掌柜费了九牛二虎之力,总算是复现了BERT论文中SQuAD的实验结果~
1 引言2 模型构建2.1 构建原理2.2 输入重构3 数据集构建3.1 语料介绍3.2 数据集预览3.3 数据集构建3.3.1 规整化原始数据3.3.2 重构输入样本3.3.3 构造DataLoader4 问题模型4.1 前向传播4.2 模型训练5 模型推理与评估5.1 模型评估5.2 模型推理5.3 结果筛选6 总结引用
1 引言
各位朋友大家好,欢迎来到月来客栈,我是掌柜空字符。
经过前面五篇文章的介绍,我们已经清楚了BERT的基本原理[1]、如何从零实现BERT[2]、如何基于BERT预训练模型来完成文本分类任务[3]、文本蕴含任务[4]以及问答选择任务[5]。为了同时满足不同人群的学习需求,在这篇文章中掌柜将会继续介绍基于BERT预训练模型的第四个下游任务场景,即如何完成问题回答任务。所谓问题回答指的就是同时给模型输入一个问题和一段描述,最后需要模型从给定的描述中预测出答案所在的位置(text span)。例如:
xxxxxxxxxx31描述:苏轼是北宋著名的文学家与政治家,眉州眉山人。2问题:苏轼是哪里人?3标签:眉州眉山人对于这样一个问题问答任务我们应该怎么来构建这个模型呢?
在做这个任务之前首先需要明白的就是:①最终问题的答案一定是在给定的描述中;②问题的答案一定是一段连续的字符。例如对于上面的描述,如果给出问题“苏轼生活在什么年代他是哪里人?”,那么模型并不会给出“北宋”和“眉州眉山人”这两个分离的答案,最好的情况下便是给出“北宋著名的文学家与政治家,眉州眉山人”这一个答案。
在有了这两个限制条件后,对于这类问答任务的本质也就变成了需要让模型预测得到答案在描述中的起始位置(start position)以及它的结束位置(end position)。所以,问题最终又变成了如何在BERT模型的基础上再构建一个分类器来对BERT最后一层输出的每个Token进行分类,判断它们是否属于start position或者是end position。
以下所有完整示例代码均可从仓库 https://github.com/moon-hotel/BertWithPretrained 中获取!
2 模型构建
2.1 构建原理
正如上面所说,对于问题回答这个任务场景来说其本质上依旧可以归结为分类任务,只是关键在于如何构建这个任务以及整个数据集。对于问题回答这个场景来说,其整体原理如图1所示。
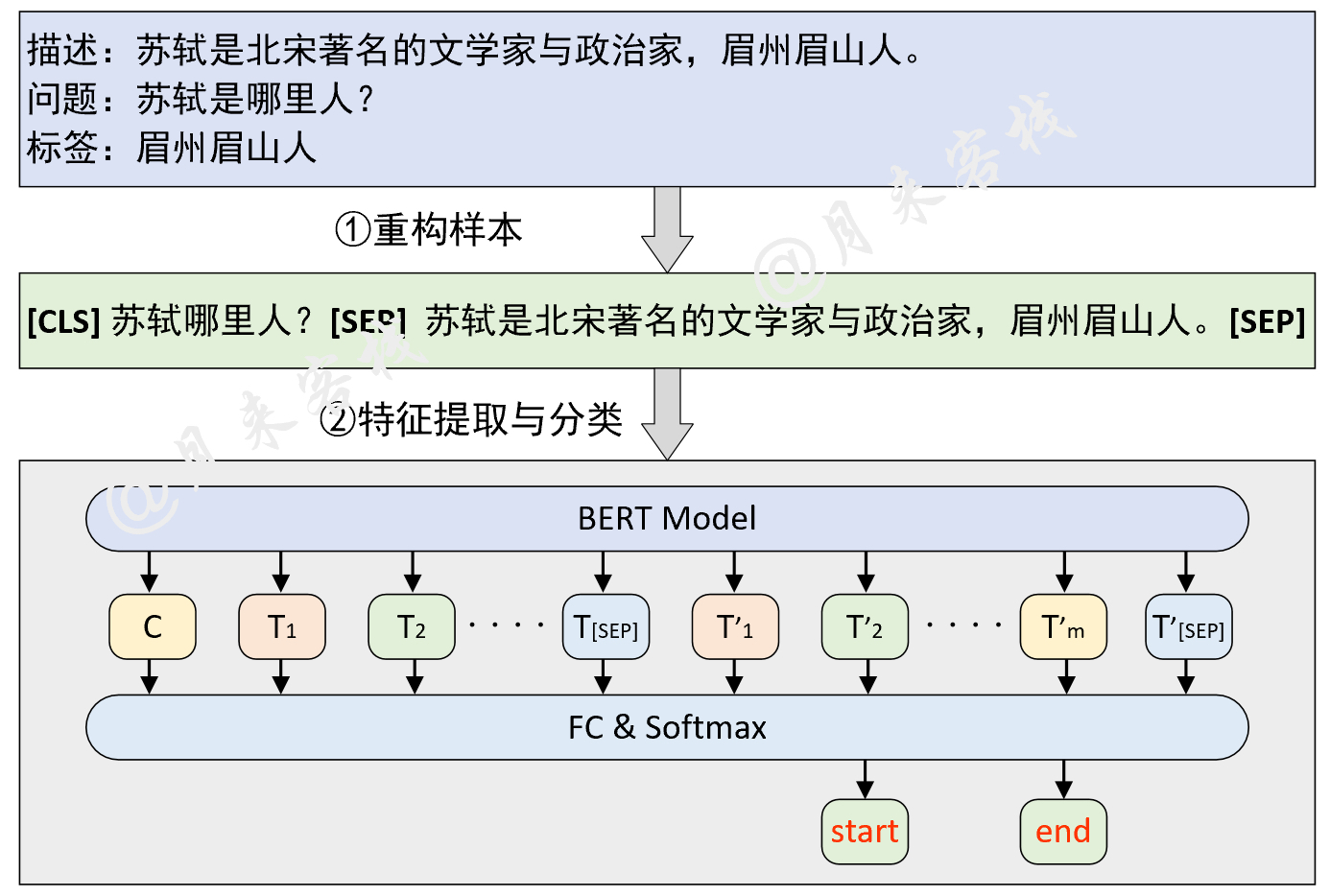
如图1所示,是一个基于BERT预训练模型的问题回答模型的原理图。从图中可以看出,构建模型输入的方式就是将原始问题和上下文描述拼接成一个序列中间用[SEP]符号隔开,然后再分别输入到BERT模型中进行特征提取。在BERT编码完成后,再取最后一层的输出对每个Token进行分类即可得到start position和end position的预测输出。
值得注意的是在问题回答场景中是将问题放在上下文描述前面的,即Sentence A为问题Sentence B为描述[6]。而在上一个问题选择任务场景中[5]是将答案放在描述之后。 这是因为在SWAG这一推理数据集中,每个选项其实都可以看作是问题(描述)的下半句,两者具有强烈的先后顺序算是一种逻辑推理,因此将选项放在了描述了后面。在问题回答这一场景中,论文中将问题放在描述前面掌柜猜测是因为:①两者并没有强烈的先后顺序;②问题相对较短放到前面可能好处理一点。所以基于这样的考虑,在问答任务中将问题放在了描述前面。不过后续大家依旧可以尝试交换一下顺序看看效果。
到此,对于问题回答模型的原理我们算是大致清楚了,下面首先来看如何构造数据集。
2.2 输入重构
在正式介绍如何构建数据集之前我们先来看这么一个问题。如果上下文过长怎么办?是直接采取截断处理吗?如果问题答案恰巧是在被截断的部分里呢,还能直接截断吗?显然,认真想一想截断这种做法在这里肯定是不行的,因此在论文中作者也采用了另外一种方法来解决这一问题,那就是滑动窗口。
在问题回答这个任务场景中(其它场景也可以参考借鉴),当原始的上下文过长超过给定长度或者是512个字符时,可以采取滑动窗口的方法来构造整个模型的输入序列,如图2所示。
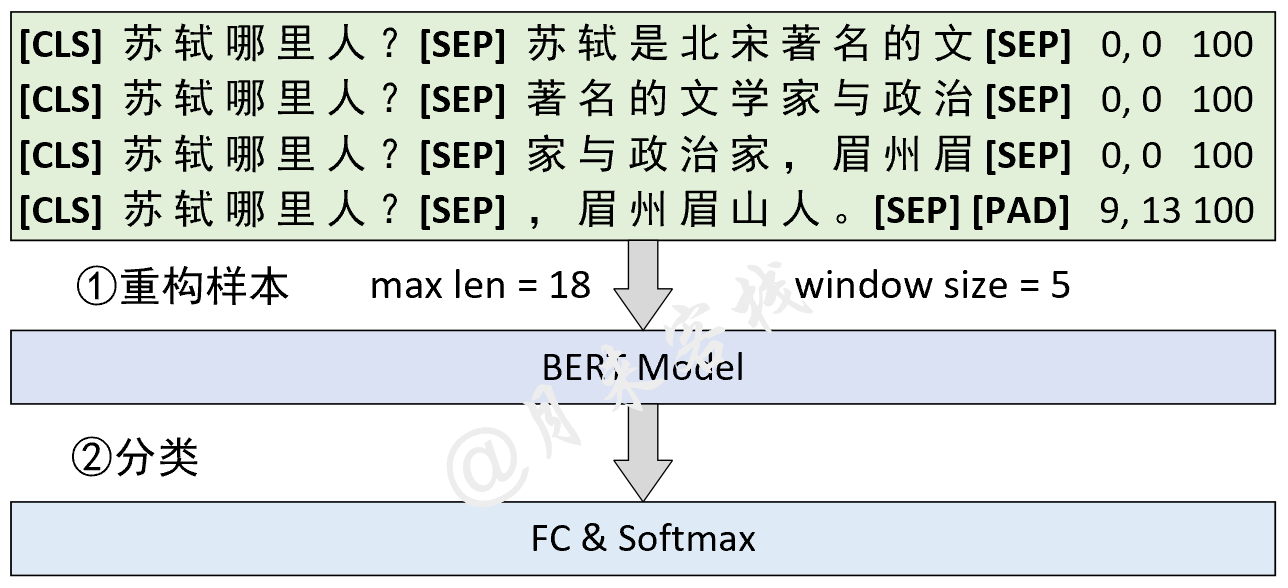
在图2所示的这一场景中,第①步需要做的是根据指定最大长度和滑动窗口大小将原始样本进行滑动窗口处理并得到多个子样本。不过这里需要注意的是,sentence A即问题部分不参与滑动处理。同时,图2中样本右边的3列数字分别表示每个子样本的起始结束索引和原始样本对应的ID。紧接着第②步便是将所有原始样本滑动处理后的结果作为训练集来训练模型。
总的来说训练这一过程并没有太大的问题,因为每个子样本也都有其对应的标签值,因此和普通的训练过程并没有什么本质上的差异。在问题回答这一任务中,最关键的地方在于如何在推理过程中也使用滑动窗口。当然,一种最直观的做法就是直接取起始位置预测概率值加结束位置预测概率值最大的子样本对应的结果,作为整个原始样本对应的预测结果。不过下面掌柜将来介绍另外一种效果更好的处理方式(这也是论文中所采取的方式),其整个处理流程如图3所示。

如图3所示,在推理过程中第①步要做的仍旧是需要根据指定最大长度和滑动窗口大小将原始样本进行滑动窗口处理。接着第②步便是根据BERT分类的输出取前K个概率值最大的结果。在图3中这里的K值为4,因此对于每个子样本来说其start position和end position分别都有4个候选结果。例如,第②步中第1行的7:0.41,10:02,9:0.12,2:01表示函数就是对于第1个子样本来说,start position为索引7的概率值为0.41,其它同理。
这样对于每一个子样本来说,在分别得到start position和end position的K个候选值后便可以通过组合来得到更多的候选预测结果,然后再根据一些规则来选择最终原始样本对应的预测输出。
根据图3中样本重构后的结果可以看出:(1)最终的索引预测结果肯定是大于8的,因为答案只可能在上下文中出现;(2)在进行结果组合的过程中,起始索引肯定是小于等于结束索引的。因此,根据这两个条件在经过步骤③的处理后,便可以得到进一步的筛选结果。例如,对于第1个子样本来说,start position中7和2是不满足条件(1)的,所以可以直接去掉;同时,为了满足第(2)个条件所以在end position中8,6,7均需要去掉。
进一步,将第③步处理后的结果在每个子样本内部进行组合,并按照start position加end position值的大小进行排序,便可以得到如图4所示的结果。

如图4所示表示根据概率和排序后的结果。例如第1列9,13,0.65的含义便是最终原始样本预测结果为9,13的概率值为0.65。因此,最终该原始样本对应的预测值便可以取9和13。
3 数据集构建
3.1 语料介绍
由于没有找到类似的高质量中文数据集,所以在这里掌柜使用到的也是论文中所提到的SQuAD(The Stanford Question Answering Dataset 1.1 )数据集[7],即给定一个问题和描述需要模型从描述中找出答案的起止位置。(找不到数据集的客官也可以找掌柜要)
从2.1节的介绍来看,在问题回答这个任务场景中模型的整体原理并不复杂,只不过需要通过滑动窗口来重构输入,所以后续我们在预处理数据集的时候还需要费点功夫。同时,SQuAD数据集本身的结构也略显复杂,所以这也相应加大了整个数据集构建的工作难度。如果不太想了解SQuAD数据集的构建流程也可以直接跳到对应预处理完成后的内容。下面掌柜就带着各位客官来一起梳理一下整个流程。
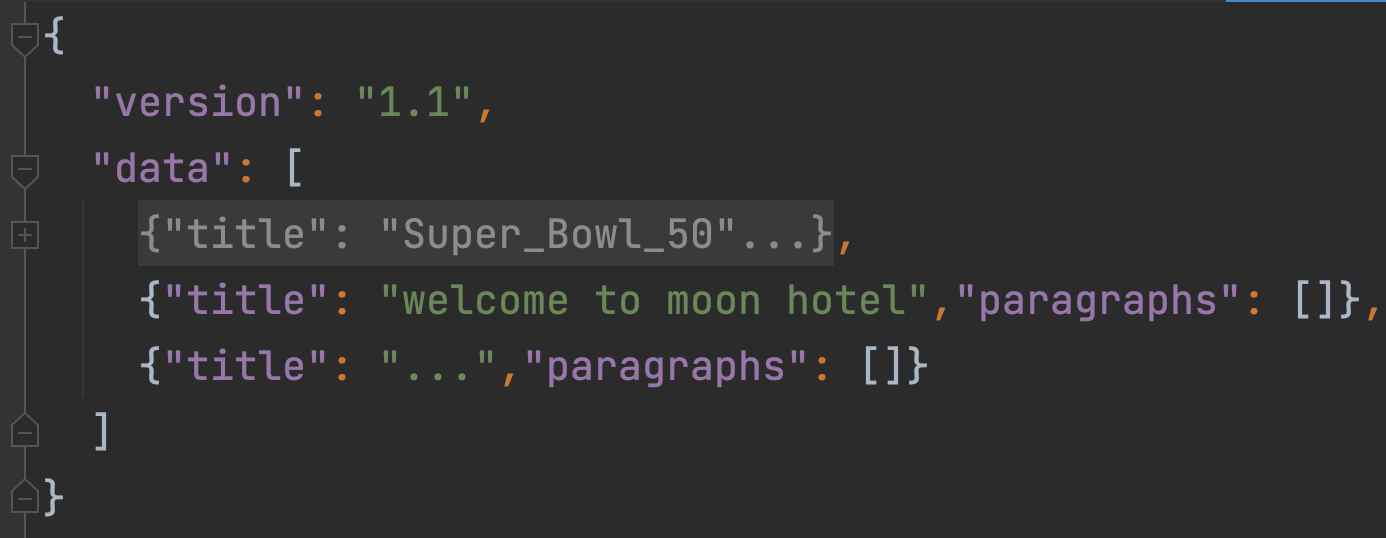
如图5所示便是数据集SQuAD1.1的结构形式。它整体由一个json格式的数据组成,其中的数据部分就在字段“data”中。可以看到data中存放的是一个列表,而列表中的每个元素可以看成是一篇文章,并以字典进行的存储。进一步,对于每一篇文章来说,其结构如下:
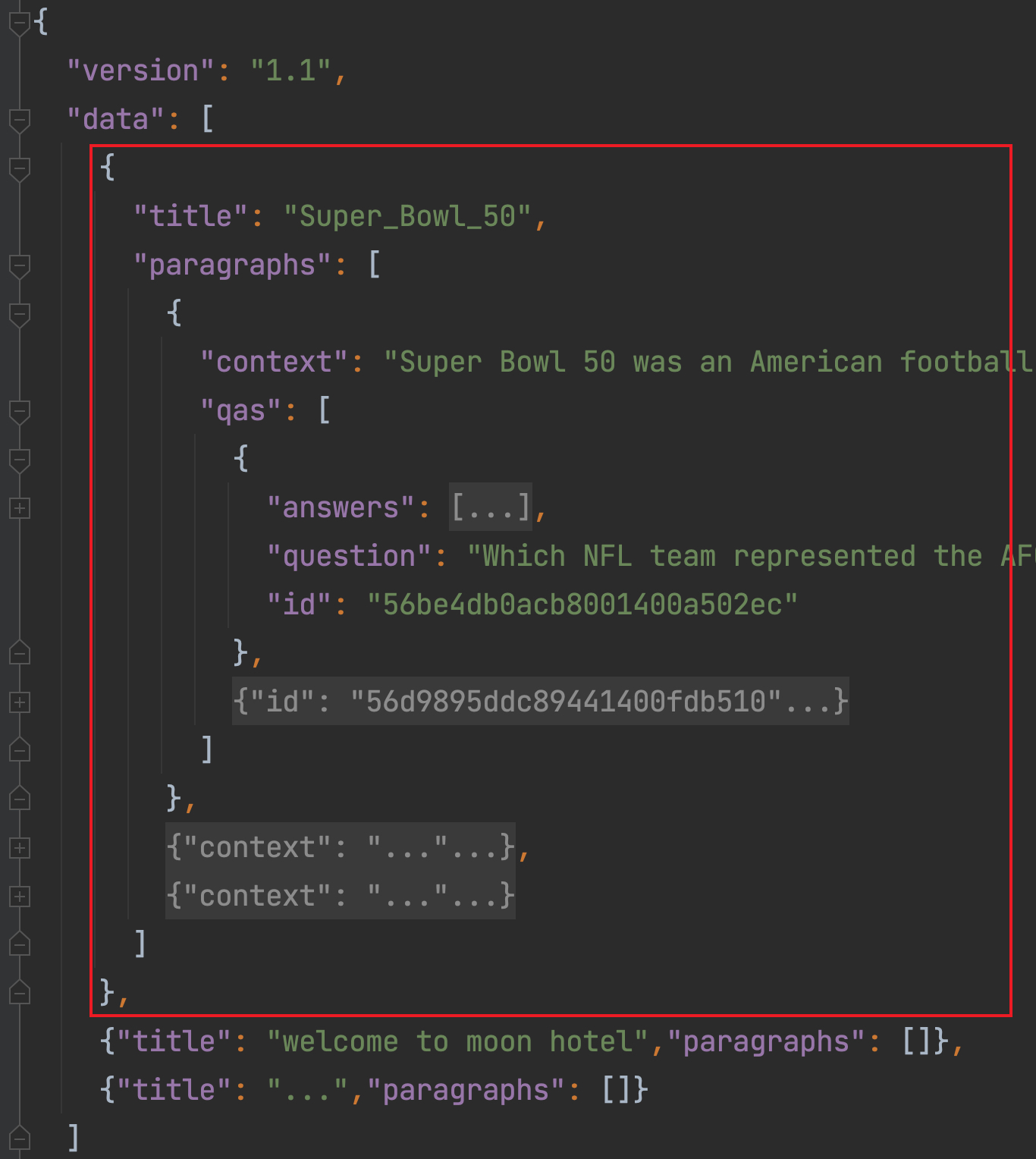
如图6所示,对于data中的每一篇文章来说,由“title”和“paragraphs”这两个字段组成。可以看到paragraphs是一个列表,其中的每一个元素为一个字典,可以看做是每一篇文章的其中一个段落,即后续需要使用到的上下文描述context。对于每一个段落来说,其包含有一段描述(“context”字段)和若干个问题与答案对(“qas”字段),其结构如下:
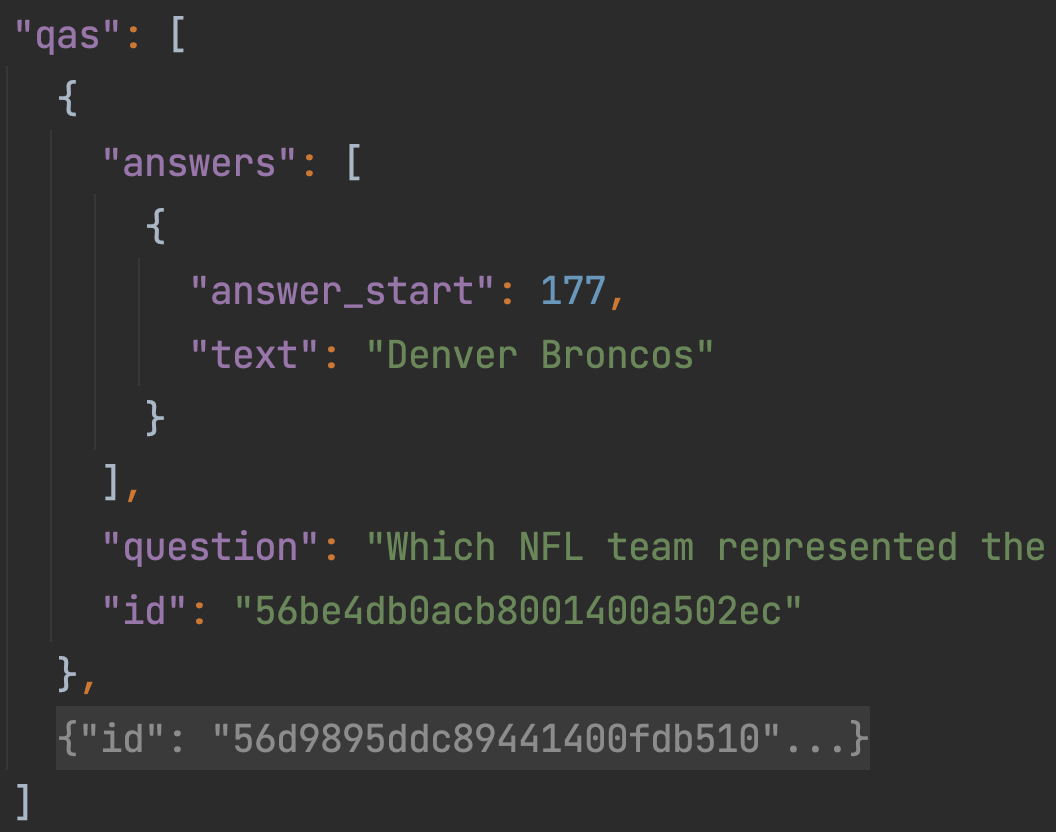
如图7所示,对于每个段落对应的问题组qas来说,其每一个元素都是答案(“answers”字段)、问题(“question”字段)和ID(“id”字段)的字典形式。同时,这里的“answer_start”只是答案在context中字符层面的索引,而不是每个单词在context中的位置,所以后面还需要进行转换。而我们所需要完成的便是从数据集中提取出对应的context、question、start pos、end pos以及id信息。
到此,对于数据集SQuAD1.1的基本信息就介绍完了。下面掌柜就开始来一步步介绍如何构建数据集。
3.2 数据集预览
在正式介绍如何构建数据集之前我们同样先通过一张图来了解一下整个大致构建的流程。假如我们现在有两个样本构成了一个batch,那么其整个数据的处理过程则如图8所示。由于英文样例普遍较长画图不太方便,所以这里就以中文进行了示例,不过两者原理都一样。
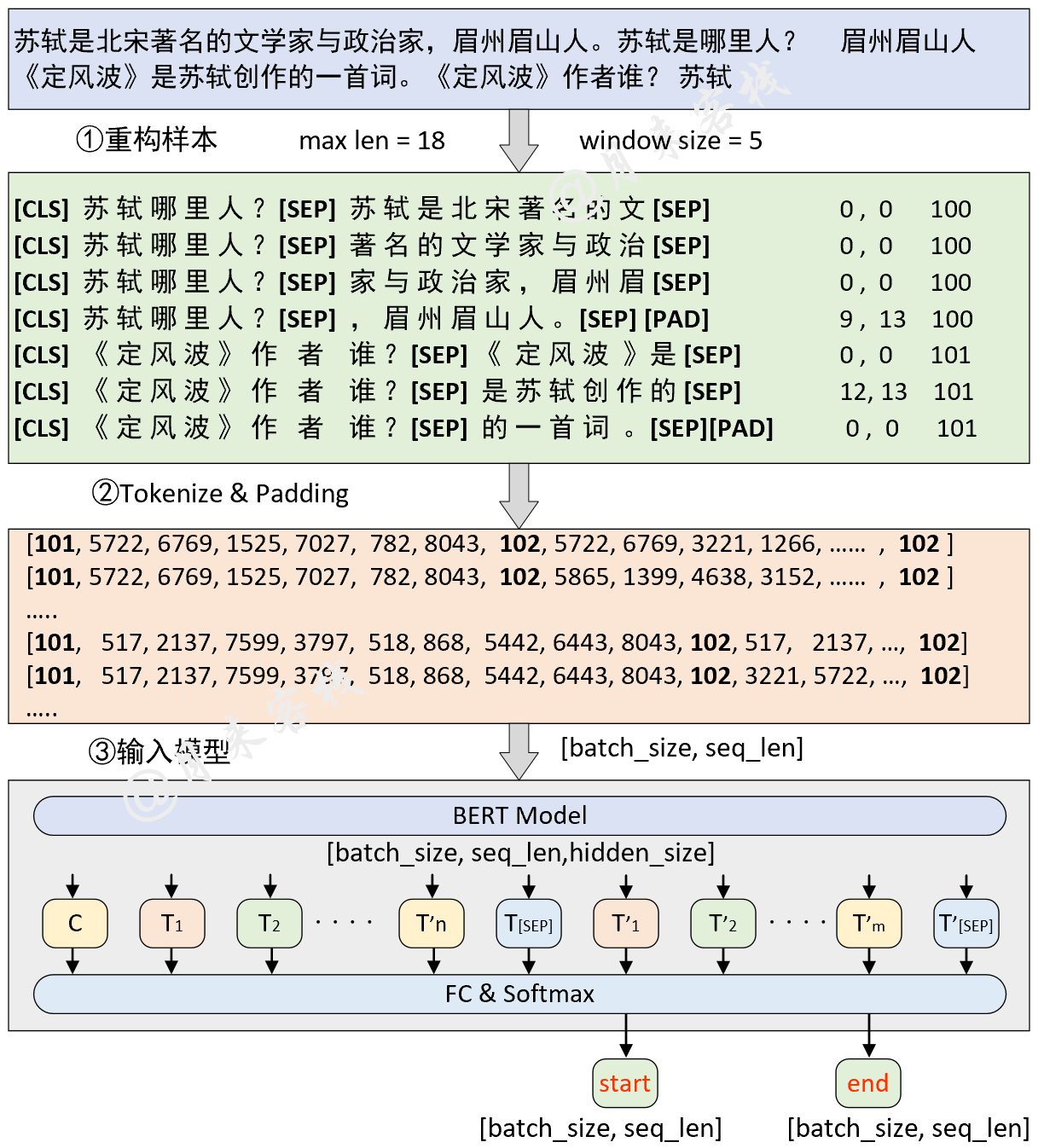
如图8所示,首先对于原始数据中的上下文按照指定的最大长度和滑动窗口大小进行滑动处理,然后再将问题同上下文拼接在一起构造成为一个序列并添加上对应的分类符[CLS]和分隔符[SEP],即图中的第①步重构样本。紧接着需要将第①步构造得到的序列转换得到Token id并进行padding处理,此时便得到了一个形状为[batch_size,seq_len]的二维矩阵,即图8中第②步处理完成后形状为[7,18]的结果。同时,在第②步中还要根据每个序列构造得到相应的attention_mask向量和token_types_ids向量(图中未画出),并且两者的形状也是[batch_size,seq_len]。
最后,将第②步处理后的结果输入到BERT模型中,在经过BERT特征提取后将会得到一个形状为[batch_size,seq_len,hidden_size]的三维矩阵,最后再乘上一个形状为[hidden_size,2]的矩阵并变形成[batch_size,seq_len,2]的形状,即是对每个Token进行分类。
3.3 数据集构建
在说完数据集构造的整理思路后,下面我们就来正式编码实现整个数据集的构造过程。同样,对于数据预处理部分我们可以继续继承之前文本分类处理的这个类LoadSingleSentenceClassificationDataset,然后再稍微修改其中的部分方法即可。同时,由于在前几个示例[3] [4] [5]中已经就tokenize和词表构建等内容做了详细的介绍,所以这部分内容就不再赘述。
3.3.1 规整化原始数据
以下数据预处理代码主要参考自https://github.com/google-research/bert中的run_squad.py脚本。
第1步:格式化文本
从图7可以看出,SQuAD原始数据集给出的每个问题的答案并不是标准的start pos和end pos,因此我们需要自己编写一个函数来根据answer_start和text字段来获得答案在原始上下文中的start pos和end pos(单词级别),如下所示
xxxxxxxxxx221 def get_format_text_and_word_offset(text):2 3 def is_whitespace(c):4 if c == " " or c == "\t" or c == "\r" or c == "\n" or ord(c) == 0x202F:5 return True6 return False7
8 doc_tokens = []9 char_to_word_offset = []10 prev_is_whitespace = True11 # 以下这个for循环的作用就是将原始context中的内容进行格式化12 for c in text: # 遍历paragraph中的每个字符13 if is_whitespace(c): # 判断当前字符是否为空格(各类空格)14 prev_is_whitespace = True15 else:16 if prev_is_whitespace: # 如果前一个字符是空格17 doc_tokens.append(c)18 else:19 doc_tokens[-1] += c # 在list的最后一个元素中继续追加字符20 prev_is_whitespace = False21 char_to_word_offset.append(len(doc_tokens) - 1)22 return doc_tokens, char_to_word_offset如上代码所示便是该函数的整体实现,其主要思路为:①第12-13行,依次遍历原始字符串中的每一个字符,然后判断其前一个字符是否为空格;②第15-17行,如果前一个字符是空格那么表示当前字符是一个新单词的开始,因此可以将前面的多个字符append到list中作为一个单词;③第18-19行,如果不是空格那么表示当前的字符仍旧属于上一个单词的一部分,因此将当前字符继续追加到上一个单词的后面;④同时,第21行用来记录当前当前字符所属单词的索引偏移量,这样根据answer_start字段来取char_to_word_offset中对应位置的值便得到了问题答案在上下文中的起始位置。
例如对于如下文本来说:
xxxxxxxxxx11text = "Architecturally, the school has a Catholic character. "函数get_format_text_and_word_offset()返回的结果便是:
xxxxxxxxxx21doc_tokens = ['Architecturally,', 'the', 'school', 'has', 'a', 'Catholic', 'character.'],2char_to_word_offset = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]例如单词school在原始text中的起始位置为21(字符级别),那么根据char_to_word_offset[21]便可以返回的到school在原始文本中的位置为2。
此时,细心的客官可能发现,返回的doc_tokens中有的单词里还包含有符号,并且很多单词在经过tokenize后还会被拆分成多个部分,因此这里只是暂时得到一个初步的起始位置,后续还会进行修正。
第2步:读取数据
根据图5到图7的展示,下面我们需要定义一个函数来对原始数据进行读取得到每个样本原始的字符串形式。
xxxxxxxxxx121class LoadSQuADQuestionAnsweringDataset(LoadSingleSentenceClassificationDataset):2 def __init__(self, **kwargs):3 super(LoadSQuADQuestionAnsweringDataset, self).__init__(**kwargs)4 self.doc_stride = doc_stride5 self.max_query_length = max_query_length6 self.n_best_size = n_best_size7 self.max_answer_length = max_answer_length8 def preprocessing(self, filepath, is_training=True):9 with open(filepath, 'r') as f:10 raw_data = json.loads(f.read())11 data = raw_data['data']12 examples = []在上述代码中,掌柜首先定义了类LoadSQuADQuestionAnsweringDataset并继承自之前的LoadSingleSentenceClassificationDataset类;第4-5行分别表示滑动窗口的长度,以及问题的最大长度;第8-12行便是定义preprocessing函数用来对原始json数据进行读取,其中第11行返回的便是整个json格式的原始数据。
下面开始遍历json数据中的每个paragraph:
xxxxxxxxxx311 def preprocessing(self, filepath, is_training=True):2 # ..... 此处接上面的代码3 for i in tqdm(range(len(data)), ncols=80): # 遍历每一个paragraphs4 paragraphs = data[i]['paragraphs'] # 取第i个paragraphs5 for j in range(len(paragraphs)): # 遍历第i个paragraphs的每个context6 context = paragraphs[j]['context'] # 取第j个context7 context_tokens, word_offset = self.get_format_text_and_word_offset(context)8 qas = paragraphs[j]['qas'] # 取第j个context下的所有 问题-答案 对9 for k in range(len(qas)): # 遍历第j个context中的多个 问题-答案 对10 question_text = qas[k]['question']11 qas_id = qas[k]['id']12 if is_training:13 answer_offset = qas[k]['answers'][0]['answer_start']14 orig_answer_text = qas[k]['answers'][0]['text']15 answer_length = len(orig_answer_text)16 start_position = word_offset[answer_offset]17 end_position = word_offset[answer_offset + answer_length - 1]18 actual_text = " ".join(19 context_tokens[start_position:(end_position + 1)])20 cleaned_answer_text = " ".join(orig_answer_text.strip().split())21 if actual_text.find(cleaned_answer_text) == -1:22 logging.warning("Could not find answer: '%s' vs. '%s'",23 actual_text, cleaned_answer_text)24 continue25 else:26 start_position = None27 end_position = None28 orig_answer_text = None29 examples.append([qas_id, question_text, orig_answer_text,30 " ".join(context_tokens), start_position, end_position])31 return examples在上述代码中,第3-4行用来遍历原始数据中的每一篇文章;第5-8行用来遍历每一篇文章中的每个paragraph,并取相应的上下文context和问题-答案对;第9-11行便是用来遍历取每个paragraph中对应的多个问题和问题id;第12-24行表示,如果当前处理的是训练集,那么再取问题对应的answer_offset、orig_answer_text并以此获取原始答案对应的起始位置start_positin和结束位置end_position;第18-23行则是判断真实答案和根据起止位置从context中截取的答案是否相同,不同则跳过该条样本;第25-28行则是用来处理验证集或测试集。
最后,该函数将会返回一个二维列表,内层列表中的各个元素分别为:
xxxxxxxxxx11['问题ID','原始问题文本','答案文本','context文本','答案在context中的开始位置','答案在context中的结束位置']例如:
xxxxxxxxxx21[['5733be284776f41900661182', 'To whom did the Virgin Mary allegedly appear in .... France?','Saint Bernadette Soubirous', 'Architecturally, the school has a Catholic character......', 90, 92],2 ['5733be284776f4190066117f', ....]]第3步:修正起止位置
在上面掌柜提到,此时得到的起止位置会因为不同的tokenize而产生变化,因此需要进一步进行修正。同时,原始文本中”(1895-1943)“这类形式的字符串也会被认为是一个单词,但是在tokenize后也会发生变化,所以需要一同进行处理。
xxxxxxxxxx151 def improve_answer_span(context_tokens,2 answer_tokens,3 start_position,4 end_position):5 new_end = None6 for i in range(start_position, len(context_tokens)):7 if context_tokens[i] != answer_tokens[0]:8 continue9 for j in range(len(answer_tokens)):10 if answer_tokens[j] != context_tokens[i + j]:11 break12 new_end = i + j13 if new_end - i + 1 == len(answer_tokens):14 return i, new_end15 return start_position, end_position在上述代码中,context_tokens为已经tokenize后的原始上下文;answer_tokens为原始答案文本经过tokenize后的结果,例如:
xxxxxxxxxx71context = "Virgin mary reputedly appeared to Saint Bernadette Soubirous in 1858"2answer_text = "Saint Bernadette Soubirous"3start_position = 54end_position = 75context_tokens: ['virgin', 'mary', 'reputed', '##ly', 'appeared', 'to', 'saint', 'bern', '##ade',6 '##tte', 'so', '##ub', '##iro', '##us', 'in', '1858']7answer_tokens: ['saint', 'bern', '##ade', '##tte', 'so', '##ub', '##iro', '##us' 则其返回后新的起止位置为[6,13]。
这段代码的主要思路是以原始起始位置开始,依次将后续的每个片段同answer_tokens进行对比,如果context_tokens中的子片段等同于answer_tokens,那么就返回新的起止位置;否则还是返回传入的起止位置。
同样,对于下面的示例:
xxxxxxxxxx61context = "The leader was John Smith (1895-1943).2answer_test = "1985"3answer_tokens: ["1895"]4start_position: 55end_position: 56context_tokens: ['the', 'leader', 'was', 'john', 'smith', '(', '1895', '-', '1943', ')', '.']返回新的起止位置便为[6,6]。
3.3.2 重构输入样本
在通过预处理函数preprocessing()后,我们便可以来进一步地采用滑动窗口方式来构造模型的输入。由于这部分代码稍微有点长,所以掌柜下面就分块进行介绍。
xxxxxxxxxx261 2 def data_process(self, filepath, is_training=False, postfix='cache'):3 logging.info(f"## 使用窗口滑动滑动,doc_stride = {self.doc_stride}")4 examples = self.preprocessing(filepath, is_training)5 all_data = []6 example_id, feature_id = 0, 10000000007 for example in tqdm(examples, ncols=80, desc="正在遍历每个问题(样本)"):8 question_tokens = self.tokenizer(example[1])9 if len(question_tokens) > self.max_query_length: # 问题过长进行截取10 question_tokens = question_tokens[:self.max_query_length]11 question_ids = [self.vocab[token] for token in question_tokens]12 question_ids = [self.CLS_IDX] + question_ids + [self.SEP_IDX]13 context_tokens = self.tokenizer(example[3])14 context_ids = [self.vocab[token] for token in context_tokens]15 16 logging.debug(f"<<<<<<<< 进入新的example >>>>>>>>>")17 start_position, end_position, answer_text = -1, -1, None18 if is_training:19 start_position, end_position = example[4], example[5]20 answer_text = example[2]21 answer_tokens = self.tokenizer(answer_text)22 start_position, end_position = self.improve_answer_span(context_tokens,23 answer_tokens,start_position,end_position)24 rest_len = self.max_sen_len - len(question_ids) - 125 context_ids_len = len(context_ids)26 logging.debug(f"## 上下文长度为:{context_ids_len}, 剩余长度 rest_len 为 : {rest_len}")在上述代码中,第1行@cache的作用是将data_process()处理后的结果进行缓存,以方便下次直接从本地载入节约时间,具体原理可以参见文章 Python修饰器与数据集缓存;第7行则是开始遍历preprocessing()函数返回的每一条原始数据;第8-14行则是取对应我们后续所需要的成分;第18-23行则是用来获取得到训练集中 start_position、end_position以及answer_text;第24-25行则是用来计算context的长度判读是否需要进行滑动窗口处理。
以下代码则是滑动窗口处理部分:
xxxxxxxxxx321 if context_ids_len > rest_len: # 长度超过max_sen_len,需要进行滑动窗口2 logging.debug(f"## 进入滑动窗口 …… ")3 s_idx, e_idx = 0, rest_len4 while True:5 tmp_context_ids = context_ids[s_idx:e_idx]6 tmp_context_tokens = [self.vocab.itos[item] for item in tmp_context_ids]7 input_ids = torch.tensor(question_ids + tmp_context_ids + [self.SEP_IDX])8 input_tokens = ['[CLS]'] + question_tokens + 9 ['[SEP]'] + tmp_context_tokens + ['[SEP]']10 seg = [0] * len(question_ids) + [1] * (len(input_ids) - len(question_ids))11 seg = torch.tensor(seg)12 if is_training: # 训练时13 new_start_position, new_end_position = 0, 014 if start_position >= s_idx and end_position <= e_idx: # in train15 logging.debug(f"## 滑动窗口中存在答案 -----> ")16 new_start_position = start_position - s_idx17 new_end_position = new_start_position + (end_position - start_position)18 new_start_position += len(question_ids)19 new_end_position += len(question_ids)20 all_data.append([example_id, feature_id, input_ids, seg, new_start_position,21 new_end_position, answer_text, example[0], input_tokens])22 else: # 预测时23 all_data.append([example_id, feature_id, input_ids, seg, start_position,24 end_position, answer_text, example[0], input_tokens])25 token_to_orig_map = self.get_token_to_orig_map(input_tokens, 26 example[3], self.tokenizer)27 all_data[-1].append(token_to_orig_map)28 feature_id += 129 if e_idx >= context_ids_len:30 break31 s_idx += self.doc_stride32 e_idx += self.doc_stride在上述代码中,第4代码开始便是进入滑动窗口循环处理中;第5-11行则是构造得到相应的所需部分;第12-24行则是分别取训练和预测时输入序列对应答案所在的索引位置,并同其余部分形成一个原始样本存入all_data当中;第25-26行则是返回得input_tokens中每个Token在原始单词中所对应的位置索引,这一结果将会在最后推理过程中得到最后预测结果时用到。例如现在有如下Token:
xxxxxxxxxx21input_tokens = ['[CLS]', 'to', 'whom', 'did', 'the', 'virgin', '[SEP]', 'architectural', '##ly',2',', 'the', 'school', 'has', 'a', 'catholic', 'character', '.', '[SEP']那么上下文Token在原始上下文中的索引映射表则为:
xxxxxxxxxx21origin_context = "Architecturally, the Architecturally, test, Architecturally, the school has a Catholic character. Welcome moon hotel"2orig_map = {7: 4, 8: 4, 9: 4, 10: 5, 11: 6, 12: 7, 13: 8, 14: 9, 15: 10, 16: 10}其含义表示,input_tokens[7]为origin_context中的第4个单词 Architecturally,同理input_tokens[10]为origin_context中的第5个单词 the。
以下代码则是非滑动窗口处理部分:
xxxxxxxxxx151 else: #context_ids_len <= rest_len: 不用滑动窗口2 input_ids = torch.tensor(question_ids + context_ids + [self.SEP_IDX])3 input_tokens = ['[CLS]'] + question_tokens + ['[SEP]'] + context_tokens + ['[SEP]']4 seg = [0] * len(question_ids) + [1] * (len(input_ids) - len(question_ids))5 seg = torch.tensor(seg)6 if is_training:7 start_position += (len(question_ids))8 end_position += (len(question_ids))9 token_to_orig_map = self.get_token_to_orig_map(input_tokens, example[3], self.tokenizer)10 all_data.append([example_id, feature_id, input_ids, seg, start_position,11 end_position, answer_text, example[0], input_tokens, token_to_orig_map])12 feature_id += 113 example_id += 114 data = {'all_data': all_data, 'max_len': self.max_sen_len, 'examples': examples}15 return data其中all_data中的每个元素分别为:原始样本id、训练特征id、input_ids、seg、开始位置、结束位置、答案文本、问题id、input_tokens和ori_map。
最终,经过上述代码处理后便可得到类似如下所示的输出结果:
xxxxxxxxxx201缓存文件 ~/BertWithPretrained/dataset/SQuAD/test2_8_120_5.pt 不存在,重新处理并缓存!2缓存文件 ~/BertWithPretrained/dataset/SQuAD/train1_8_120_5.pt 不存在,重新处理并缓存!3[2022-01-03 15:13:50] - DEBUG: <<<<<<<< 进入新的example >>>>>>>>>4[2022-01-03 15:13:50] - DEBUG: ## 正在预处理数据 utils.data_helpers is_training = True5[2022-01-03 15:13:50] - DEBUG: ## 问题 id: 5733bf84d058e614000b61bf6[2022-01-03 15:13:50] - DEBUG: ## 原始问题 text: How often is Notre Dame's the Juggler published?7[2022-01-03 15:13:50] - DEBUG: ## 原始描述 text: As at most other universities, Notre Dame's students run a number of news media outlets. The nine student-run outlets include three newspapers, ......8[2022-01-03 15:13:50] - DEBUG: ## 上下文长度为:256, 剩余长度 rest_len 为 : 1129[2022-01-03 15:13:50] - DEBUG: ## 进入滑动窗口 …… 10[2022-01-03 15:13:50] - DEBUG: ## 滑动窗口范围:(0, 112),example_id: 6, feature_id: 100000005411[2022-01-03 15:13:50] - DEBUG: ## 滑动窗口中存在答案 -----> 12[2022-01-03 15:13:50] - DEBUG: ## 原始答案:twice <===>处理后的答案:twice13[2022-01-03 15:13:50] - DEBUG: ## start pos:9114[2022-01-03 15:13:50] - DEBUG: ## end pos:9115[2022-01-03 15:13:50] - DEBUG: ## example id: 616[2022-01-03 15:13:50] - DEBUG: ## feature id: 100000005417[2022-01-03 15:13:50] - DEBUG: ## input_tokens: ['[CLS]', 'how', 'often', 'is', 'notre', 'dame', '[SEP]', 'as', 'at', 'most', 'other', 'universities', ',', ......]18[2022-01-03 15:13:50] - DEBUG: ## input_ids:[101, 2129, 2411, 2003, 10289, 8214, 102, 2004, 2012, 2087, 2060, 5534, 1010, 10289, 8214, 1005, 1055, 2493, 2448, 1037, ......]19[2022-01-03 15:13:50] - DEBUG: ## segment ids:[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, ......]20[2022-01-03 15:13:50] - DEBUG: ======================3.3.3 构造DataLoader
在完成前面两部分内容后,只需要在构造每个batch时对输入序列进行padding并返回的相应的DataLoader整个数据集就算是构造完成了。为此,首先需要定义一个函数来构造每一个batch,代码如下:
xxxxxxxxxx251 def generate_batch(self, data_batch):2 batch_input, batch_seg, batch_label, batch_qid = [], [], [], []3 batch_example_id, batch_feature_id, batch_map = [], [], []4 for item in data_batch:5 # item: [原始样本Id,训练特征id,input_ids,seg,开始,结束,答案文本,问题id,input_tokens,ori_map]6 batch_example_id.append(item[0]) # 原始样本Id7 batch_feature_id.append(item[1]) # 训练特征id8 batch_input.append(item[2]) # input_ids9 batch_seg.append(item[3]) # seg10 batch_label.append([item[4], item[5]]) # 开始, 结束11 batch_qid.append(item[7]) # 问题id12 batch_map.append(item[9]) # ori_map13
14 batch_input = pad_sequence(batch_input, # [batch_size,max_len]15 padding_value=self.PAD_IDX,16 batch_first=False,17 max_len=self.max_sen_len) # [max_len,batch_size]18 batch_seg = pad_sequence(batch_seg, # [batch_size,max_len]19 padding_value=self.PAD_IDX,20 batch_first=False,21 max_len=self.max_sen_len) # [max_len, batch_size]22 batch_label = torch.tensor(batch_label, dtype=torch.long)23 # [max_len,batch_size] , [max_len, batch_size] , [batch_size,2], [batch_size,], [batch_size,]24 return batch_input, batch_seg, batch_label, batch_qid, 25 batch_example_id, batch_feature_id, batch_map在上述代码中,第1行中的data_batch便是data_process()处理后返回的all_data;第4-12行便是构造每个batch中所包含的向量;第14-21行则是根据指定的参数max_len来进行padding处理(关于pad_sequence函数的详细介绍可以参见文章基于BERT预训练模型的文本分类任务第2.4节中的第4步);第24-25行则是用来返回每个batch处理后的结果。
进一步,构造得到数据集对应的DataLoader,代码如下:
xxxxxxxxxx291 def load_train_val_test_data(self, train_file_path=None,2 val_file_path=None,3 test_file_path=None,4 only_test=True):5 doc_stride = str(self.doc_stride)6 max_sen_len = str(self.max_sen_len)7 max_query_length = str(self.max_query_length)8 postfix = doc_stride + '_' + max_sen_len + '_' + max_query_length9 data = self.data_process(filepath=test_file_path,10 is_training=False,11 postfix=postfix)12 test_data, examples = data['all_data'], data['examples']13 test_iter = DataLoader(test_data, batch_size=self.batch_size,14 shuffle=False,15 collate_fn=self.generate_batch)16 if only_test:17 return test_iter, examples18 data = self.data_process(filepath=train_file_path,19 is_training=True,20 postfix=postfix) # 得到处理好的所有样本21 train_data, max_sen_len = data['all_data'], data['max_len']22 _, val_data = train_test_split(train_data, test_size=0.3, random_state=2021)23 if self.max_sen_len == 'same':24 self.max_sen_len = max_sen_len25 train_iter = DataLoader(train_data, batch_size=self.batch_size, # 构造DataLoader26 shuffle=self.is_sample_shuffle, collate_fn=self.generate_batch)27 val_iter = DataLoader(val_data, batch_size=self.batch_size, # 构造DataLoader28 shuffle=False, collate_fn=self.generate_batch)29 return train_iter, test_iter, val_iter在上述代码中,第5-8行则是根据对应的超参数来构造一个数据预处理结果缓存的名称;第9-17行便是用来构造得到对应测试集的DataLoader;在第22行中,笔者将原始的训练集又划分成了两个部分,并在25-28行中分别返回了两者对应的DataLoader。
同时,这里特别需要注意的一点是,为了方便后续对预测结果进行处理,掌柜直接固定了验证集和测试集中每个样本的顺序,即shuffle=False。因为当shuffle为True时,每次通过for循环遍历data_iter时样本的顺序都不一样。
到此,对于整个SQuAD1.1版数据集的构建流程就介绍了。
3.3.4 使用示例
在完成上述三个步骤之后,可以通过如下代码进行数据集的载入:
xxxxxxxxxx371if __name__ == '__main__':2 model_config = ModelConfig()3 data_loader = LoadSQuADQuestionAnsweringDataset(4 vocab_path=model_config.vocab_path,5 tokenizer=BertTokenizer.from_pretrained(model_config.pretrained_model_dir).tokenize,6 batch_size=5,7 max_sen_len=120,8 max_position_embeddings=512,9 pad_index=0,10 is_sample_shuffle=False,11 doc_stride=8,12 max_query_length=5)13 train_iter, test_iter, val_iter = data_loader. \14 load_train_val_test_data(test_file_path=model_config.test_file_path,15 train_file_path=model_config.train_file_path,16 only_test=False)17 for b_input, b_seg, b_label, b_qid, b_example_id, b_feature_id, b_map in train_iter:18 print("=====================>")19 print(f"intput_ids shape: {b_input.shape}") # [max_len, batch_size]20 print(f"token_type_ids shape: {b_seg.shape}") # [max_len, batch_size]21 print(b_seg.transpose(0, 1).tolist())22 print(b_label) # [batch_size,2]23 print(b_map) # [batch_size]24 for i in range(b_input.size(-1)):25 sample = b_input.transpose(0, 1)[i]26 start_pos, end_pos = b_label[i][0], b_label[i][1]27 strs = [data_loader.vocab.itos[s] for s in sample] # 原始tokens28 answer = " ".join(strs[start_pos:(end_pos + 1)]).replace(" ##", "")29 strs = " ".join(strs).replace(" ##", "").split('[SEP]')30 question, context = strs[0], strs[1]31 print(f"问题ID:{b_qid[i]}")32 print(f"问题:{question}")33 # print(f"描述:{context}")34 print(f"正确答案:{answer}")35 print(f"答案起止:{start_pos, end_pos}")36 print(f"example ID:{b_example_id[i]}")37 print(f"feature ID:{b_feature_id[i]}")在上述代码中,第13-16行便是返回训练集、验证集和测试集对应的DataLoader;第17-23行便是用来遍历训练集中每个batch的数据;第26-37行则是遍历一个batch中的每个样本,并转换为对应的文本形式。
最后,上述代码输入结果如下所示:
xxxxxxxxxx161=====================>2intput_ids shape: torch.Size([120, 5])3token_type_ids shape: torch.Size([120, 5])4[[0, 0, 0, 0, 0, 0, 0, 1, 1, ...], [0, 0, 0, 0, 0, 0, 0, 1, ...], ... ]5tensor([[60, 60],6 [52, 52],7 ...8 ])9[{7: 93, 8: 94, 9: 95, 10: 96, .....}, {7: 108, 8: 109, 9: 110, 10: 111,.....}, .... ]10问题ID:5733bf84d058e614000b61c111问题:[CLS] in what year did the 12正确答案:198713答案起止:(tensor(60), tensor(60))14example ID:915feature ID:100000012516......到此,对于整个数据集的介绍就完了。如果是正在搞问题回答模型的客官,掌柜强烈建议你结合本文一行一行的去阅读本项目中的原始代码,你一定会受益匪浅。
下面掌柜开始继续介绍问题回答模型的实现部分。
4 问题模型
4.1 前向传播
正如第1节内容所介绍,我们只需要在原始BERT模型的基础上取最后一层的输出结果,然后再加一个分类层即可。因此这部分代码相对来说也比较容易理解。首先需要定义一个类以及相应的初始化函数,如下:
xxxxxxxxxx111class BertForQuestionAnswering(nn.Module):2 """3 用于建模类似SQuAD这样的问答数据集4 """5 def __init__(self, config, bert_pretrained_model_dir=None):6 super(BertForQuestionAnswering, self).__init__()7 if bert_pretrained_model_dir is not None:8 self.bert = BertModel.from_pretrained(config, bert_pretrained_model_dir)9 else:10 self.bert = BertModel(config)11 self.qa_outputs = nn.Linear(config.hidden_size, 2)在上述代码中,第5-10行便是根据相应的条件返回一个BERT模型,第11行则是定义了一个分类层。
然后再是定义完成整个前向传播过程,代码如下:
xxxxxxxxxx291 def forward(self, input_ids,2 attention_mask=None,3 token_type_ids=None,4 position_ids=None,5 start_positions=None,6 end_positions=None):7 8 _, all_encoder_outputs = self.bert(9 input_ids=input_ids,10 attention_mask=attention_mask,11 token_type_ids=token_type_ids,12 position_ids=position_ids)13 sequence_output = all_encoder_outputs[-1] # 取Bert最后一层的输出14 # sequence_output: [src_len, batch_size, hidden_size]15 logits = self.qa_outputs(sequence_output) # [src_len, batch_size,2]16 start_logits, end_logits = logits.split(1, dim=-1)17 # [src_len,batch_size,1] [src_len,batch_size,1]18 start_logits = start_logits.squeeze(-1).transpose(0, 1) # [batch_size,src_len]19 end_logits = end_logits.squeeze(-1).transpose(0, 1) # [batch_size,src_len]20 if start_positions is not None and end_positions is not None:21 ignored_index = start_logits.size(1) # 取输入序列的长度22 start_positions.clamp_(0, ignored_index)23 end_positions.clamp_(0, ignored_index)24 loss_fct = nn.CrossEntropyLoss(ignore_index=ignored_index)25 start_loss = loss_fct(start_logits, start_positions)26 end_loss = loss_fct(end_logits, end_positions)27 return (start_loss + end_loss) / 2, start_logits, end_logits28 else:29 return start_logits, end_logits # [batch_size,src_len]在上述代码中,第8-13行便是根据输入返回原始BERT模型的输出结果,需要注意的是这里要取BERT输出整个最后一层的输出结果,而不是像之前一样只取最后一层第一个位置[CLS]对应的向量;第15行便是分类层的输出结果,形状为[src_len, batch_size,2];第16-19行则是得到对应的start_logits和end_logits,两者的形状均是[batch_size,src_len];第20-29行则是根据是否有标签返回对应的损失或者logits值;第21-23行是用来处理当给定的start_positions和end_positions在[0,max_len]这个范围之外时,强制将其改为max_len},例如某个样本的起始位置为520,而序列最大长度为512(即此时ignore_index=512),那么clamp_()方法便会将520改变成512,当然根据前面我们的数据处理流程来最后生成的数据集并不存在这样的情况,这里只是以防万一;在第24行中,之所以要将ignored_index作为损失计算时的忽略值,是因为这些位置并不能算是模型预测错误的(只能看做是没有预测),而是答案超出了范围所以需要忽略掉这些情况;最后,第27-29行则是根据不同的情况返回相应的结果。
到此,对于问题回答任务的模型定义就介绍完了,可以看出这一过程也并不复杂。掌柜这里依旧建议各位客官在阅读代码时能够带着对应维度进行理解,以便对每一步变换有着清晰的认识。
4.2 模型训练
首先,我们需要定义一个ModelConfig类来对分类模型中的超参数以及其它变量进行管理,代码如下所示:
xxxxxxxxxx361class ModelConfig:2 def __init__(self):3 self.project_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))4 self.dataset_dir = os.path.join(self.project_dir, 'data', 'SQuAD')5 self.pretrained_model_dir = os.path.join(self.project_dir, "bert_base_uncased_english")6 self.vocab_path = os.path.join(self.pretrained_model_dir, 'vocab.txt')7 self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')8 self.train_file_path = os.path.join(self.dataset_dir, 'train-v1.1.json')9 self.test_file_path = os.path.join(self.dataset_dir, 'dev-v1.1.json')10 self.model_save_dir = os.path.join(self.project_dir, 'cache')11 self.logs_save_dir = os.path.join(self.project_dir, 'logs')12 self.model_save_path = os.path.join(self.model_save_dir, 'model.pt')13 self.n_best_size = 10 # 对预测出的答案近后处理时,选取的候选答案数量14 self.max_answer_len = 30 # 在对候选进行筛选时,对答案最大长度的限制15 self.is_sample_shuffle = True # 是否对训练集进行打乱16 self.use_torch_multi_head = False # 是否使用PyTorch中的multihead实现17 self.batch_size = 1218 self.max_sen_len = 384 # 最大句子长度,19 self.max_query_len = 64 # 表示问题的最大长度,超过长度截取20 self.learning_rate = 3.5e-521 self.doc_stride = 128 # 滑动窗口一次滑动的长度22 self.epochs = 223 self.model_val_per_epoch = 124 logger_init(log_file_name='qa', log_level=logging.DEBUG,25 log_dir=self.logs_save_dir)26 if not os.path.exists(self.model_save_dir):27 os.makedirs(self.model_save_dir)28 # 把原始bert中的配置参数也导入进来29 bert_config_path = os.path.join(self.pretrained_model_dir, "config.json")30 bert_config = BertConfig.from_json_file(bert_config_path)31 for key, value in bert_config.__dict__.items():32 self.__dict__[key] = value33 # 将当前配置打印到日志文件中34 logging.info(" ### 将当前配置打印到日志文件中 ")35 for key, value in self.__dict__.items():36 logging.info(f"### {key} = {value}")在上述代码中需要提一点的是,第16行代码表示是否使用PyTorch中的multihead实现,如果为False则使用项目MyTransformer.py中的多头注意力实现,如果是True则会使用torch.nn.MultiheadAttention中的多头注意力实现。
紧接着,我们便可以定义函数train()来完成模型的训练:
xxxxxxxxxx521def train(config):2 model = BertForQuestionAnswering(config,3 config.pretrained_model_dir)4 model.train()5 bert_tokenize = BertTokenizer.from_pretrained(config.pretrained_model_dir).tokenize6 data_loader = LoadSQuADQuestionAnsweringDataset(7 vocab_path=config.vocab_path,8 tokenizer=bert_tokenize,9 batch_size=config.batch_size,10 max_sen_len=config.max_sen_len,11 max_query_length=config.max_query_len,12 max_position_embeddings=config.max_position_embeddings,13 pad_index=config.pad_token_id,14 is_sample_shuffle=config.is_sample_shuffle,15 doc_stride=config.doc_stride)16 train_iter, test_iter, val_iter = \17 data_loader.load_train_val_test_data(train_file_path=config.train_file_path,18 test_file_path=config.test_file_path,19 only_test=False)20 optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)21 lr_scheduler = get_scheduler(name='linear',22 optimizer=optimizer,23 num_warmup_steps=int(len(train_iter) * 0),24 num_training_steps=int(config.epochs * len(train_iter)))25 max_acc = 026 for epoch in range(config.epochs):27 losses = 028 start_time = time.time()29 for idx, (batch_input, batch_seg, batch_label, _, _, _, _) in enumerate(train_iter):30 batch_input = batch_input.to(config.device) # [src_len, batch_size]31 batch_seg = batch_seg.to(config.device)32 batch_label = batch_label.to(config.device)33 padding_mask = (batch_input == data_loader.PAD_IDX).transpose(0, 1)34 loss, start_logits, end_logits = model(input_ids=batch_input,35 attention_mask=padding_mask,36 token_type_ids=batch_seg,37 position_ids=None,38 start_positions=batch_label[:, 0],39 end_positions=batch_label[:, 1])40 ......41 acc_start = (start_logits.argmax(1) == batch_label[:, 0]).float().mean()42 acc_end = (end_logits.argmax(1) == batch_label[:, 1]).float().mean()43 acc = (acc_start + acc_end) / 244 if idx % 10 == 0:45 logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "46 f"Train loss :{loss.item():.3f}, Train acc: {acc:.3f}")47 if idx % 100 == 0:48 y_pred = [start_logits.argmax(1), end_logits.argmax(1)]49 y_true = [batch_label[:, 0], batch_label[:, 1]]50 show_result(batch_input, data_loader.vocab.itos,51 y_pred=y_pred, y_true=y_true)52 ......在上述代码中,第2-3行便是用来返回整个问答模型;第6-19行则是根据对应参数返回训练集、验证集和测试集;第20-24行则是定义了优化器和动态学习率(这个技巧在训练过程中尤其重要),关于get_scheduer的用法可以参加文章Transformers之自定义学习率动态调整;第26-51行则是正式开始进入模型的训练过程中,其中第50行中的show_result函数是用来展示训练时的预测结果。
最后,模型训练过程中将会输出类似如下信息:
xxxxxxxxxx131[2022-01-02 15:13:50] - INFO: Epoch:0, Batch[810/7387] Train loss: 0.998, Train acc: 0.7082[2022-01-02 15:13:55] - INFO: Epoch:0, Batch[820/7387] Train loss: 1.130, Train acc: 0.7083[2022-01-02 15:13:59] - INFO: Epoch:0, Batch[830/7387] Train loss: 1.960, Train acc: 0.3754[2022-01-02 15:14:04] - INFO: Epoch:0, Batch[840/7387] Train loss: 1.933, Train acc: 0.5425......6[2022-01-02 15:15:27] - INFO: ### Quesiotn: [CLS] when was the first university in switzerland founded..7[2022-01-02 15:15:27] - INFO: ## Predicted answer: 14608[2022-01-02 15:15:27] - INFO: ## True answer: 14609[2022-01-02 15:15:27] - INFO: ## True answer idx: (tensor(46, tensor(47))10[2022-01-02 15:15:27] - INFO: ### Quesiotn: [CLS] how many wards in plymouth elect two councillors?11[2022-01-02 15:15:27] - INFO: ## Predicted answer: 17 of which elect three .....12[2022-01-02 15:15:27] - INFO: ## True answer: three13[2022-01-02 15:15:27] - INFO: ## True answer idx: (tensor(25, tensor(25))到此,掌柜算是把整个模型的训练部分给介绍完了。下面,我们就正式进入具有挑战的模型推理部分的介绍。
5 模型推理与评估
掌柜这里之所有把模型的推理与评估单独作为一个小节来进行介绍,是因为这部分内容对于SQuAD这个任务来说非常重要并且内容也很多。如果这部分内容处理不好,那么最终出来的结果和谷歌论文中的结果就会产生10个点的差距。因此,掌柜在复现这部分代码时为了达到和论文中相当的表现结果,可谓也算是费了九牛二虎之力。
5.1 模型评估
首先,我们需要定义一个评估函数来对模型的表现结果进行评估。在推理时通过该函数便可以返回每个子样本对应的logits预测输出,然后再按照图3和图4的方法确定得到每个原始样本的预测结果;而在非推理阶段时,返回的则是所有子样本预测结果对应的准确率。
xxxxxxxxxx261def evaluate(data_iter, model, device, PAD_IDX, inference=False):2 model.eval()3 with torch.no_grad():4 acc_sum, n = 0.0, 05 all_results = collections.defaultdict(list)6 for batch_input, batch_seg, batch_label, batch_qid, _, batch_feature_id, _ in data_iter:7 batch_input = batch_input.to(device) # [src_len, batch_size]8 batch_seg = batch_seg.to(device)9 batch_label = batch_label.to(device)10 padding_mask = (batch_input == PAD_IDX).transpose(0, 1)11 start_logits, end_logits = model(input_ids=batch_input,12 attention_mask=padding_mask,13 token_type_ids=batch_seg,14 position_ids=None)15 all_results[batch_qid[0]].append([batch_feature_id[0],16 start_logits.cpu().numpy().reshape(-1),17 end_logits.cpu().numpy().reshape(-1)])18 if not inference:19 acc_sum_start = (start_logits.argmax(1) == batch_label[:, 0]).float().sum().item()20 acc_sum_end = (end_logits.argmax(1) == batch_label[:, 1]).float().sum().item()21 acc_sum += (acc_sum_start + acc_sum_end)22 n += len(batch_label)23 model.train()24 if inference:25 return all_results26 return acc_sum / (2 * n)在上述代码中,第5行的作用是用来定义一个默认value值为空list的字典,详细介绍可参见文章Python中的默认字典与命名体元组你会用吗?;第11-14行则是返回一个batch所有样本对应的开始和结束位置的logits;第15-17行则是将同一个问题下所有子样本的预测结果保存到一个list中,并且只有当batch_size=1时保存结果才是正确形式;第18-22行则是统计start position和end position预测正确的数量;第24-26行则是根据不同的条件返回logits和准确率。有了这个评估函数,我们可以在训练时返回模型在验证集上的准确率,在推理时返回模型在测试集上的logits。
5.2 模型推理
在完成评估函数定义后,我们只需要再定义一个用于推理的函数便可以在模型训练结束后对测试集进行推理预测并返回相应的logits结果。
xxxxxxxxxx291def inference(config):2 bert_tokenize = BertTokenizer.from_pretrained(config.pretrained_model_dir).tokenize3 data_loader = LoadSQuADQuestionAnsweringDataset(4 vocab_path=config.vocab_path,5 tokenizer=bert_tokenize,6 batch_size=1, # 只能是17 max_sen_len=config.max_sen_len,8 doc_stride=config.doc_stride,9 max_query_length=config.max_query_len,10 max_answer_length=config.max_answer_len,11 max_position_embeddings=config.max_position_embeddings,12 pad_index=config.pad_token_id,13 n_best_size=config.n_best_size)14 test_iter, all_examples = data_loader.load_train_val_test_data(15 test_file_path=config.test_file_path,only_test=True)16 model = BertForQuestionAnswering(config,17 config.pretrained_model_dir)18 if os.path.exists(config.model_save_path):19 loaded_paras = torch.load(config.model_save_path)20 model.load_state_dict(loaded_paras)21 logging.info("## 成功载入已有模型,开始进行推理......")22 else:23 raise ValueError(f"## 模型{config.model_save_path}不存在,请检查路径或者先训练模型......")24
25 model = model.to(config.device)26 all_result_logits = evaluate(test_iter, model, config.device,27 data_loader.PAD_IDX, inference=True)28 data_loader.write_prediction(test_iter, all_examples,29 all_result_logits, config.dataset_dir)在上述代码中,第2-15行是根据相应的超参数来返回对应测试集,其中需要注意的一点便是第6行中的batch_size只能是1,因为从evaluate函数中的第15行代码可以看出,我们在保存开始和结束位置的logits时是一条记录一条记录进行保存的(当然你也可以进行修改);第16-23行则是先用谷歌开源的预训练参数初始化模型,然后再用训练好保存在本地的参数来重新初始化模型;第26-27行是得到根据评估函数evaluate()返回每个原始样本下所有子样本的预测logits结果;第28-29行则是根据返回的logits根据图3和图4中的原理来筛选得到最终的预测结果。
5.3 结果筛选
对于整个推理过程来说,最重要的就是最后这一步结果筛选。由于这部分代码稍微有点长,所以掌柜同样也分块进行介绍。首先,我们需要在类LoadSQuADQuestionAnsweringDataset中再添加一个write_prediction()方法用于将筛选后的预测结果写入到本地文件中。
xxxxxxxxxx101 def write_prediction(self, test_iter, all_examples, logits_data, output_dir):2 qid_to_example_context = {} # 根据qid取到其对应的context token3 for example in all_examples:4 context = example[3]5 context_list = context.split()6 qid_to_example_context[example[0]] = context_list7 _PrelimPrediction = collections.namedtuple( # pylint: disable=invalid-name8 "PrelimPrediction",9 ["text", "start_index", "end_index", "start_logit", "end_logit"])10 prelim_predictions = collections.defaultdict(list)在上述代码中,第2-6行用于获取得到每个qid对应的上下文Token,这样后面根据qid便能获取得到每个问题对应上下文的Token,类似于
xxxxxxxxxx11{'5733be284776f41900661181':['Architecturally,', 'the', 'school', 'has', 'a', 'Catholic', 'character.', 'Atop', 'the', 'Main', "Building's", 'gold'],...}第7-10行则是分别定义一个命名体元组(详细介绍可以参见文章Python中的默认字典与命名体元组你会用吗?)和默认value为列表的字典便于后续使用。
进一步,我们遍历测试集中的每个输入特征(子样本),并取其对应的logits预测结果进行筛选:
xxxxxxxxxx71 for b_input, _, _, b_qid, _, b_fea_id, b_map in tqdm(test_iter, ncols=80, desc="正在遍历候选答案"):2 all_logits = logits_data[b_qid[0]]3 for logits in all_logits:4 if logits[0] != b_fea_id[0]:5 continue # 非当前子样本对应的logits忽略6 start_indexes = self.get_best_indexes(logits[1], self.n_best_size)7 end_indexes = self.get_best_indexes(logits[2], self.n_best_size)在上述代码中,第1行用来得到该问题ID对应的所有logits结果,因为有了滑动窗口所以原始一个context可以构造得到多个训练子样本;第4-5行则是用来只取当前子样本对应的logits预测结果;第7-8两行则是用来返回前n_best_size个概率值最大候选索引,也就是图3中的第②步。例如start_index的候选值可能是[23,45,33,24],end_indexes的候选值可能是[19,35,28,56]。
在得到多个候选的开始结束索引后,便需要对其按条件进行过滤和筛选,代码如下:
xxxxxxxxxx151 for start_index in start_indexes:2 for end_index in end_indexes: # 遍历所有存在的结果组合3 if start_index >= b_input.size(0):4 continue # 起始索引大于token长度,忽略5 if end_index >= b_input.size(0):6 continue # 结束索引大于token长度,忽略7 if start_index not in b_map[0]:8 continue # 用来判断索引是否位于[SEP]之后的位置,因为答案只会在[SEP]以后出现9 if end_index not in b_map[0]:10 continue11 if end_index < start_index:12 continue13 length = end_index - start_index + 114 if length > self.max_answer_length:15 continue在上述代码中,第1-2行两个for循环用来依次遍历每个[start_index,end_index]组合;第3-6行则是过滤掉开始和结束位置大于输入序列长度的情况;第7-10行则是用来过滤开始和结束位置不在当前子样本对应的映射表b_map中的情况,因为b_map中key是b_input里上下文Token在b_input中的索引。例如对于如下结果来说:
xxxxxxxxxx21input_tokens = ['[CLS]', 'what', 'is', 'in', 'front', 'of', 'the', 'notre', 'dame', 'main', 'building', '[SEP]', 'character', '.', 'atop', 'the', ... ]2orig_map = {12: 6, 13: 6, 14: 7, 15: 8, 16: 9, ....}orig_map里12:6中的12表示单词character在input_tokens中的索引是12,14: 7中的14表示单词atop在input_tokens中的索引是14,因此对于所有预测得到的开始和结束位置都应该在orig_map的key当中。
第11-12行则是用来过滤掉结束位置大于开始位置的情况;第13-15行则是用来过滤答案长度大于设定最大长度的情况。
在完成这一步之后,我们便可以根据筛选得到的候选结果取到对应的预测答案文本,代码如下:
xxxxxxxxxx181 token_ids = b_input.transpose(0, 1)[0]2 strs = [self.vocab.itos[s] for s in token_ids]3 tok_text = " ".join(strs[start_index:(end_index + 1)])4 tok_text = tok_text.replace(" ##", "").replace("##", "")5 tok_text = tok_text.strip()6 tok_text = " ".join(tok_text.split())7
8 orig_doc_start = b_map[0][start_index]9 orig_doc_end = b_map[0][end_index]10 orig_tokens = qid_to_example_context[b_qid[0]][orig_doc_start:(orig_doc_end + 1)]11 orig_text = " ".join(orig_tokens)12 final_text = self.get_final_text(tok_text, orig_text)13 prelim_predictions[b_qid[0]].append(_PrelimPrediction(14 text=final_text,15 start_index=int(start_index),16 end_index=int(end_index),17 start_logit=float(logits[1][start_index]),18 end_logit=float(logits[2][end_index])))在上述代码中,第1-6行用于根据预测得到的开始结束位置直接从input_token中获取最后的答案;第8-11行则是先根据预测得到的开始结束位置在b_map中取到对应在原始上下文中的开始结束位置,然后从原始的上下文中获取最后的答案;第12行则是根据get_final_text函数来对比两种方式获取的答案来返回最终的答案;第13-18行则是将对应的结果以命名体元组的形式保存到字典中。
最后,只需要将保存到prelim_predictions中结果进行排序然后写入到本地即可,代码如下:
xxxxxxxxxx121 for k, v in prelim_predictions.items():2 prelim_predictions[k] = sorted(prelim_predictions[k],3 key=lambda x: (x.start_logit + x.end_logit),4 reverse=True)5 best_results, all_n_best_results = {}, {}6 for k, v in prelim_predictions.items():7 best_results[k] = v[0].text # 取最好的第一个结果8 all_n_best_results[k] = v # 保存所有预测结果9 with open(os.path.join(output_dir, f"best_result.json"), 'w') as f:10 f.write(json.dumps(best_results, indent=4) + '\n')11 with open(os.path.join(output_dir, f"best_n_result.json"), 'w') as f:12 f.write(json.dumps(all_n_best_results, indent=4) + '\n')在上述代码中,第1-4行代码是对每个qid对应的所有预测答案按照start_logit+end_logit的大小进行排序;第6-8行则是取最好的预测结果与最好的前n个预测结果(可用于分析);第9-12行则是将这两个结果写入到本地。
在得到预测结果后,只需要运行如下代码即可得到最终的评价结果:
xxxxxxxxxx31python evaluate-v1.1.py dev-v1.1.json best_result.json2
3"exact_match": {80.879848628193, "f1": 88.338575234135}到此,对于整个SQuAD任务的细节之处就介绍完了,不过掌柜依旧强烈建议各位客官在阅读完文章的同时再去看看整个项目的源码实现,会理解得更透彻。
6 总结
在这篇文章中,掌柜首先介绍了基于BERT模型来完成SQuAD任务的基本原理,包括模型和输入的构建以及如何解决文本过长的问题;接着介绍了SQuAD数据集的基本信息以及如何一步一步地来构建标准的DataLoader供模型训练所使用;然后介绍了如何实现整个问题回答模型以及训练过程;最后详细介绍了怎样一步一步地根据每个子样本的预测结果来筛选得到最终父样本的预测结果。
总的来说,基于BERT模型的SQuAD问答任务从原理上来讲并不难,难就难在如何处理样本过程的问题,以及如何一步步地筛选得到最后的结果。好在掌柜已经替各位客官踩完了所有的坑,你们只需要跟着掌柜的足迹一步一步向前走即可。在下一篇文章中,掌柜将会详细介绍如何来从头训练一个BERT模型,包括中英文两种语料的应用场景。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎点赞分享!若有任何疑问与建议,请添加掌柜微信nulls8(备注来源)或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[6]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
[7]https://rajpurkar.github.io/SQuAD-explorer/
[10]示例代码:https://github.com/moon-hotel/BertWithPretrained


