通过这篇文章,你能够更加清楚地知道如何在下游任务中进行BERT模型的微调,以及如何通过BERT模型来完成文本蕴含任务。
1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
经过前面一篇文章[1]的介绍,相信大家对于如何利用BERT预训练模型来进行单文本分类的整体流程已经有了清晰的认识。当然BERT的能力显然不止于此,因此在这篇文章中,掌柜将会介绍第二个下游任务的微调场景,即如何基于BERT预训练模型来完成文本蕴含(文本对的分类)任务。所谓文本对分类指的就是同时给模型输入两句话,然后让模型来判断两句话之间的关系,所以本质上也就变成了一个分类任务。同时,鉴于第一个任务场景用到的是中文语料,因此在第二个场景中我们将会用英文语料进行示例。这样便于大家两者都能掌握。
总的来说,基于BERT的文本蕴含(文本对分类)任务同上一篇文章中介绍的单文本分类任务本质上没有任何不同,最终都是对一个文本序列进行分类。只是按照BERT模型的思想,文本对分类任务在数据集的构建过程中需要通过Segment Embedding来区分前后两个不同的序列,因此本篇文章的核心内容就在于如何构建数据集。总结起来,文本对的分类任务除了在模型输入上发生了变换,其它地方均与单文本分类任务一样。接下来,掌柜首先就来介绍如何构造文本分类的数据集。
以下所有完整示例代码均可从仓库 https://github.com/moon-hotel/BertWithPretrained 中获取!
2 数据预处理
2.1 输入介绍
在构建数据集之前,我们首先需要知道的是模型到底应该接收什么样的输入,然后才能构建出正确的数据形式。根据文章[2]的介绍可以知道BERT模型的输入如图1所示:
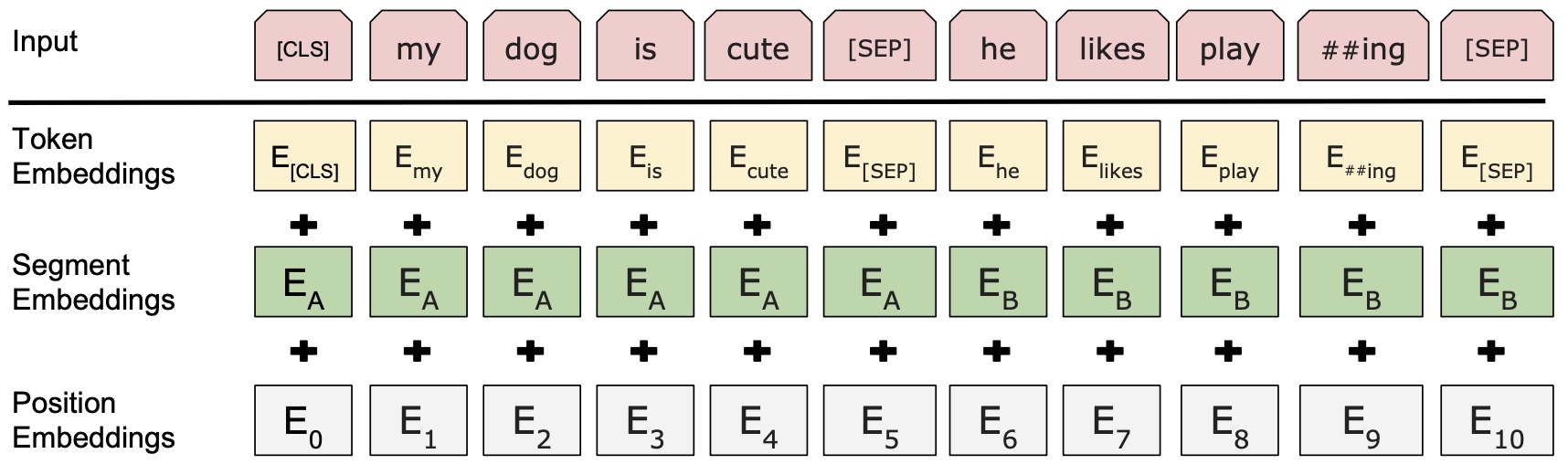
由于在文本对分类任务这个场景中模型的输入包含两个序列,因此在构建数据集的时候不仅仅需要进行Token Embedding操作,同时还要对两个序列进行Segment Embedding操作。对于Position Embedding来说在任何场景下都不需要对其指定输入,因为我们在代码实现时已经做了相应默认时的处理(同样见文章[2]第2.2.4节)。
因此,对于文本对分类这个场景来说:①需要构造原始文本对应的Token序列,然后在最前面加上一个[CLS]符,两个序列之间和末尾分别再加上一个[SEP]符;②根据两个序列各自的长度再构建一个类似[0,0,0,...,1,1,1,...]的token_type_ids向量。最后将两者均作为模型的输入即可。
2.2 语料介绍
在这里,我们使用到的是论文中所提到的MNLI(The Multi-Genre Natural Language Inference Corpus, 多类型自然语言推理数据库)自然语言推断任务数据集[3]。也就是给定前提(premise)语句和假设(hypothesis)语句,任务是预测前提语句是否包含假设(蕴含, entailment),与假设矛盾(矛盾,contradiction)或者两者都不(中立,neutral)。
如下所示便是部分原始示例数据:
xxxxxxxxxx21{"annotator_labels": ["entailment", "neutral", "entailment", "neutral", "entailment"], "genre": "oup", "gold_label": "entailment", "pairID": "82890e", "promptID": "82890", "sentence1": " From Home Work to Modern Manufacture", "sentence1_binary_parse": "( From ( ( Home Work ) ( to ( Modern Manufacture ) ) ) )", "sentence1_parse": "(ROOT (PP (IN From) (NP (NP (NNP Home) (NNP Work)) (PP (TO to) (NP (NNP Modern) (NNP Manufacture))))))", "sentence2": "Modern manufacturing has changed over time.", "sentence2_binary_parse": "( ( Modern manufacturing ) ( ( has ( changed ( over time ) ) ) . ) )", "sentence2_parse": "(ROOT (S (NP (NNP Modern) (NN manufacturing)) (VP (VBZ has) (VP (VBN changed) (PP (IN over) (NP (NN time))))) (. .)))" }2{"annotator_labels": ["neutral", "neutral", "entailment", "neutral", "neutral"], "genre": "nineeleven", "gold_label": "neutral", "pairID": "16525n", "promptID": "16525", "sentence1": "They were promptly executed.", "sentence1_binary_parse": "( They ( ( were ( promptly executed ) ) . ) )", "sentence1_parse": "(ROOT (S (NP (PRP They)) (VP (VBD were) (VP (ADVP (RB promptly)) (VBN executed))) (. .)))", "sentence2": "They were executed immediately upon capture.", "sentence2_binary_parse": "( They ( ( were ( ( executed immediately ) ( upon capture ) ) ) . ) )", "sentence2_parse": "(ROOT (S (NP (PRP They)) (VP (VBD were) (VP (VBN executed) (ADVP (RB immediately)) (PP (IN upon) (NP (NN capture))))) (. .)))"}由于该数据集同时也可用于其它任务中,因此除了我们需要的前提和假设两个句子和标签之外,还有每个句子的语法解析结构等等。在这里,下载完成数据后只需要执行项目中的format.py脚本即可将原始数据划分成训练集、验证集和测试集。格式化后的数据形式如下所示:
xxxxxxxxxx21From Home Work to Modern Manufacture_!_Modern manufacturing has changed over time._!_12They were promptly executed._!_They were executed immediately upon capture._!_2后台回复“数据集”即可获取网盘链接!
2.3 数据集预览
同样,在正式介绍如何构建数据集之前我们先通过一张图来了解一下整个构建的流程。假如我们现在有两个样本构成了一个batch,那么其整个数据的处理过程则如图2所示。

如图2所示,第1步需要将原始的数据样本进行分词(tokenize)处理;第2步再根据tokenize后的结果构造一个字典,不过在使用BERT预训练时并不需要我们自己来构造这个字典,直接使用相应开源模型中的vocab.txt文件构造字典即可,因为只有vocab.txt中每个字的索引顺序才与开源模型中每个字的Embedding向量一一对应的。第3步则是根据字典将tokenize后的文本序列转换为Token Id序列,同时分在Token Id序列的起始位置加上[CLS],在两个序列之间以及末尾加上[SEP]符号,并进行Padding。第4、5步则是根据第3步处理后的结果分别生成对应的token types ids和attention mask向量。
最后,在模型训练时只需要将第3、4和5步处理后的结果一起喂给模型即可。
2.4 数据集构建
第1步:定义tokenize
第1步需要完成的就是将输入进来的文本序列tokenize到单词级别,对于英文语料简单来说就是将每个单词和标点符号分开。不过具体的处理方式使用到的是一种叫做WordPiece的处理方式。在这里,我们可以借用transformers包中的BertTokenizer方法来完成,示例如下:
xxxxxxxxxx61from transformers import BertTokenizer2model_name = '../bert_base_uncased_english'3tokenizer = BertTokenizer.from_pretrained(model_name)4r = tokenizer.tokenize("From Home Work to Modern Manufacture. Modern manufacturing has changed over time.")5print(r)6['from', 'home', 'work', 'to', 'modern', 'manufacture', '.', 'modern', 'manufacturing', 'has', 'changed', 'over', 'time', '.']在上述代码中,第2-3行就是根据指定的路径(BERT预训练模型的路径)来载入一个tokenize模型;第6行便是tokenize后的结果。
同时,对于一些新词WordPiece也会将其拆分成合理的部分:
xxxxxxxxxx31r = tokenizer.tokenize("huggingface")2print(r)3['hugging', '##face']第2步:建立词表
由于BERT预训练模型中已经有了一个给定的词表(vocab.txt),因此我们并不需要根据自己的语料来建立一个词表。当然,也不能够根据自己的语料来建立词表,因为相同的字在我们自己构建的词表中和vocab.txt中的索引顺序肯定会不一样,而这就会导致后面根据token id 取出来的向量是错误的。
进一步,我们只需要将vocab.txt中的内容读取进来形成一个词表即可,代码如下:
xxxxxxxxxx161class Vocab:2 UNK = '[UNK]'3 def __init__(self, vocab_path):4 self.stoi = {}5 self.itos = []6 with open(vocab_path, 'r', encoding='utf-8') as f:7 for i, word in enumerate(f):8 w = word.strip('\n')9 self.stoi[w] = i10 self.itos.append(w)1112 def __getitem__(self, token):13 return self.stoi.get(token, self.stoi.get(Vocab.UNK))1415 def __len__(self):16 return len(self.itos)接着便可以定义一个方法来实例化一个词表:
xxxxxxxxxx51def build_vocab(vocab_path):2 return Vocab(vocab_path)34if __name__ == '__main__':5 vocab = build_vocab()在经过上述代码处理后,我们便能够通过vocab.itos得到一个列表,返回词表中的每一个词;通过vocab.itos[2]返回得到词表中对应索引位置上的词;通过vocab.stoi得到一个字典,返回词表中每个词的索引;通过vocab.stoi['good']返回得到词表中对应词的索引;通过len(vocab)来返回词表的长度。如下便是建立后的词表:
xxxxxxxxxx11{'[PAD]': 0, '[unused0]': 1, '[unused1]': 2, '[unused2]': 3, ..., '[CLS]': 101, '[SEP]': 102,...,2106, 'such': 2107, 'being': 2108, 'used': 2109, 'state': 2110, 'people': 2111, 'part': 2112, 'know': 2113, 'against': 2114, 'your': 2115, 'many': 2116, 'second': 2117, 'university': 2118, 'both': 2119, 'national': 2120, '##er': 2121, 'these': 2122, 'don': 2123, 'known': 2124, 'off': 2125, 'way': 2126, 'until': 2127, 're': 2128, 'how': 2129, ...}此时,我们就需要定义一个类,并在类的初始化过程中根据训练语料完成字典的构建等工作,代码如下:
xxxxxxxxxx41class LoadPairSentenceClassificationDataset(LoadSingleSentenceClassificationDataset):2 def __init__(self, **kwargs):3 super(LoadPairSentenceClassificationDataset, self).__init__(**kwargs)4 pass由于我们在上一个单文本分类场景中1已近实现了数据集构建整个流程的代码,所以我们在这里只需要集成LoadSingleSentenceClassificationDataset这个类,然后再重写里面的data_process()和generate_batch()方法即可,其它地方不用修改。
第3步:转换为Token序列
在得到构建的字典后,便可以通过如下函数来将训练集、验证集和测试集转换成Token序列:
xxxxxxxxxx211 def data_process(self, filepath):2 raw_iter = open(filepath).readlines()3 data = []4 max_len = 05 for raw in tqdm(raw_iter, ncols=80):6 line = raw.rstrip("\n").split(self.split_sep)7 s1, s2, l = line[0], line[1], line[2]8 token1 = [self.vocab[token] for token in self.tokenizer(s1)]9 token2 = [self.vocab[token] for token in self.tokenizer(s2)]10 tmp = [self.CLS_IDX] + token1 + [self.SEP_IDX] + token211 if len(tmp) > self.max_position_embeddings - 1:12 tmp = tmp[:self.max_position_embeddings - 1] # BERT预训练模型只取前512个字符13 tmp += [self.SEP_IDX]14 seg1 = [0] * (len(token1) + 2)15 seg2 = [1] * (len(tmp) - len(seg1))16 segs = torch.tensor(seg1 + seg2, dtype=torch.long)17 tensor_ = torch.tensor(tmp, dtype=torch.long)18 l = torch.tensor(int(l), dtype=torch.long)19 max_len = max(max_len, tensor_.size(0))20 data.append((tensor_, segs, l))21 return data, max_len在上述代码中,第6-7行便是用来取得文本和标签;第8-9行是分别对两个序列s1和s2转换为词表中对应的Token;第10-13行则是将两个序列拼接起来,并在序列的开始加上[PAD]符号,在两个序列之间及末位加上[SEP]符号;第14-16行则是构造得到Segment Embedding的输入向量;第17-20行则是整合得到对应的样本数据,包括Token Embedding的输入、Segment Embedding的输入以及每个样本对应的标签。
在处理完成后,2.2节中的2个样本将会被转换成如下形式:
xxxxxxxxxx71tensor([[ 101, 2013, 2188, 2147, 2000, 2715, 9922, 102, 2715, 5814,2 2038, 2904, 2058, 2051, 1012, 102],3 [ 101, 2027, 2020, 13364, 6472, 1012, 102, 2027, 2020, 6472,4 3202, 2588, 5425, 1012, 102, 0]])5torch.Size([2, 16])6tensor([[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],7 [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0]])从上面的输出结果可以看出,101就是[CLS]在词表中的索引位置,102则是[SEP]在词表中的索引;其它非0值就是tokenize后的文本序列转换成的Token序列。同时可以看出,这里的结果是以第1个样本的长度16对第2个样本进行padding的,并且padding的Token ID为0。可以发现,除了对原始的文本的Token序列进行Padding外,还需要对Segment Embedding的输入进行Padding。
因此,下面我们就来介绍样本的padding处理。
第4步:padding处理与mask
从第3步的输出结果看出,在对原始文本序列tokenize转换为Token ID后还需要对其进行padding处理。对于这一处理过程可以通过如下代码来完成:
xxxxxxxxxx151def pad_sequence(sequences, batch_first=False, max_len=None, padding_value=0):2 if max_len is None:3 max_len = max([s.size(0) for s in sequences])4 out_tensors = []5 for tensor in sequences:6 if tensor.size(0) < max_len:7 tensor = torch.cat([tensor, torch.tensor([padding_value] 8 * (max_len - tensor.size(0)))], dim=0)9 else:10 tensor = tensor[:max_len]11 out_tensors.append(tensor)12 out_tensors = torch.stack(out_tensors, dim=1)13 if batch_first:14 return out_tensors.transpose(0, 1)15 return out_tensors在上述代码中,sequences为待padding的序列所构成的列表,其中的每一个元素为一个样本的Token序列;batch_first表示是否将batch_size这个维度放在第1个;max_len表示指定最大序列长度,当max_len = 50时,表示以某个固定长度对样本进行padding多余的截掉,当max_len=None时表示以当前batch中最长样本的长度对其它进行padding。第2-3行用来获取padding的长度;第5-11行则是遍历每一个Token序列,根据max_len来进行padding。
xxxxxxxxxx61if __name__ == '__main__':2 a = torch.tensor([1, 2, 3])3 b = torch.tensor([4, 5, 6, 7, 8])4 c = torch.tensor([9, 10])5 d = pad_sequence([a, b, c], max_len=None).size()6 # torch.Size([5, 3])进一步,我们需要定义一个函数来对每个batch的Token序列进行padding处理:
xxxxxxxxxx161 def generate_batch(self, data_batch):2 batch_sentence, batch_seg, batch_label = [], [], []3 for (sen, seg, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。4 batch_sentence.append(sen)5 batch_seg.append((seg))6 batch_label.append(label)7 batch_sentence = pad_sequence(batch_sentence, # [batch_size,max_len]8 padding_value=self.PAD_IDX,9 batch_first=False,10 max_len=self.max_sen_len) # [max_len,batch_size]11 batch_seg = pad_sequence(batch_seg, # [batch_size,max_len]12 padding_value=self.PAD_IDX,13 batch_first=False,14 max_len=self.max_sen_len) # [max_len, batch_size]15 batch_label = torch.tensor(batch_label, dtype=torch.long)16 return batch_sentence, batch_seg, batch_label上述代码的作用就是对每个batch的Token Embedding输入序列以及Segment Embedding输入进行padding处理。
最后,对于每一序列的attention_mask向量,我们只需要判断其是否等于padding_value便可以得到这一结果,可见第5步中的使用示例。
第5步:构造DataLoade与使用示例
经过前面4步的操作,整个数据集的构建就算是已经基本完成了,只需要再构造一个DataLoader迭代器即可,代码如下:
xxxxxxxxxx131 def load_train_val_test_data(self, train_file_path, val_file_path, test_file_path):2 train_data, max_sen_len = self.data_process(train_file_path) # 得到处理好的所有样本3 if self.max_sen_len == 'same':4 self.max_sen_len = max_sen_len5 val_data, _ = self.data_process(val_file_path)6 test_data, _ = self.data_process(test_file_path)7 train_iter = DataLoader(train_data, batch_size=self.batch_size, # 构造DataLoader8 shuffle=, collate_fn=self.generate_batch)9 val_iter = DataLoader(val_data, batch_size=self.batch_size,10 shuffle=False, collate_fn=self.generate_batch)11 test_iter = DataLoader(test_data, batch_size=self.batch_size,12 shuffle=False, collate_fn=self.generate_batch)13 return train_iter, test_iter, val_iter在上述代码中,第2-6行便是分别用来将训练集、验证集和测试集转换为Token序列;第7-12行则是分别构造3个DataLoader,其中generate_batch将作为一个参数传入来对每个batch的样本进行处理。在完成类LoadPairSentenceClassificationDataset所有的编码过程后,便可以通过如下形式进行使用:
xxxxxxxxxx301from Tasks.TaskForPairSentenceClassification import ModelConfig2from utils.data_helpers import LoadPairSentenceClassificationDataset3from transformers import BertTokenizer45if __name__ == '__main__':6 model_config = ModelConfig()7 load_dataset = LoadPairSentenceClassificationDataset(8 vocab_path=model_config.vocab_path,9 tokenizer=BertTokenizer.from_pretrained(model_config.pretrained_model_dir).tokenize,10 batch_size=model_config.batch_size,11 max_sen_len=model_config.max_sen_len,12 split_sep=model_config.split_sep,13 max_position_embeddings=model_config.max_position_embeddings,14 pad_index=model_config.pad_token_id,15 is_sample_shuffle=model_config.is_sample_shuffle)1617 train_iter, test_iter, val_iter = \18 load_dataset.load_train_val_test_data(model_config.train_file_path,19 model_config.val_file_path,20 model_config.test_file_path)21 for sample, seg, label in train_iter:22 print(sample.shape) # [seq_len,batch_size]23 print(sample.transpose(0, 1)) # [batch_size,seq_len]24 padding_mask = (sample == load_dataset.PAD_IDX).transpose(0, 1)25 print(padding_mask.shape)# [batsh_size, seq_len]26 print(label.shape)27 print(seg.shape) # [seq_len,batch_size]28 print(label) # [batch_size,]29 print(seg.transpose(0, 1))30 break执行完上述代码后便可以得到如下所示的结果:
xxxxxxxxxx111torch.Size([16, 2])2tensor([[ 101, 2013, 2188, 2147, 2000, 2715, 9922, 102, 2715, 5814,3 2038, 2904, 2058, 2051, 1012, 102],4 [ 101, 2027, 2020, 13364, 6472, 1012, 102, 2027, 2020, 6472,5 3202, 2588, 5425, 1012, 102, 0]])6torch.Size([2, 16])7torch.Size([2])8torch.Size([16, 2])9tensor([1, 2])10tensor([[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],11 [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0]])3 文本分类
3.1 工程结构
整个项目的目录结构如图3所示,其中绝大多数在掌柜在上一篇文章中已经介绍过了,在这里就不再赘述。
如同我们在本文第1节内容中介绍的,文本对(文本蕴含)分类任务本质上还是一个句子分类的问题,因此这里依旧是直接使用DownstreamTasks目录中的BertForSentenceClassification模块即可。同样,这个模块的内容在上一篇文章第4.2节中已经介绍过了,这里就不赘述。
3.2 模型训练
如图3所示,我们将在Task目录下新建一个名为TaskForPairSentenceClassification的模块来完成分类模型的微调训练任务。
首先,我们需要定义一个ModelConfig类来对分类模型中的超参数进行管理,代码如下所示:
xxxxxxxxxx331class ModelConfig:2 def __init__(self):3 self.project_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))4 self.dataset_dir = os.path.join(self.project_dir, 'data', 'PairSentenceClassification')5 self.pretrained_model_dir = os.path.join(self.project_dir, "bert_base_uncased_english")6 self.vocab_path = os.path.join(self.pretrained_model_dir, 'vocab.txt')7 self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')8 self.train_file_path = os.path.join(self.dataset_dir, 'train.txt')9 self.val_file_path = os.path.join(self.dataset_dir, 'val.txt')10 self.test_file_path = os.path.join(self.dataset_dir, 'text.txt')11 self.model_save_dir = os.path.join(self.project_dir, 'cache')12 self.logs_save_dir = os.path.join(self.project_dir, 'logs')13 self.split_sep = '_!_'14 self.is_sample_shuffle = True15 self.batch_size = 1616 self.max_sen_len = None17 self.num_labels = 318 self.epochs = 319 self.model_val_per_epoch = 220 logger_init(log_file_name='pair', log_level=logging.INFO,21 log_dir=self.logs_save_dir)22 if not os.path.exists(self.model_save_dir):23 os.makedirs(self.model_save_dir)2425 # 把原始bert中的配置参数也导入进来26 bert_config_path = os.path.join(self.pretrained_model_dir, "config.json")27 bert_config = BertConfig.from_json_file(bert_config_path)28 for key, value in bert_config.__dict__.items():29 self.__dict__[key] = value30 # 将当前配置打印到日志文件中31 logging.info("\n\n\n\n\n######## <----------------------->")32 for key, value in self.__dict__.items():33 logging.info(f"######## {key} = {value}")在上述代码中,第2-23行则是分别用来定义模型中的一些数据集目录、超参数和初始化日志打印类等;第25-29行则是将原始bert_base_uncased_english配置文件,即config.json中的参数也导入到类ModelConfig中;第31-33行则是将所有的超参数配置情况一同打印到日志文件中。
最后,我们只需要再定义一个train()函数来完成模型的训练即可,代码如下:
xxxxxxxxxx431def train(config):2 model = BertForSentenceClassification(config,3 config.pretrained_model_dir)4# ......5 optimizer = torch.optim.Adam(model.parameters(), lr=3e-5)6 model.train()7 bert_tokenize = BertTokenizer.from_pretrained(8 config.pretrained_model_dir).tokenize9 data_loader = LoadPairSentenceClassificationDataset(10 vocab_path=config.vocab_path,11 tokenizer=bert_tokenize,12 batch_size=config.batch_size,13 max_sen_len=config.max_sen_len,14 split_sep=config.split_sep,15 max_position_embeddings=config.max_position_embeddings,16 pad_index=config.pad_token_id)17 train_iter, test_iter, val_iter = \18 data_loader.load_train_val_test_data(config.train_file_path,19 config.val_file_path,20 config.test_file_path)21 max_acc = 022 for epoch in range(config.epochs):23 for idx, (sample, seg, label) in enumerate(train_iter):24 sample = sample.to(config.device) # [src_len, batch_size]25 label = label.to(config.device)26 seg = seg.to(config.device)27 padding_mask = (sample == data_loader.PAD_IDX).transpose(0, 1)28 loss, logits = model(29 input_ids=sample,30 attention_mask=padding_mask,31 token_type_ids=seg,32 position_ids=None,33 labels=label)34 # ......35 acc = (logits.argmax(1) == label).float().mean()36 if idx % 10 == 0:37 logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "38 f"Train loss :{loss.item():.3f}, Train acc: {acc:.3f}")39 train_loss = losses / len(train_iter)40 # ......41 if (epoch + 1) % config.model_val_per_epoch == 0:42 acc = evaluate(val_iter, model, config.device, data_loader.PAD_IDX)43 logging.info(f"Accuracy on val {acc:.3f}")在上述代码中,第2-3行用来根据指定预训练模型的路径初始化一个基于BERT的文本分类模型;第9-20行则是载入相应的数据集;第21-43行则是整个模型的训练过程,完整示例代码可参见[4]。
如下便是网络的训练结果:
xxxxxxxxxx121-- INFO: Epoch: 0, Batch[0/17181], Train loss :1.082, Train acc: 0.4382-- INFO: Epoch: 0, Batch[10/17181], Train loss :1.104, Train acc: 0.4383-- INFO: Epoch: 0, Batch[20/17181], Train loss :1.129, Train acc: 0.250 4-- INFO: Epoch: 0, Batch[30/17181], Train loss :1.063, Train acc: 0.3755...6-- INFO: Epoch: 0, Batch[17180/17181], Train loss :0.367, Train acc: 0.9097-- INFO: Epoch: 0, Train loss: 0.589, Epoch time = 2610.604s8...9-- INFO: Epoch: 3, Batch[0/17181], Train loss :0.064, Train acc: 1.00010-- INFO: Epoch: 3, Train loss: 0.142, Epoch time = 2542.781s11-- INFO: Accurcay on val 0.79712-- INFO: Accurcay on val 0.8105 总结
在这篇文章中,掌柜首先总体上介绍的文本蕴含(文本对分类)任务的基本思路,并且说到其本质上就是一个文本分类任务,只是需要同时将两句话输入到模型中;然后详细地介绍了如何一步一步的来构一个完整的数据集,其大致做法就是将两个句子拼接在一起中间通过[SEP]符号来进行分割,并同时通过Segment Embedding来区分两个句子;最后介绍了整个模型的实现以及训练过程。在下一篇文章中,掌柜将会介绍如何在问题选择任务(即输入一个问题和四个选项让模型选择其中最合理的一个答案)场景下进行BERT预训练模型的微调。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加掌柜微信nulls8或加群进行交流。青山不改,绿水长流,我们月来客栈见!


