxxxxxxx 1 class SegmentEmbedding(nn.Module): 2 def __init__(self, type_vocab_size, hidden_size, initializer_range=0.02): 3 super(SegmentEmbedding, self).__init__() 4 self.embedding = nn.Embedding(type_vocab_size, hidden_size) 5 6 def forward(self, token_type_ids): 7 """ 8 9 :param token_type_ids: shape: [token_type_ids_len, batch_size]10 :return: shape: [token_type_ids_len, batch_size, hidden_size]11 """12 return self.embedding(token_type_ids)在上述代码中,type_vocab_size的默认值为2,即只用于区分两个序列的不同位置。
2.2.4 Bert Embeddings
在完成Token、Positional、Segment Embedding这3个部分的代码之后,只需要将每个部分的结果相加即可得到最终的Input Embedding作为模型的输入,如图3所示。
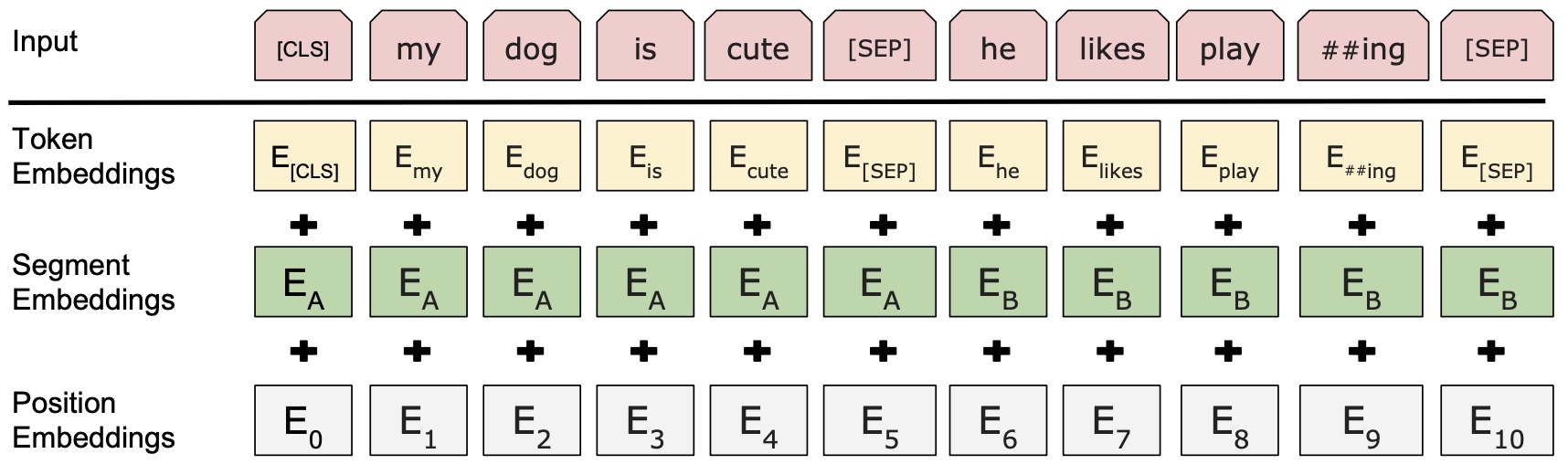
具体地,其代码实现为:
xxxxxxxxxx 1 class BertEmbeddings(nn.Module): 2 """ 3 BERT Embedding which is consisted with under features 4 1. TokenEmbedding : normal embedding matrix 5 2. PositionalEmbedding : normal embedding matrix 6 2. SegmentEmbedding : adding sentence segment info, (sent_A:1, sent_B:2) 7 sum of all these features are output of BERTEmbedding 8 """ 9 10 def __init__(self, config):11 super().__init__()12 self.word_embeddings = TokenEmbedding(13 vocab_size=config.vocab_size,14 hidden_size=config.hidden_size,15 pad_token_id=config.pad_token_id,16 initializer_range=config.initializer_range)17 # return shape [src_len,batch_size,hidden_size]18 19 self.position_embeddings = PositionalEmbedding(20 max_position_embeddings=config.max_position_embeddings,21 hidden_size=config.hidden_size,22 initializer_range=config.initializer_range)23 # return shape [src_len,1,hidden_size]24 25 self.token_type_embeddings = SegmentEmbedding(26 type_vocab_size=config.type_vocab_size,27 hidden_size=config.hidden_size,28 initializer_range=config.initializer_range)29 # return shape [src_len,batch_size,hidden_size]30 31 self.LayerNorm = nn.LayerNorm(config.hidden_size)32 self.dropout = nn.Dropout(config.hidden_dropout_prob)33 self.register_buffer("position_ids",34 torch.arange(config.max_position_embeddings).expand((1, -1)))35 # shape: [1, max_position_embeddings]在上述代码中,config是传入的一个配置类,里面各个类成员就是BERT中对应的模型参数。第12、19、25行代码便是用来分别定义图3中的3部分Embedding。第33行代码是用来生成一个默认的位置id,即[0,1,....,512],在后续可以通过self.position_ids来进行调用。
进一步,其前向传播过程代码为:
xxxxxxxxxx 1 def forward(self, 2 input_ids=None, 3 position_ids=None, 4 token_type_ids=None): 5 src_len = input_ids.size(0) 6 token_embedding = self.word_embeddings(input_ids) 7 # shape:[src_len,batch_size,hidden_size] 8 9 if position_ids is None:10 position_ids = self.position_ids[:, :src_len] # [1,src_len]11 positional_embedding = self.position_embeddings(position_ids)12 # [src_len, 1, hidden_size]13 14 if token_type_ids is None:15 token_type_ids = torch.zeros_like(input_ids,16 device=self.position_ids.device)# [src_len, batch_size]17 segment_embedding = self.token_type_embeddings(token_type_ids)18 # [src_len,batch_size,hidden_size]19 20 embeddings = token_embedding + positional_embedding + segment_embedding21 #[src_len,batch_size,hidden_size] + [src_len,1,hidden_size]+[src_len,batch_size,hidden_size]22 embeddings = self.LayerNorm(embeddings) # [src_len, batch_size, hidden_size]23 embeddings = self.dropout(embeddings)24 return embeddings在上述代码中,input_ids表示输入序列的原始token id,即根据词表映射后的索引,其形状为[src_len, batch_size];position_ids是位置序列,本质就是[0,1,2,3,...,src_len-1],其形状为[1,src_len];token_type_ids用于不同序列之间的分割,例如[0,0,0,0,1,1,1,1]用于区分前后不同的两个句子,形状为[src_len,batch_size]。
同时,第9-10代码表示当模型输入的position_ids为空时,需要根据输入序列的长度来生成一个位置序列(其实这部分输入仅作为内部实现即可,因为它只是[0,1,..,src_len-1]的一串数字。同理,第14行代码表示当模型输入仅包含一个序列(如文本分类)且token_type_ids为空时,那么可以通过15-16行代码来生成一个全0向量。第20-23行代码则是用来将三部分Embeeding的结果相加。
2.3 BertAttention实现
在实现完Input Embedding部分的代码后,下面就可以着手来实现BertEncoder了。如图4所示,整个BertEncoder由多个BertLayer堆叠形成;而BertLayer又是由BertOutput、BertIntermediate和BertAttention这3个部分组成;同时BertAttention是由BertSelfAttention和BertSelfOutput所构成。
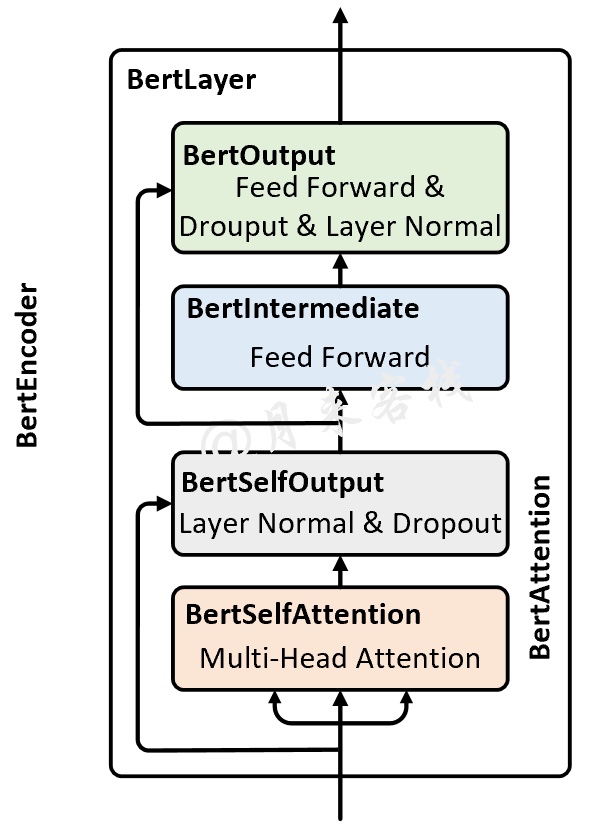
接下来,我们就以图4中从下到上的顺序来依次对每个部分进行实现。
2.4 BertAttention实现
对于BertAttention来说,需要明白的是其核心就是在Transformer中所提出来的self-attention机制,也就是图4中的BertSelfAttention模块;其次再是一个残差连接和标准化操作。对于BertSelfAttention的实现,其代码如下
xxxxxxxxxx 1 class BertSelfAttention(nn.Module): 2 """ 3 实现多头注意力机制,对应的是GoogleResearch代码中的attention_layer方法 4 https://github.com/google- research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/modeling.py#L558 5 """ 6 def __init__(self, config): 7 super(BertSelfAttention, self).__init__() 8 self.multi_head_attention = MyMultiheadAttention(embed_dim=config.hidden_size, 9 num_heads=config.num_attention_heads,10 dropout=config.attention_probs_dropout_prob)11 12 def forward(self, query, key, value, attn_mask=None, key_padding_mask=None):13 """14 :param query: # [tgt_len, batch_size, hidden_size], tgt_len 表示目标序列的长度15 :param key: # [src_len, batch_size, hidden_size], src_len 表示源序列的长度16 :param value: # [src_len, batch_size, hidden_size], src_len 表示源序列的长度17 :param key_padding_mask: [batch_size, src_len], src_len 表示源序列的长度18 :return:19 attn_output: [tgt_len, batch_size, hidden_size]20 attn_output_weights: # [batch_size, tgt_len, src_len]21 """22 return self.multi_head_attention(23 query, key, value, attn_mask=attn_mask, key_padding_mask=key_padding_mask)如上所示所示便是BertSelfAttention的实现代码,其对应的就是GoogleResearch[4]代码中的attention_layer方法。正如前面所说,BertSelfAttention本质上就是Transformer模型中的self-attention模块,具体原理可参见文章[3],这里就不再赘述。
对于BertSelfOutput的实现,其主要就是层Dropout、标准化和残差连接三个操作,代码如下:
xxxxxxxxxx 1 class BertSelfOutput(nn.Module): 2 def __init__(self, config): 3 super().__init__() 4 self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=1e-12) 5 self.dropout = nn.Dropout(config.hidden_dropout_prob) 6 7 def forward(self, hidden_states, input_tensor): 8 """ 9 :param hidden_states: [src_len, batch_size, hidden_size]10 :param input_tensor: [src_len, batch_size, hidden_size]11 :return: [src_len, batch_size, hidden_size]12 """13 hidden_states = self.dropout(hidden_states)14 hidden_states = self.LayerNorm(hidden_states + input_tensor)15 return hidden_states接下来就是对BertAttention部分的实现,其由BertSelfAttention和BertSelfOutput这两个类构成,代码如下:
xxxxxxxxxx 1 class BertAttention(nn.Module): 2 def __init__(self, config): 3 super().__init__() 4 self.self = BertSelfAttention(config) 5 self.output = BertSelfOutput(config) 6 7 def forward(self, 8 hidden_states, 9 attention_mask=None):10 """11 :param hidden_states: [src_len, batch_size, hidden_size]12 :param attention_mask: [batch_size, src_len]13 :return: [src_len, batch_size, hidden_size]14 """15 self_outputs = self.self(hidden_states,16 hidden_states,17 hidden_states,18 attn_mask=None,19 key_padding_mask=attention_mask)20 # self_outputs[0] shape: [src_len, batch_size, hidden_size]21 attention_output = self.output(self_outputs[0], hidden_states)22 return attention_output在上述代码中,第8行的hidden_states就是Input Embedding处理后的结果;第9行的attention_mask就是同一个batch中不同长度序列的padding信息,具体可以参加文章[2];第15行就是自注意力机制的输出结果;第21行便是执行BertSelfOutput中的3个操作。
2.5 BertLayer实现
根据图4可知,BertLayer里面还有BertOutput和BertIntermediate这两个模块,因此下面先来实现这两个部分。
对于BertIntermediate来说也就是一个普通的全连接层,因此实现起来也非常简单,代码如下:
xxxxxxxxxx 1 class BertIntermediate(nn.Module): 2 def __init__(self, config): 3 super().__init__() 4 self.dense = nn.Linear(config.hidden_size, config.intermediate_size) 5 if isinstance(config.hidden_act, str): 6 self.intermediate_act_fn = get_activation(config.hidden_act) 7 else: 8 self.intermediate_act_fn = config.hidden_act 9 10 def forward(self, hidden_states):11 """12 # :param hidden_states: [src_len, batch_size, hidden_size]13 :return: [src_len, batch_size, intermediate_size]14 """15 hidden_states = self.dense(hidden_states) # [src_len, batch_size, intermediate_size]16 if self.intermediate_act_fn is None:17 hidden_states = hidden_states18 else:19 hidden_states = self.intermediate_act_fn(hidden_states)20 return hidden_states在上述代码中,第6行用来根据指定参数获取激活函数。
进一步,对于BertOutput来说,其包含有其包含有一个全连接层和残差连接,实现代码如下:
xxxxxxxxxx 1 class BertOutput(nn.Module): 2 def __init__(self, config): 3 super().__init__() 4 self.dense = nn.Linear(config.intermediate_size, config.hidden_size) 5 self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=1e-12) 6 self.dropout = nn.Dropout(config.hidden_dropout_prob) 7 8 def forward(self, hidden_states, input_tensor): 9 """10 :param hidden_states: [src_len, batch_size, intermediate_size]11 :param input_tensor: [src_len, batch_size, hidden_size]12 :return: [src_len, batch_size, hidden_size]13 """14 hidden_states = self.dense(hidden_states) # [src_len, batch_size, hidden_size]15 hidden_states = self.dropout(hidden_states)16 hidden_states = self.LayerNorm(hidden_states + input_tensor)17 return hidden_states在上述代码中,第8行里hidden_states指的就是BertIntermediate模块的输出,而input_tensor则是BertAttention部分的输出。
在实现完这两个部分的代码后,便可以通过BertAttention、BertIntermediate和BertOutput这3个部分来实现组合的BertLayer部分,代码如下:
xxxxxxxxxx 1 class BertLayer(nn.Module): 2 def __init__(self, config): 3 super().__init__() 4 self.bert_attention = BertAttention(config) 5 self.bert_intermediate = BertIntermediate(config) 6 self.bert_output = BertOutput(config) 7 8 def forward(self, 9 hidden_states,10 attention_mask=None):11 """12 :param hidden_states: [src_len, batch_size, hidden_size]13 :param attention_mask: [batch_size, src_len]14 :return: [src_len, batch_size, hidden_size]15 """16 attention_output = self.bert_attention(hidden_states, attention_mask)17 # [src_len, batch_size, hidden_size]18 intermediate_output = self.bert_intermediate(attention_output)19 # [src_len, batch_size, intermediate_size]20 layer_output = self.bert_output(intermediate_output, attention_output)21 # [src_len, batch_size, hidden_size]22 return layer_output从上述代码中可以发现,对于BertLayer的实现来说其整体逻辑也并不太复杂,就是根据BertAttention、BertOutput和BertIntermediate这三部分构造而来;同时每个部分输出后的维度掌柜也都进行了标注以便大家进行理解。
到此,对于BertLayer部分的实现就介绍完了,下面继续来看如何实现BERT。
2.6 BERT模型实现
根据图2所示可知,BERT主要由Input Embedding和BertEncoder这两部分构成;而BertEncoder是有多个BertLayer堆叠所形成,因此需要先实现BertEncoder,代码如下:
xxxxxxxxxx 1 class BertEncoder(nn.Module): 2 def __init__(self, config): 3 super().__init__() 4 self.config = config 5 self.bert_layers = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)]) 6 7 def forward( 8 self, 9 hidden_states,10 attention_mask=None):11 """12 :param hidden_states: [src_len, batch_size, hidden_size]13 :param attention_mask: [batch_size, src_len]14 :return:15 """16 all_encoder_layers = []17 layer_output = hidden_states18 for i, layer_module in enumerate(self.bert_layers):19 layer_output = layer_module(layer_output,20 attention_mask)21 # [src_len, batch_size, hidden_size]22 all_encoder_layers.append(layer_output)23 return all_encoder_layers在上述代码中,第5行便是用来定义多个BertLayer;第18-22行用来循环计算多层BertLayer堆叠后的输出结果。最后,只需要按需将BertEncoder部分的输出结果输入到下游任务即可。
进一步,在将BertEncoder部分的输出结果输入到下游任务前,需要将其进行略微的处理,代码如下:
xxxxxxxxxx 1 class BertPooler(nn.Module): 2 def __init__(self, config): 3 super().__init__() 4 self.dense = nn.Linear(config.hidden_size, config.hidden_size) 5 self.activation = nn.Tanh() 6 self.config = config 7 8 def forward(self, hidden_states): 9 """10 :param hidden_states: [src_len, batch_size, hidden_size]11 :return: [batch_size, hidden_size]12 """13 if self.config.pooler_type == "first_token_transform":14 token_tensor = hidden_states[0, :].reshape(-1, self.config.hidden_size)15 elif self.config.pooler_type == "all_token_average":16 token_tensor = torch.mean(hidden_states, dim=0)17 pooled_output = self.dense(token_tensor) # [batch_size, hidden_size]18 pooled_output = self.activation(pooled_output)19 return pooled_output在上述代码中,第13-14行代码用来取BertEncoder输出的第一个位置([cls]位置),例如在进行文本分类时可以取该位置上的结果进行下一步的分类处理;第15-16行是掌柜自己加入的一个选项,表示取所有位置的平均值,当然我们也可以根据自己的需要在添加下面添加其它的方式;最后,17-19行就是一个普通的全连接层。
紧接着,基于上述所有实现便可以搭建完成整个BERT的主体结构,代码如下:
xxxxxxxxxx 1 class BertModel(nn.Module): 2 3 def __init__(self, config): 4 super().__init__() 5 self.bert_embeddings = BertEmbeddings(config) 6 self.bert_encoder = BertEncoder(config) 7 self.bert_pooler = BertPooler(config) 8 self.config = config 9 10 def forward(self,11 input_ids=None,12 attention_mask=None,13 token_type_ids=None,14 position_ids=None):15 """16 :param input_ids: [src_len, batch_size]17 :param attention_mask: [batch_size, src_len]18 :param token_type_ids: [batch_size, src_len]19 :param position_ids: [1,src_len]20 :return:21 """22 embedding_output = self.bert_embeddings(input_ids=input_ids,23 position_ids=position_ids,24 token_type_ids=token_type_ids)25 all_encoder_outputs = self.bert_encoder(embedding_output,26 attention_mask=attention_mask)27 sequence_output = all_encoder_outputs[-1] # 取最后一层28 pooled_output = self.bert_pooler(sequence_output)# [batch_size, hidden_size]29 # 默认是最后一层的first token 即[cls]位置经dense + tanh 后的结果30 return pooled_output, all_encoder_outputs如上代码所示便是整个BERT部分的实现,可以发现在厘清了整个思路后这部分代码理解起来就相对容易了。第22-24行便是Embedding后的输出结果;第25-26行是整个BERT编码部分的输出;第27-28行便是处理得到整个BERT网络的输出。到此,对于整个BERT主体部分的代码实现就介绍完了。
以上代码的实现均参考自[4] [5] [6],大家有兴趣也可以自行阅读研究。
4 总结
在本篇文章中,掌柜首先和大家一起回顾了BERT的整个网络结构;然后一步一步从Input Embedding、BertAttention、BertLayer再到BertEncoder来详细介绍了整个BERT模型的实现。需要提醒各位读者朋友的是,在阅读本文的过程中最好是结合着每个部分的输出结果(包括形状和意义)来进行理解。在下一篇文章中,掌柜将会介绍如何在现有代码的基础上,实现一个基于BERT的文本分类模型,并同时用开源的预训练参数来对模型进行初始化。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加掌柜微信nulls8或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[2]This post is all you need(③网络结构与自注意力实现)
[3]This post is all you need(②位置编码与编码解码过程)
[4]Google Research https://github.com/google-research/bert
[5]BERT https://huggingface.co/transformers/model_doc/bert.html#bertmodel
[6] https://github.com/codertimo/BERT-pytorch


