1 引言
各位朋友大家好,欢迎来到月来客栈。经过前面一系列文章的介绍,相信大家对于Transformer的原理应该有了一个比较清晰的认识。不过要想做到灵活运用Transformer结构,那就还得再看看其它情况下的运用场景。在接下来的这篇文章中,笔者将会以AG_News数据集为例,来搭建一个基于Transformer结构的文本分类模型。

如图1所示便是一个基于Transformer结构的文本分类模型。不过准确的说应该只是一个基于Transformer中Encoder的文本分类模型。这是因为在文本分类任务中并没有解码这一过程,所以我们只需要将Encoder编码得到的向量输入到分类器中进行分类即可。同时需要注意的是,Encoder部分最后输出张量的形状为[batch_size,d_model,src_len](图1中Encoder输出的src_len为7),我们需要根据相应策略来进行下一步的处理,具体见后文。
2 数据预处理
2.1 语料介绍
在正式介绍模型之前,我们还是先来看看后续所要用到的AG_News数据集。AG_News新闻主题分类数据集是通过从原始语料库中选择 4 个最大的类构建的。每个类包含 30000 个训练样本和 1900 个测试样本。训练样本总数为 120000条,测试总数为 7600条。AG_News原始数据大概长这样:
1"3","Fears for T N pension after talks","Unions representing workers at Turner Newall say they are 'disappointed' after talks with stricken parent firm Federal Mogul."2"4","The Race is On: Second Private Team Sets Launch Date for Human Spaceflight (SPACE.com)","SPACE.com - TORONTO, Canada -- A second\team of rocketeers competing for the #36;10 million Ansari X Prize, a contest for\privately funded suborbital space flight, has officially announced the first\launch date for its manned rocket."3"4","Ky. Company Wins Grant to Study Peptides (AP)","AP - A company founded by a chemistry researcher at the University of Louisville won a grant to develop a method of producing better peptides, which are short chains of amino acids, the building blocks of proteins."上述一共包含有3个样本,每1行为1个样本。同时,所有样本均使用逗号作为分隔符,一共包含有 3 列,分别对应类标(1 到 4)、标题和新闻描述。在本篇文中中,我们暂时只使用新闻描述作为输入(当然也可以用title作为输入来进行分类)。
对于该数据的载入,你可以使用Pytorch中的方法来下载并使用[1]:
xxxxxxxxxx21from torchtext.datasets import AG_NEWS2train_iter = AG_NEWS(split='train')也可以自己下载原始数据来进行处理。在这篇文章中,为了延续使用与熟悉上一篇文章[2]中介绍的预处理代码,所以这里我们暂不使用Pytorch内置的代码。
2.2 数据集构建
由于分类模型数据集的构建过程并不复杂,所以这里笔者就只是简单的介绍一下即可,详细内容可参考文章[3] [4]中的内容。
第1步:定义tokenize
如果是对类似英文这样的语料进行处理,那就是直接按空格切分即可。但是需要注意的是要把其中的逗号、句号等也给分割出来。因此,这部分代码可以根据如下方式进行实现:
xxxxxxxxxx31def my_tokenizer(s):2 s = s.replace(',', " ,").replace(".", " .").replace("?", " ?").replace("!", " !")3 return s.split()可以看到,其实也非常简单。例如对于如下文本来说
xxxxxxxxxx11A company founded by a chemistry researcher其tokenize后的结果为:
xxxxxxxxxx11["A", "company", "founded", "by", "a", "chemistry", "researcher"]第2步:定义字符串清理
从2.1节中的示例语料中可以看到, 原始语料中有很多奇奇怪怪的字符,因此还需要对其稍微做一点处理。例如①只保留、数字、以及常用标点;②全部转换为小写字母;③把缩写还原等等。当然,你也可以自己再添加其它处理方式。具体代码如下:
xxxxxxxxxx161def clean_str(string):2 string = re.sub("[^A-Za-z0-9\-\?\!\.\,]", " ", string).lower()3 string = string.replace("that's", "that is")4 string = string.replace("isn't", "is not")5 string = string.replace("don't", "do not")6 string = string.replace("didn't", "did not")7 string = string.replace("won't", "will not")8 string = string.replace("can't", "can not")9 string = string.replace("you're", "you are")10 string = string.replace("they're", "they are")11 string = string.replace("you'll", "you will")12 string = string.replace("we'll", "we will")13 string = string.replace("what's", "what is")14 string = string.replace("i'm", "i am")15 string = string.replace("let's", "let us")16 return string第3步:建立词表
在介绍完tokenize和字符串清理的实现方法后,我们就可以正式通过torchtext.vocab中的Vocab方法来构建词典了,代码如下:
xxxxxxxxxx91def build_vocab(tokenizer, filepath, min_freq, specials=None):2 if specials is None:3 specials = ['<unk>', '<pad>']4 counter = Counter()5 with open(filepath, encoding='utf8') as f:6 for string_ in f:7 string_ = string_.strip().split('","')[-1][:-1]8 counter.update(tokenizer(clean_str(string_)))9 return Vocab(counter, min_freq=min_freq, specials=specials)在上述代码中,第3行代码用来指定特殊的字符;第5-8行代码用来遍历文件中的每一个样本(每行一个)并进行tokenize和计数,其中对于counter.update进行介绍可以参考[3];第9行则是返回最后得到词典。
在完成上述过程后,我们将得到一个Vocab类的实例化对象:
xxxxxxxxxx11{'<unk>': 0, '<pad>': 1, 'the': 2, '.': 3, ',': 4, 'a': 5, 'to': 6, 'of': 7, 'in': 8, 'and': 9, 'on': 10, 's': 11, 'for': 12, '-': 13, '39': 14, 'that': 15,.....}接下来,我们就需要定义一个类,并在类的初始化过程中根据训练语料完成字典的构建,代码如下:
xxxxxxxxxx171class LoadSentenceClassificationDataset():2 def __init__(self, train_file_path=None, # 训练集路径3 tokenizer=None,4 batch_size=2,5 min_freq=1, # 最小词频,去掉小于min_freq的词6 max_sen_len='same'): # 最大句子长度,默认设置其长度为整个数据集中最长样本的长度7 # max_sen_len = None时,表示按每个batch中最长的样本长度进行padding8 # 根据训练预料建立字典9 self.tokenizer = tokenizer10 self.min_freq = min_freq11 self.specials = ['<unk>', '<pad>']12 self.vocab = build_vocab(self.tokenizer,filepath=train_file_path,13 min_freq=self.min_freq,specials=self.specials)14 self.PAD_IDX = self.vocab['<pad>']15 self.UNK_IDX = self.vocab['<unk>']16 self.batch_size = batch_size17 self.max_sen_len = max_sen_len第4步:转换为Token序列
在得到构建的字典后,便可以通过如下函数来将训练集和测试集转换成Token序列:
x1 def data_process(self, filepath):2 """3 将每一句话中的每一个词根据字典转换成索引的形式,同时返回所有样本中最长样本的长度4 :param filepath: 数据集路径5 :return:6 """78 raw_iter = iter(open(filepath, encoding="utf8"))9 data = []10 max_len = 011 for raw in raw_iter:12 line = raw.rstrip("\n").split('","')13 s, l = line[-1][:-1], line[0][1:]14 s = clean_str(s)15 tensor_ = torch.tensor([self.vocab[token] for token in16 self.tokenizer(s)], dtype=torch.long)17 l = torch.tensor(int(l) - 1, dtype=torch.long)18 max_len = max(max_len, tensor_.size(0))19 data.append((tensor_, l))20 return data, max_len在上述代码中,第11-4行分别用来将原始输入序列转换为对应词表中的Token形式。在处理完成后,就会得到类似如下的结果:
xxxxxxxxxx51[(tensor([ 25, 65, 45, 1487, 5, 4062, 3291, 10, 2918, 20217,2 4, 1842, 4512, 1161, 15, 143, 140, 3658, 21658, 4762,3 40, 146, 409, 22, 8, 25, 65, 4, 16, 5,4 142, 287, 15, 4, 633, 39, 146, 409, 22, 5474,5 3, 40]), tensor(1)), .....]第5步:padding处理
由于对于不同的样本来说其对应的序列长度通常来说都是不同的,但是在将数据输入到相应模型时却需要保持同样的长度。因此在这里我们就需要对Token序列化后的样本进行padding处理,具体代码如下:
xxxxxxxxxx201def pad_sequence(sequences, batch_first=False, max_len=None, padding_value=0):2 max_size = sequences[0].size()3 trailing_dims = max_size[1:]4 length = max_len5 max_len = max([s.size(0) for s in sequences])6 if length is not None:7 max_len = max(length, max_len)8 if batch_first:9 out_dims = (len(sequences), max_len) + trailing_dims10 else:11 out_dims = (max_len, len(sequences)) + trailing_dims12 out_tensor = sequences[0].data.new(*out_dims).fill_(padding_value)13 for i, tensor in enumerate(sequences):14 length = tensor.size(0)15 # use index notation to prevent duplicate references to the tensor16 if batch_first:17 out_tensor[i, :length, ...] = tensor18 else:19 out_tensor[:length, i, ...] = tensor20 return out_tensor在上述代码中,max_len 表示 最大句子长度,默认为None,即在每个batch中以最长样本的长度对其它样本进行padding;当然同样也可以指定max_len的值为整个数据集中最长样本的长度进行padding处理。padding处理后的结果类似如下:
xxxxxxxxxx31tensor([[ 2, 342, 578, ..., 1, 1, 1],2 [ 32, 13, 14585, ..., 1, 1, 1],3 [ 1189, 11, 327, ..., 1, 1, 1],...)末尾的1即是padding的部分。
在定义完pad_sequence这个函数后,我们便可以通过它来对每个batch中的数据集进行padding处理:
xxxxxxxxxx111 def generate_batch(self, data_batch):2 batch_sentence, batch_label = [], []3 for (sen, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。4 batch_sentence.append(sen)5 batch_label.append(label)6 batch_sentence = pad_sequence(batch_sentence, # [batch_size,max_len]7 padding_value=self.PAD_IDX,8 batch_first=False,9 max_len=self.max_sen_len)10 batch_label = torch.tensor(batch_label, dtype=torch.long)11 return batch_sentence, batch_label第6步:构造DataLoade与使用示例
经过前面5步的操作,整个数据集的构建就算是已经基本完成了,只需要再构造一个DataLoader迭代器即可,代码如下:
xxxxxxxxxx101 def load_train_val_test_data(self, train_file_paths, test_file_paths):2 train_data, max_sen_len = self.data_process(train_file_paths) # 得到处理好的所有样本3 if self.max_sen_len == 'same':4 self.max_sen_len = max_sen_len5 test_data, _ = self.data_process(test_file_paths)6 train_iter = DataLoader(train_data, batch_size=self.batch_size, # 构造DataLoader7 shuffle=True, collate_fn=self.generate_batch)8 test_iter = DataLoader(test_data, batch_size=self.batch_size,9 shuffle=True, collate_fn=self.generate_batch)10 return train_iter, test_iter在上述代码中,第2-5行便是分别用来将训练集和测试集转换为Token序列;第6-9行则是分别构造2个DataLoader,其中generate_batch将作为一个参数传入来对每个batch的样本进行处理。在完成类LoadSentenceClassificationDataset所有的编码过程后,便可以通过如下形式进行使用:
xxxxxxxxxx91if __name__ == '__main__':2 path = "./data/ag_news_csv/test.csv"3 data_loader = LoadSentenceClassificationDataset(train_file_path=path,4 tokenizer=my_tokenizer,5 max_sen_len=None)6 data, max_len = data_loader.data_process(path)7 train_iter, test_iter = data_loader.load_train_val_test_data(path, path)8 for sample, label in train_iter:9 print(sample.shape) # [seq_len,batch_size]最后,由于Encoder只会在padding部分有mask操作,所以每个样本的key_padding_mask向量我们在训练部分再生成即可。下面,我们正式进入到文本分类模型部分的介绍。
3 基于Transformer的文本分类模型
3.1 网络结构
总体来说,基于Transformer的翻译模型的网络结构其实就是图1所展示的所有部分,当然你还可以使用多个Encoder进行堆叠。最后,只需要将Encdder的输出喂入到一个softmax分类器即可完成分类任务。不过这里有两个细节的地方需要大家注意:
①根据前一篇文章[5]的介绍可知,Encoder在编码结束后输出的形状为[src_len,batch_size,embed_dim](这里的src_len也可以理解为LSTM中time step的概念)。因此,在构造最后分类器的输入时就可以有多种不同的形式,例如只取最后一个位置上的向量、或者是取所有位置向量的平均(求和)等都可以。后面笔者也会将这3种方式都实现供大家参考。
②由于每个样本长度给不相同,因此在对样本进行padding的时候就有两种方式。一般来说在大多数模型中多需要保持所有的样本具有相同的长度,不过由于这里我们使用的是自注意力的编码机制,因此只需要保持同一个batch中的样本长度一致即可。不过后面笔者对这两种方式都进行了实现,只需要通过max_sen_len这个参数来控制即可。
首先,我们需要定义一个名为ClassificationModel的类,其前向传播过程代码如下所示:
xxxxxxxxxx201class ClassificationModel(nn.Module):2 def __init__(self, vocab_size=None,3 d_model=512, nhead=8,4 num_encoder_layers=6,5 dim_feedforward=2048,6 dim_classification=64,7 num_classification=4,8 dropout=0.1):9 super(ClassificationModel, self).__init__()10 self.pos_embedding = PositionalEncoding(d_model=d_model, dropout=dropout)11 self.src_token_embedding = TokenEmbedding(vocab_size, d_model)12 encoder_layer = MyTransformerEncoderLayer(d_model, nhead,13 dim_feedforward,14 dropout)15 encoder_norm = nn.LayerNorm(d_model)16 self.encoder = MyTransformerEncoder(encoder_layer,17 num_encoder_layers, encoder_norm)18 self.classifier = nn.Sequential(nn.Linear(d_model, dim_classification),19 nn.Dropout(dropout),20 nn.Linear(dim_classification, num_classification))在上述代码中,第10-17行用来定义Transformer中的Encoder;第18-20行用来定义一个分类器。整个网络的前向传播过程如下:
xxxxxxxxxx211 def forward(self,2 src, # [src_len, batch_size]3 src_mask=None,4 src_key_padding_mask=None, # [batsh_size, src_len]5 concat_type='sum' # 解码之后取所有位置相加,还是最后一个位置作为输出6 ):7 src_embed = self.src_token_embedding(src) # [src_len, batch_size, embed_dim]8 src_embed = self.pos_embedding(src_embed) # [src_len, batch_size, embed_dim]9 memory = self.encoder(src=src_embed,10 mask=src_mask,11 src_key_padding_mask=src_key_padding_mask)12 # [src_len,batch_size,embed_dim]13 if concat_type == 'sum':14 memory = torch.sum(memory, dim=0)15 elif concat_type == 'avg':16 memory = torch.sum(memory, dim=0) / memory.size(0)17 else:18 memory = memory[-1, ::] # 取最后一个时刻19 # [src_len, batch_size, num_heads * kdim] <==> [src_len,batch_size,embed_dim]20 out = self.classifier(memory) # 输出logits21 return out # [batch_size, num_class]在上述代码中,第7-11行用来执行编码器的前向传播过程;第13-18行便是用来选择以何种方式来选择分类器的输入,经笔者实验后发现取各个位置的平均值效果最好;第20-21行便是将经过分类器后的输出进行返回。
在定义完logits的前向传播过后,便可以通过如下形式进行使用:
xxxxxxxxxx121if __name__ == '__main__':2 src_len = 73 batch_size = 24 dmodel = 325 num_head = 46 src = torch.tensor([[4, 3, 2, 6, 0, 0, 0],7 [5, 7, 8, 2, 4, 0, 0]]).transpose(0, 1) # 转换成 [src_len, batch_size]8 src_key_padding_mask = torch.tensor([[True, True, True, True, False, False, False],9 [True, True, True, True, True, False, False]])10 model = ClassificationModel(vocab_size=10, d_model=dmodel, nhead=num_head)11 logits = model(src, src_key_padding_mask=src_key_padding_mask)12 print(logits.shape) # torch.Size([2, 4])3.2 模型训练
在定义完成整个分类模型的网络结构后下面就可以开始训练模型了。由于这部分代码较长,所以下面笔者依旧以分块的形式进行介绍:
第1步:载入数据集
xxxxxxxxxx81def train_model(config):2 data_loader = LoadSentenceClassificationDataset(config.train_corpus_file_paths,3 my_tokenizer,4 batch_size=config.batch_size,5 min_freq=config.min_freq,6 max_sen_len=config.max_sen_len)7 train_iter, test_iter = data_loader.load_train_val_test_data(8 config.train_corpus_file_paths, config.test_corpus_file_paths)首先我们可以根据前面的介绍,通过类LoadSentenceClassificationDataset来载入数据集,其中config中定义了模型所涉及到的所有配置参数。同时,可以通过max_sen_len参数来控制padding时保持所有样本一样还是仅在每个batch内部一样。
第2步:定义模型并初始化权重
xxxxxxxxxx121 classification_model = ClassificationModel(vocab_size=len(data_loader.vocab),2 d_model=config.d_model,3 nhead=config.num_head,4 num_encoder_layers=config.num_encoder_layers,5 dim_feedforward=config.dim_feedforward,6 dim_classification=config.dim_classification,7 num_classification=config.num_class,8 dropout=config.dropout)910 for p in classification_model.parameters():11 if p.dim() > 1:12 nn.init.xavier_uniform_(p)在载入数据后,便可以定义一个翻译模型ClassificationModel,并根据相关参数对其进行实例化;同时,可以对整个模型中的所有参数进行一个初始化操作。
第3步:定义损失学习率与优化器
xxxxxxxxxx61 loss_fn = torch.nn.CrossEntropyLoss()2 learning_rate = CustomSchedule(config.d_model)3 optimizer = torch.optim.Adam(classification_model.parameters(),4 lr=0.,5 betas=(config.beta1, config.beta2), 6 eps=config.epsilon)在上述代码中,第1行是定义交叉熵损失函数;第2行代码则是论文中所提出来的动态学习率计算过程,其计算公式为:
具体实现代码为:
xxxxxxxxxx121class CustomSchedule(nn.Module):2 def __init__(self, d_model, warmup_steps=4000):3 super(CustomSchedule, self).__init__()4 self.d_model = torch.tensor(d_model, dtype=torch.float32)5 self.warmup_steps = warmup_steps6 self.step = 1.78 def __call__(self):9 arg1 = self.step ** -0.510 arg2 = self.step * (self.warmup_steps ** -1.5)11 self.step += 1.12 return (self.d_model ** -0.5) * min(arg1, arg2)通过CustomSchedule,就能够在训练过程中动态的调整学习率。学习率随step增加而变换的结果如图2所示:
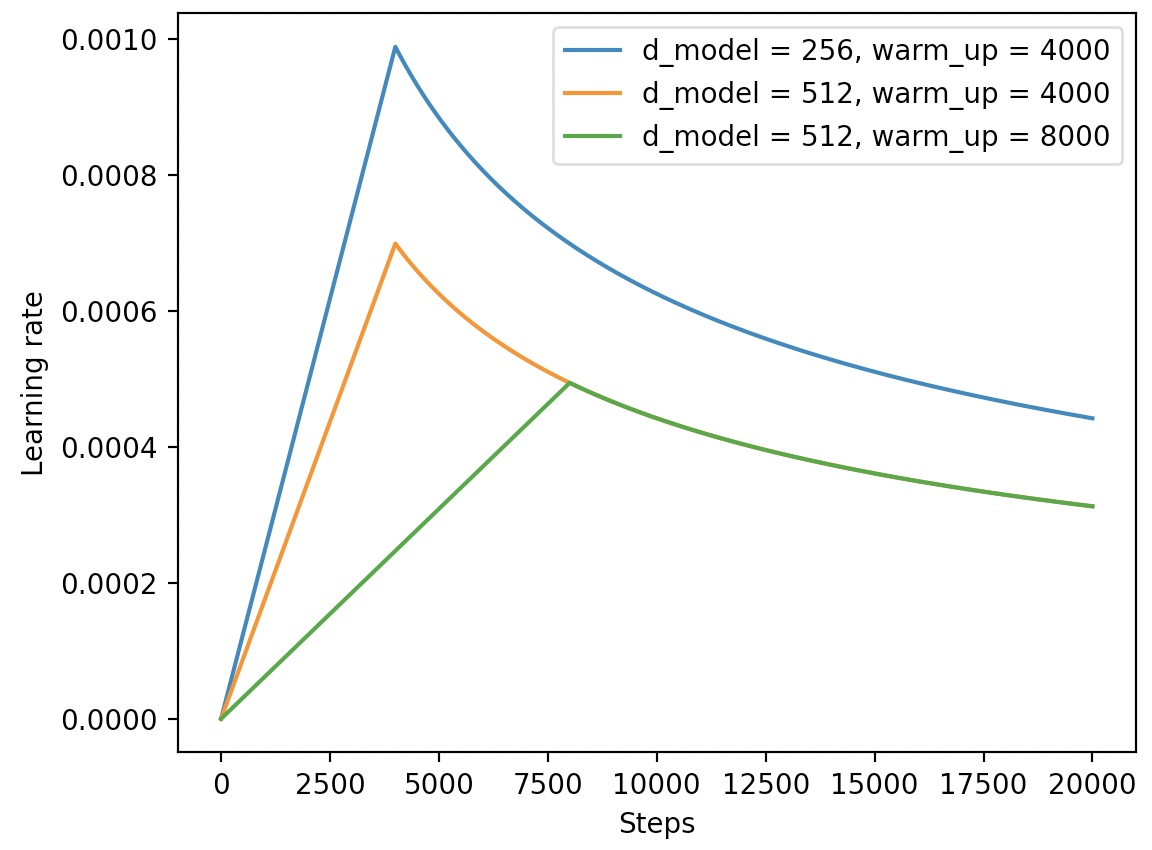
从图2可以看出,在前warm_up个step中,学习率是线性增长的,在这之后便是非线性下降,直至收敛与0.0004。
第4步:开始训练
xxxxxxxxxx251 for epoch in range(config.epochs):2 losses = 03 start_time = time.time()4 for idx, (sample, label) in enumerate(train_iter):5 sample = sample.to(config.device) # [src_len, batch_size]6 label = label.to(config.device)7 padding_mask = (sample == data_loader.PAD_IDX).transpose(0, 1)8 logits = classification_model(sample,9 src_key_padding_mask=padding_mask) 10 # [batch_size,num_class]11 optimizer.zero_grad()12 loss = loss_fn(logits, label)13 loss.backward()14 lr = learning_rate()15 for p in optimizer.param_groups:16 p['lr'] = lr17 optimizer.step()18 losses += loss.item()19 acc = (logits.argmax(1) == label).float().mean()20 if idx % 10 == 0:21 print(22 f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], Train loss :{loss.item():.3f}, Train acc: {acc:.3f}")23 end_time = time.time()24 train_loss = losses / len(train_iter)25 print(f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Epoch time = {(end_time - start_time):.3f}s")在上述代码中,第7行代码用来生成每个样本对应的padding mask向量;第15-16行是将每个step更新后的学习率送入到模型中。以下便是模型训练过程中的输出:
xxxxxxxxxx71 Epoch: 9, Batch: [410/469], Train loss 0.186, Train acc: 0.9382 Epoch: 9, Batch: [420/469], Train loss 0.150, Train acc: 0.9383 Epoch: 9, Batch: [430/469], Train loss 0.269, Train acc: 0.9414 Epoch: 9, Batch: [440/469], Train loss 0.197, Train acc: 0.9255 Epoch: 9, Batch: [450/469], Train loss 0.245, Train acc: 0.9176 Epoch: 9, Batch: [460/469], Train loss 0.272, Train acc: 0.9027 Accuracy on test 0.886以上完整代码可参见[7]。
4 总结
在这篇文章中,笔者首先介绍了文本分类模型的数据预处理过程,然后再一步步地通过编码实现了整个数据集的构造过程;接着笔者介绍了基于Transformer结构的文本分类模型的整体构成,然后循序渐进地带着各位读者来实现了整个分类模型,包括基础结构的搭建、模型训练的详细实现、动态学习率的调整实现等;最后介绍了如何来实现模型在实际预测过程中的处理流程等。在下一篇文章中,笔者将会介绍如何基于Transformer结构来搭建一个对联模型(本质上和翻译模型一样),这同时也是介绍Transformer内容的最后一篇文章。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加笔者微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
[2] This post is all you need(基于Transformer的翻译模型)
[3] 你还在手动构造词表?试试torchtext.vocab
[5] This post is all you need(Transformer的实现过程)
[7] https://github.com/moon-hotel/TransformerClassification


