1 引言
各位朋友大家好,欢迎来到月来客栈。我们知道Transformer的核心部分就是MultiHeadAttention,也就是所谓的多头注意力机制。在通过前面几篇文章详细介绍完Transformer网络结构的原理后,接下来就让我们来看一看如何借用Pytorch框架来实现MultiHeadAttention这一结构。
同时,需要说明的一点是,下面所有的实现代码都是笔者直接从Pytorch 1.4版本中(torch.nn.Transformer模块)摘取出来的简略版,目的就是为了让大家对于整个实现过程有一个清晰的认识。并且为了使得大家在阅读完以下内容后也能够对Pytorch中的相关模块有一定的了解,所以下面的代码在变量名方面也与Pytorch保持了一致。
在正式介绍MultiHeadAttention的实现之前,我们先来对Transformer网络结构部分的内容进行一个收尾,即多层Transformer网络模型。
2 多层Transformer
在上一篇文章中,笔者详细介绍了单层Transformer网络结构中的各个组成部分。尽管多层Transformer就是在此基础上堆叠而来,不过笔者认为还是有必要在这里稍微提及一下。
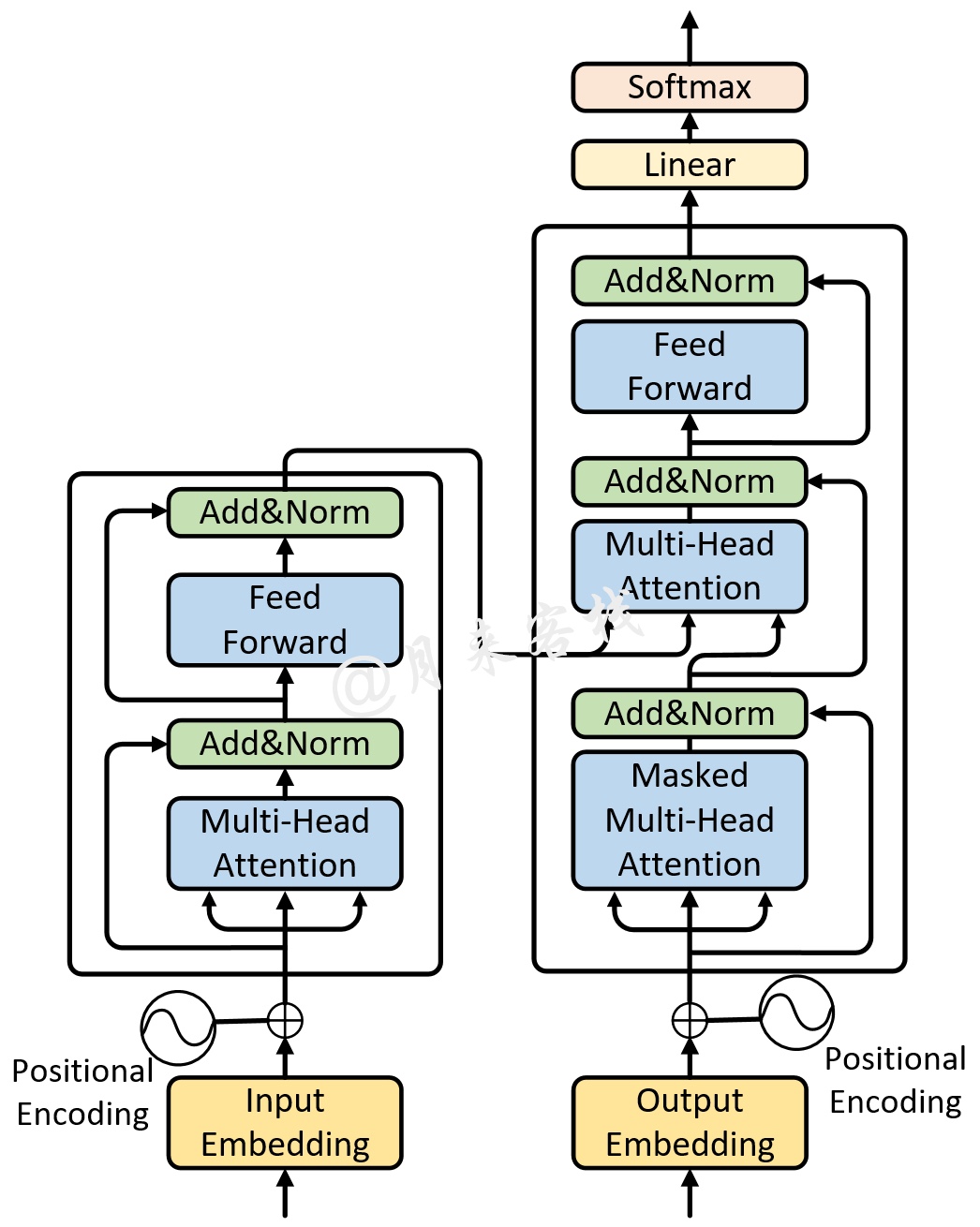
如图1所示便是一个单层Transformer网络结构图,左边是编码器右边是解码器。而多层的Transformer网络就是在两边分别堆叠了多个编码器和解码器的网络模型,如图2所示。
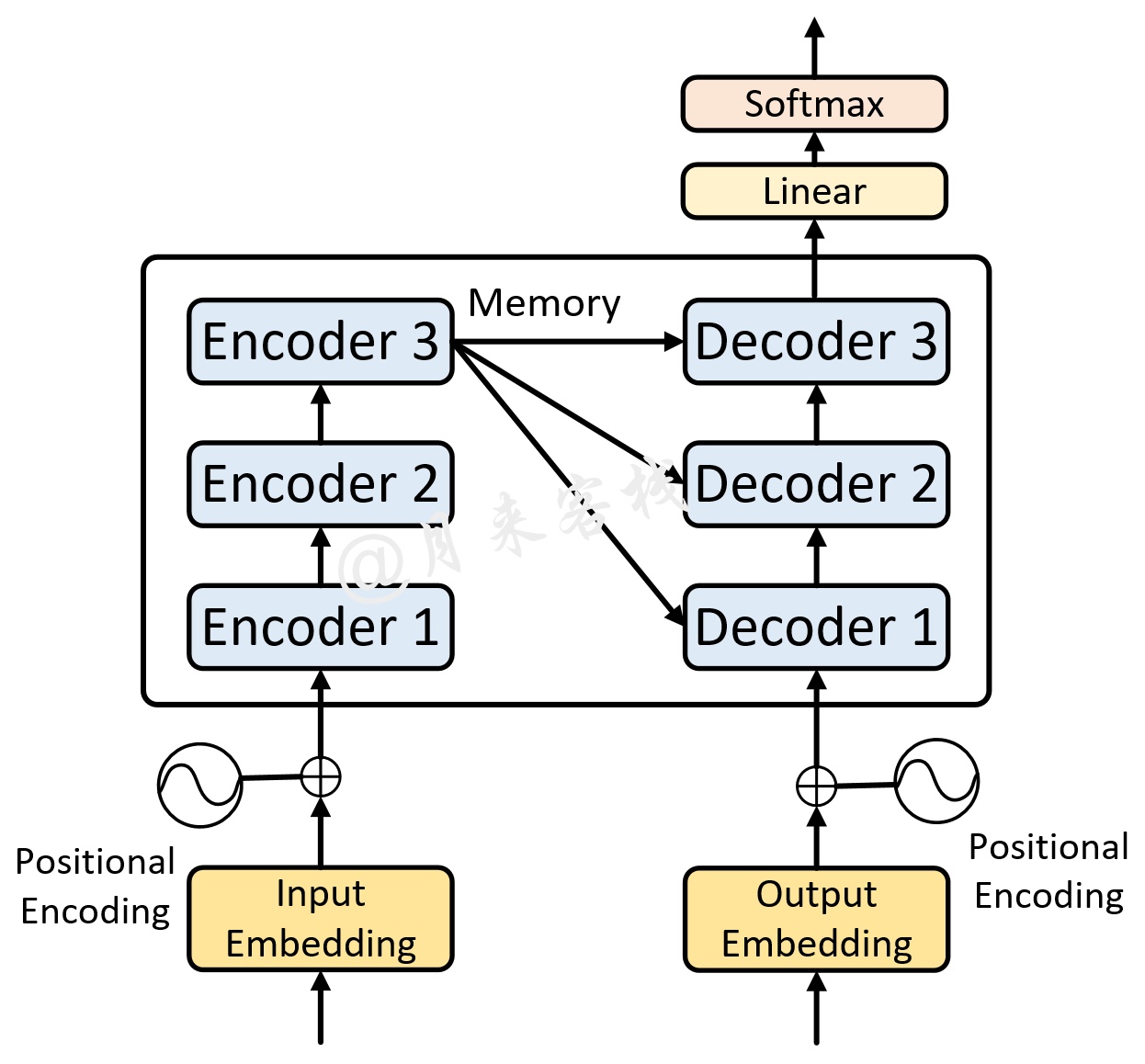
如图2所示便是一个多层的Transformer网络结构图(原论文中采用了6个编码器和6个解码器),其中的每一个Encoder都是图1中左边所示的网络结构(Decoder同理)。可以发现,它真的就是图1堆叠后的形式。不过需要注意的是其整个解码过程。
在多层Transformer中,多层编码器先对输入序列进行编码,然后得到最后一个Encoder的输出Memory;解码器先通过Masked Multi-Head Attention对输入序列进行编码,然后将输出结果同Memory通过Encoder-Decoder Attention后得到第1层解码器的输出;接着再将第1层Decoder的输出通过Masked Multi-Head Attention进行编码,接着将编码后的结果同Memory通过Encoder-Decoder Attention后得到第2层解码器的输出,以此类推得到最后一个Decoder的输出。
值得注意的是,在多层Transformer的解码过程中,每一个Decoder在Encoder-Decoder Attention中所使用的Memory均是同一个。
3 Transformer中的掩码
由于在实现多头注意力时需要考虑到各种情况下的掩码,因此在这里需要先对这部分内容进行介绍。在Transformer中,主要有两个地方会用到掩码这一机制。第1个地方就是在上一篇文章用介绍到的Attention Mask,用于在训练过程中解码的时候掩盖掉当前时刻之后的信息;第2个地方便是对一个batch中不同长度的序列在Padding到相同长度后,对Padding部分的信息进行掩盖。下面分别就这两种情况进行介绍。
3.1 Attention Mask
如图3所示,在训练过程中对于每一个样本来说都需要这样一个对称矩阵来掩盖掉当前时刻之后所有位置的信息。
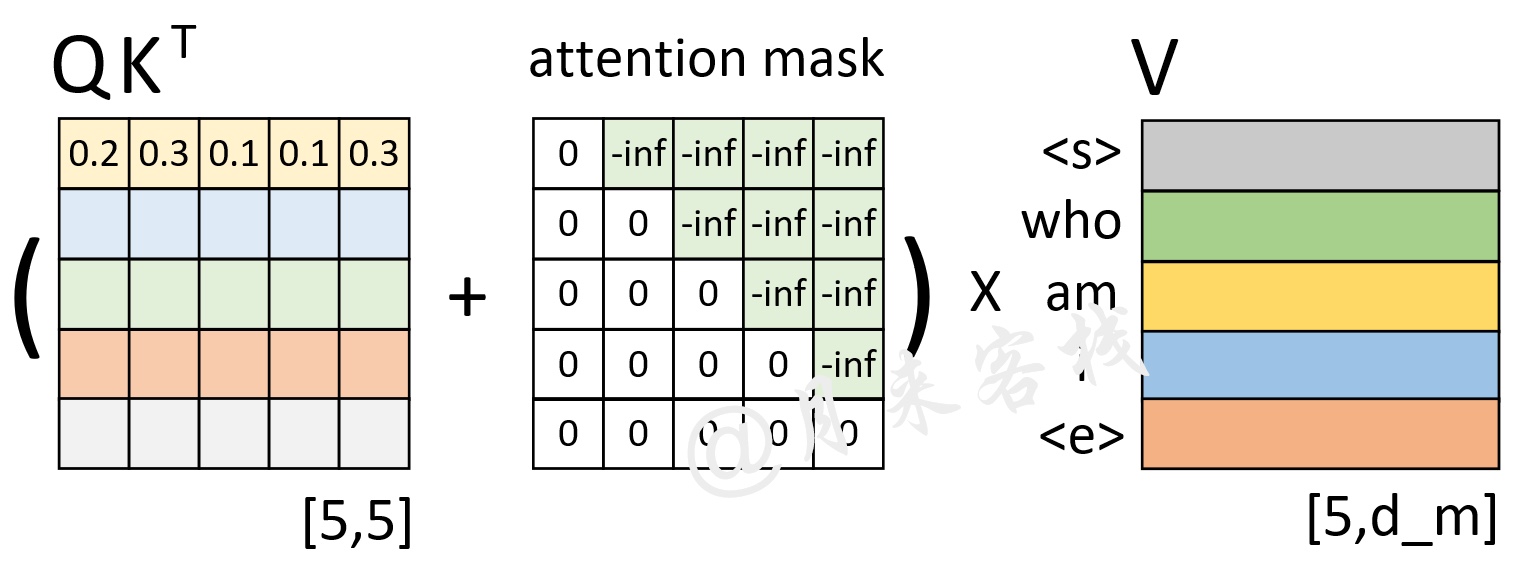
从图3可以看出,这个注意力掩码矩阵的形状为[tgt_len,tgt_len]。在后续实现过程中,我们将通过generate_square_subsequent_mask方法来生成这样一个矩阵。同时,在后续多头注意力机制实现中,将通过attn_mask这一变量名来指代这个矩阵。
3.2 Padding Mask
在Transformer中,使用到掩码的第2个地方便是Padding Mask。由于在网络的训练过程中同一个batch会包含有多个文本序列,而不同的序列长度并不一致。因此在数据集的生成过程中,就需要将同一个batch中的序列Padding到相同的长度。但是,这样就会导致在注意力的计算过程中会考虑到Padding位置上的信息。
如图4所示,P表示Padding的位置,右边的矩阵表示计算得到的注意力权重矩阵。可以看到,此时的注意力权重对于Padding位置山的信息也会加以考虑。因此在Transformer中,作者通过在生成训练集的过程中记录下每个样本Padding的实际位置;然后再将注意力权重矩阵中对应位置的权重替换成负无穷便达到了忽略Padding位置信息的目的。这种做法也是Encoder-Decoder网络结构中通用的一种办法。
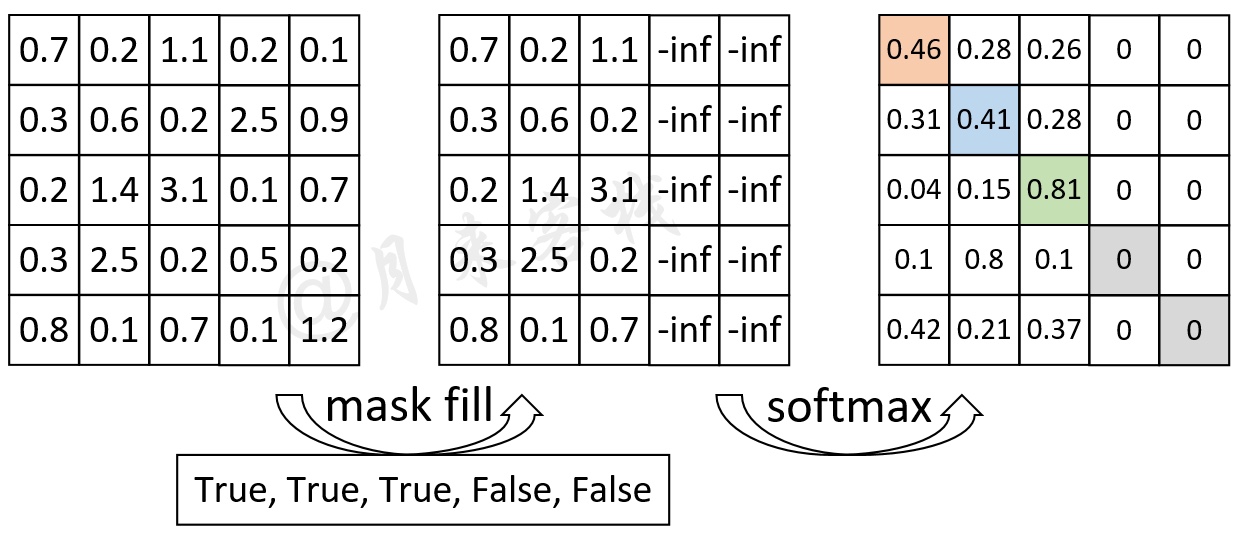
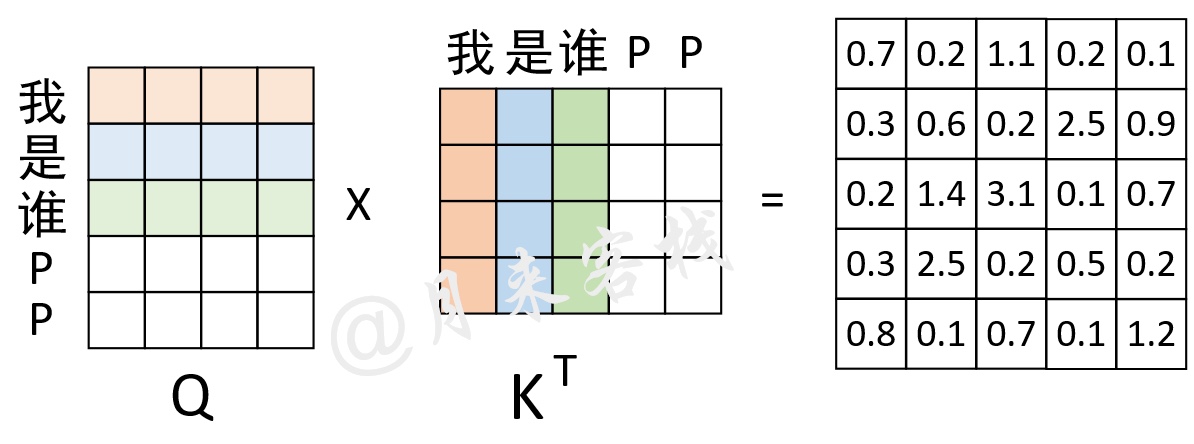
如图5所示,对于”我 是 谁 P P“这个序列来说,前3个字符是正常的,后2个字符是Padding后的结果。因此,其Mask向量便为[True, True, True, False, False]。通过这个Mask向量可知,需要将权重矩阵的最后两列替换成负无穷,在后续我们会通过torch.masked_fill这个方法来完成这一步,并且在实现时将使用key_padding_mask来指代这一向量。
到此,对于Transformer中所要用到Mask的地方就介绍完了,下面正式来看如何实现多头注意力机制。
4 实现多头注意力机制
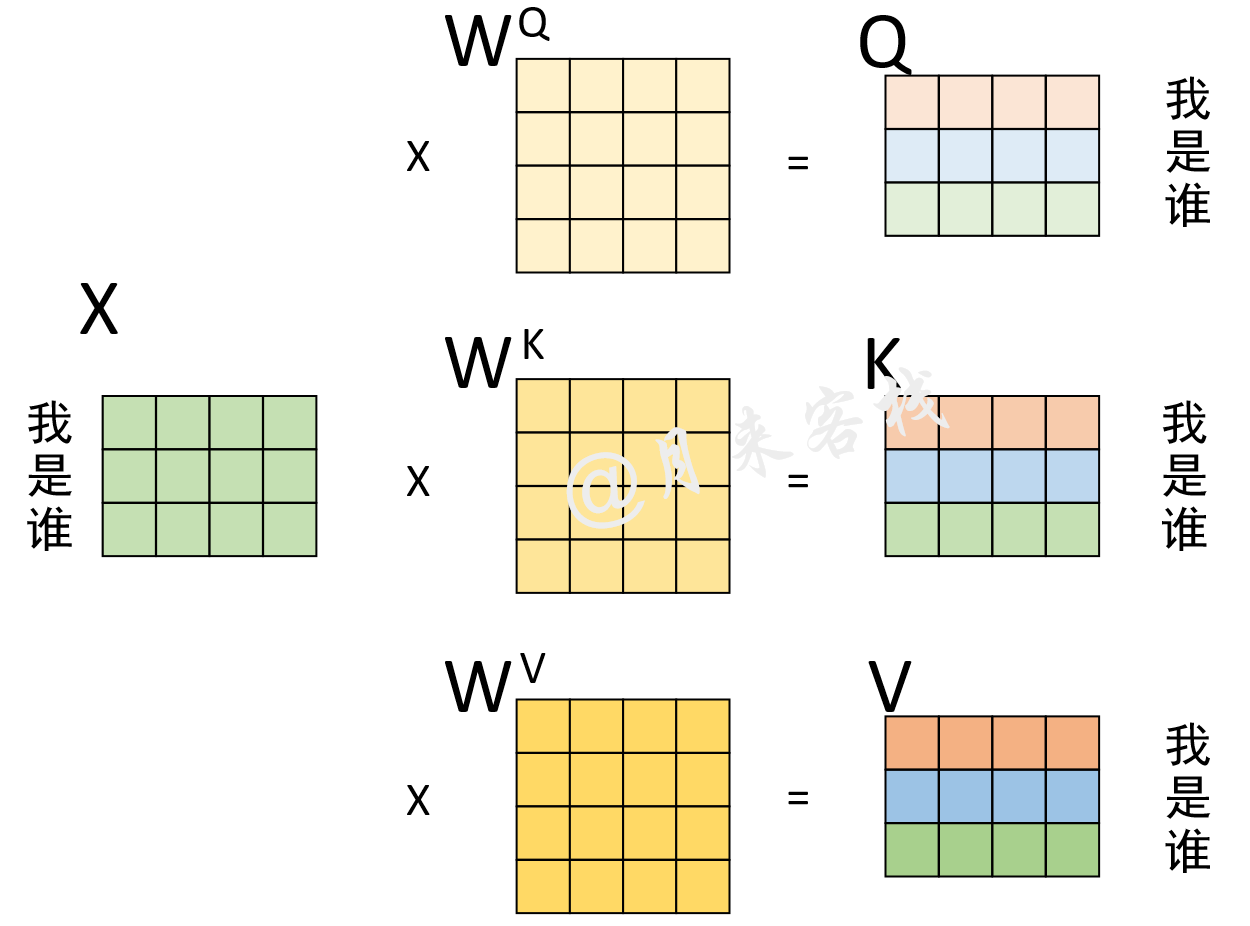
根据前面的介绍可以知道,多头注意力机制中最为重要的就是自注意力机制,也就是需要前计算得到Q、K和V,如图6所示。
然后再根据Q、K、V来计算得到最终的注意力编码,如图7所示:
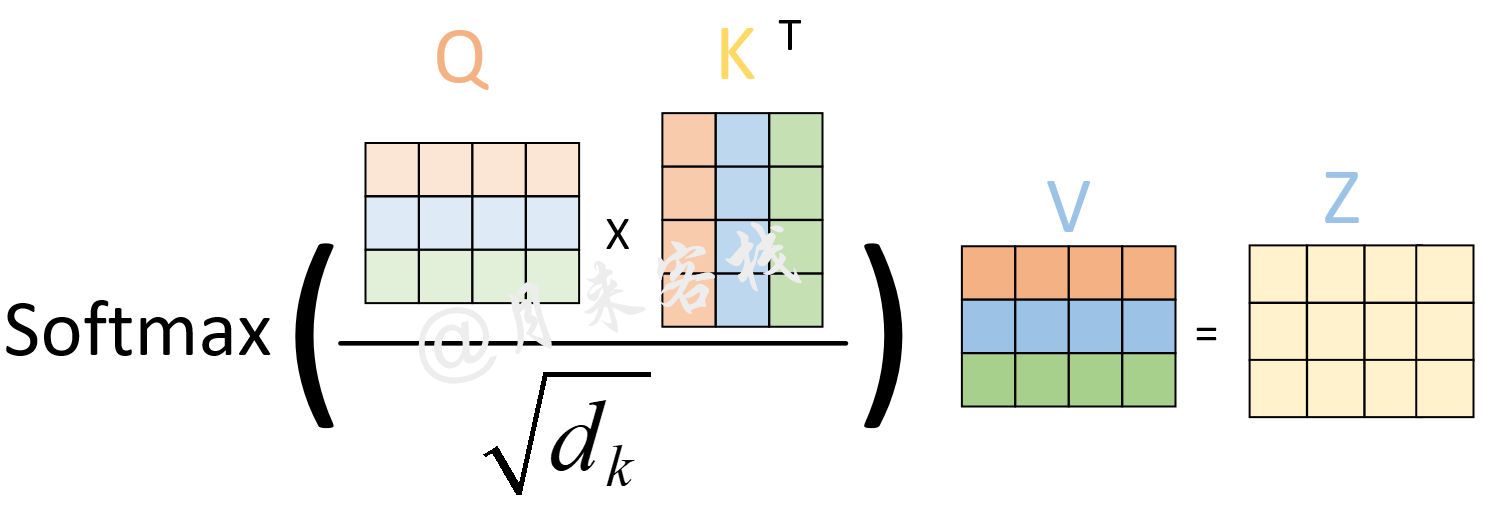
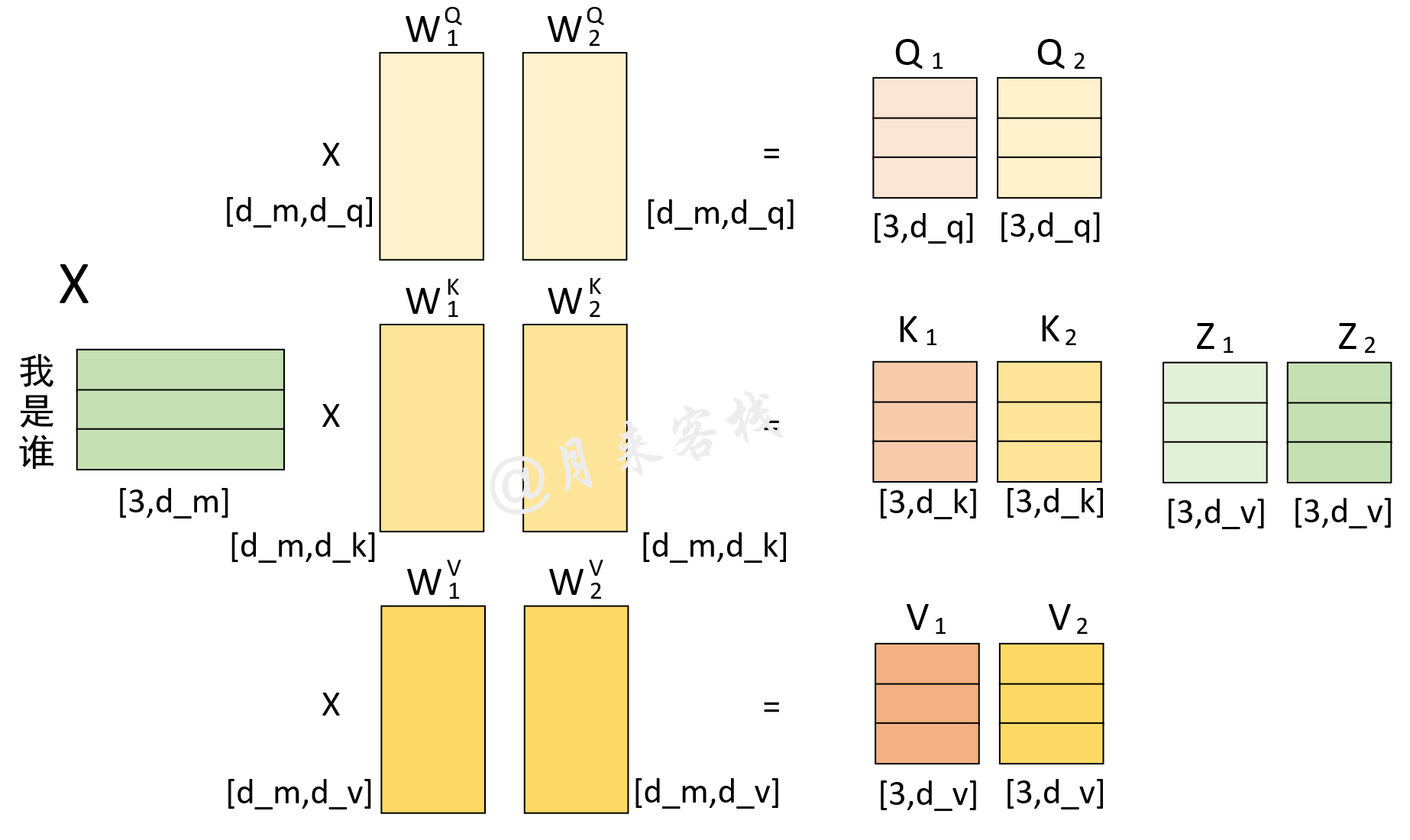
同时,为了避免单个自注意力机制计算得到的注意力权重过度集中于当前编码位置自己所在的位置(同时更应该关注于其它位置),所以作者在论文中提到通过采用多头注意力机制来解决这一问题,如图8所示。
4.1 定义类MyMultiHeadAttention
综上所述,我们可以给出类MyMultiHeadAttentiond的定义为
1class MyMultiheadAttention(nn.Module):2 def __init__(self, embed_dim, num_heads, dropout=0., bias=True):3 super(MyMultiheadAttention, self).__init__()4 """5 :param embed_dim: 词嵌入的维度,也就是前面的d_model参数,论文中的默认值为5126 :param num_heads: 多头注意力机制中多头的数量,也就是前面的nhead参数, 论文默认值为 87 :param bias: 最后对多头的注意力(组合)输出进行线性变换时,是否使用偏置8 """9 self.embed_dim = embed_dim # 前面的d_model参数10 self.head_dim = embed_dim // num_heads # head_dim 指的就是d_k,d_v11 self.kdim = self.head_dim12 self.vdim = self.head_dim13 self.num_heads = num_heads # 多头个数14 self.dropout = dropout15 assert self.head_dim * num_heads == self.embed_dim, "embed_dim 除以 num_heads必须为整数"16 # 上面的限制条件就是论文中的 d_k = d_v = d_model/n_head 条件17 self.q_proj_weight = Parameter(torch.Tensor(embed_dim, embed_dim)) # embed_dim = kdim * num_heads18 # 这里第二个维度之所以是embed_dim,实际上这里是同时初始化了num_heads个W_q堆叠起来的, 也就是num_heads个头19 self.k_proj_weight = Parameter(torch.Tensor(embed_dim, embed_dim)) # W_k, embed_dim = kdim * num_heads20 self.v_proj_weight = Parameter(torch.Tensor(embed_dim, embed_dim)) # W_v, embed_dim = vdim * num_heads21 self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)22 # 最后将所有的Z组合起来的时候,也是一次性完成, embed_dim = vdim * num_heads在上述代码中,embed_dim表示模型的维度(图8中的d_m);num_heads表示多头的个数;bias表示是否在多头线性组合时使用偏置。同时,为了使得实现代码更加高效,所以Pytorch在实现的时候是多个头注意力机制一起进行的计算,也就上面代码的第17-20行,分别用来初始化了多个头的权重值(这一过程从图8也可以看出)。当多头注意力机制计算完成后,将会得到一个形状为[src_len,embed_dim]的矩阵,也就是图8中多个Z水平堆叠后的结果。因此,第21行代码将会初始化一个线性层来对这一结果进行一个线性变换。
4.2 定义前向传播过程
在定义完初始化函数后,便可以定义如下所示的多头注意力前向传播的过程:
xxxxxxxxxx231 def forward(self, query, key, value, attn_mask=None, key_padding_mask=None):2 """3 在论文中,编码时query, key, value 都是同一个输入, 4 解码时 输入的部分也都是同一个输入, 5 解码和编码交互时 key,value指的是 memory, query指的是tgt6 :param query: # [tgt_len, batch_size, embed_dim], tgt_len 表示目标序列的长度7 :param key: # [src_len, batch_size, embed_dim], src_len 表示源序列的长度8 :param value: # [src_len, batch_size, embed_dim], src_len 表示源序列的长度9 :param attn_mask: # [tgt_len,src_len] or [num_heads*batch_size,tgt_len, src_len]10 一般只在解码时使用,为了并行一次喂入所有解码部分的输入,所以要用mask来进行掩盖当前时刻之后的位置信息11 :param key_padding_mask: [batch_size, src_len], src_len 表示源序列的长度12 :return:13 attn_output: [tgt_len, batch_size, embed_dim]14 attn_output_weights: # [batch_size, tgt_len, src_len]15 """16 return multi_head_attention_forward(query, key, value, self.num_heads,17 self.dropout, self.out_proj.weight, self.out_proj.bias,18 training=self.training,19 key_padding_mask=key_padding_mask,20 q_proj_weight=self.q_proj_weight,21 k_proj_weight=self.k_proj_weight,22 v_proj_weight=self.v_proj_weight,23 attn_mask=attn_mask)在上述代码中,query、key、value指的并不是图6中的Q、K和V,而是没有经过线性变换前的输入。例如在编码时三者指的均是原始输入序列src;在解码时的Mask Multi-Head Attention中三者指的均是目标输入序列tgt;在解码时的Encoder-Decoder Attention中三者分别指的是Mask Multi-Head Attention的输出、Memory和Memory。key_padding_mask指的是编码或解码部分,输入序列的Padding情况,形状为[batch_size,src_len]或者[batch_size,tgt_len];attn_mask指的就是注意力掩码矩阵,形状为[tgt_len,src_len],它只会在解码时使用。
注意,在上面的这些维度中,tgt_len本质上指的其实是query_len;src_len本质上指的是key_len。只是在不同情况下两者可能会是一样,也可能会是不一样。
4.3 多头注意力计算过程
在定义完类MyMultiHeadAttentiond后,就需要定义出多头注意力的实际计算过程。由于这部分代码较长,所以就分层次进行介绍。
x
1def multi_head_attention_forward(2 query, # [tgt_len,batch_size, embed_dim]3 key, # [src_len, batch_size, embed_dim]4 value, # [src_len, batch_size, embed_dim]5 num_heads,6 dropout_p,7 out_proj_weight, # [embed_dim = vdim * num_heads, embed_dim]8 out_proj_bias,9 training=True,10 key_padding_mask=None, # [batch_size,src_len/tgt_len]11 q_proj_weight=None, # [embed_dim,kdim * num_heads]12 k_proj_weight=None, # [embed_dim, kdim * num_heads]13 v_proj_weight=None, # [embed_dim, vdim * num_heads]14 attn_mask=None, # [tgt_len,src_len] 15 ):16 # 第一阶段: 计算得到Q、K、V17 q = F.linear(query, q_proj_weight)18 # [tgt_len,batch_size,embed_dim] x [embed_dim,kdim * num_heads] = [tgt_len,batch_size,kdim * num_heads]19 k = F.linear(key, k_proj_weight)20 # [src_len, batch_size,embed_dim] x [embed_dim,kdim * num_heads] = [src_len,batch_size,kdim * num_heads]21 v = F.linear(value, v_proj_weight)22 # [src_len, batch_size,embed_dim] x [embed_dim,vdim * num_heads] = [src_len,batch_size,vdim * num_heads]在上述代码中,第16-20行所做的就是根据输入进行线性变换得到图6中的Q、K和V。
x1 # 第二阶段: 缩放,以及attn_mask维度判断2 tgt_len, bsz, embed_dim = query.size() # [tgt_len,batch_size, embed_dim]3 src_len = key.size(0)4 head_dim = embed_dim // num_heads # num_heads * head_dim = embed_dim5 scaling = float(head_dim) ** -0.56 q = q * scaling # [query_len,batch_size,kdim * num_heads]78 if attn_mask is not None: # [tgt_len,src_len] or [num_heads*batch_size,tgt_len, src_len]9 if attn_mask.dim() == 2:10 attn_mask = attn_mask.unsqueeze(0) # [1, tgt_len,src_len]11 if list(attn_mask.size()) != [1, query.size(0), key.size(0)]:12 raise RuntimeError('The size of the 2D attn_mask is not correct.')13 elif attn_mask.dim() == 3:14 if list(attn_mask.size()) != [bsz * num_heads, query.size(0), key.size(0)]:15 raise RuntimeError('The size of the 3D attn_mask is not correct.')16 # 现在 atten_mask 的维度就变成了3D接着,在上述代码中第5-6行所完成的就是图7中的缩放过程;第8-15行用来判断或修改attn_mask的维度,当然这几行代码只会在解码器中的Masked Multi-Head Attention中用到。
xxxxxxxxxx91 # 第三阶段: 计算得到注意力权重矩阵2 q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)3 # [batch_size * num_heads,tgt_len,kdim]4 # 因为前面是num_heads个头一起参与的计算,所以这里要进行一下变形,以便于后面计算。 且同时交换了0,1两个维度5 k = k.contiguous().view(-1, bsz*num_heads, head_dim).transpose(0,1)#[batch_size * num_heads,src_len,kdim]6 v = v.contiguous().view(-1, bsz*num_heads, head_dim).transpose(0,1)#[batch_size * num_heads,src_len,vdim]7 attn_output_weights = torch.bmm(q, k.transpose(1, 2))8 # [batch_size * num_heads,tgt_len,kdim] x [batch_size * num_heads, kdim, src_len]9 # = [batch_size * num_heads, tgt_len, src_len] 这就num_heads个QK相乘后的注意力矩阵继续,在上述代码中第1-5行所做的就是交换Q、K、V中的维度,以便于多个样本同时进行计算;第6行代码便是用来计算注意力权重矩阵;其中上contiguous()方法是将变量放到一块连续的物理内存中;bmm的作用是用来计算两个三维矩阵的乘法操作[1]。
需要提示的是,大家在看代码的时候,最好是仔细观察一下各个变量维度的变化过程,笔者也在每次运算后进行了批注。
xxxxxxxxxx111 # 第四阶段: 进行相关掩码操作2 if attn_mask is not None:3 attn_output_weights += attn_mask # [batch_size * num_heads, tgt_len, src_len]4 if key_padding_mask is not None:5 attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)6 # 变成 [batch_size, num_heads, tgt_len, src_len]的形状7 attn_output_weights = attn_output_weights.masked_fill(8 key_padding_mask.unsqueeze(1).unsqueeze(2), float('-inf')) 9 # 扩展维度,从[batch_size,src_len]变成[batch_size,1,1,src_len]10 attn_output_weights = attn_output_weights.view(bsz * num_heads, tgt_len,src_len) 11 # [batch_size * num_heads, tgt_len, src_len]进一步,在上述代码中第2-3行便是用来执行图3中的步骤;第4-8行便是用来执行图5中的步骤,同时还进行了维度扩充。
xxxxxxxxxx151 attn_output_weights = F.softmax(attn_output_weights, dim=-1)# [batch_size * num_heads, tgt_len, src_len]2 attn_output_weights = F.dropout(attn_output_weights, p=dropout_p, training=training)3 attn_output = torch.bmm(attn_output_weights, v)4 # Z = [batch_size * num_heads, tgt_len, src_len] x [batch_size * num_heads,src_len,vdim]5 # = # [batch_size * num_heads,tgt_len,vdim]6 # 这就num_heads个Attention(Q,K,V)结果78 attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)9 # 先transpose成 [tgt_len, batch_size* num_heads ,kdim]10 # 再view成 [tgt_len,batch_size,num_heads*kdim]11 attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)1213 Z = F.linear(attn_output, out_proj_weight, out_proj_bias)14 # 这里就是多个z 线性组合成Z [tgt_len,batch_size,embed_dim]15 return Z, attn_output_weights.sum(dim=1) / num_heads # 将num_heads个注意力权重矩阵按对应维度取平均最后,在上述代码中第1-3行便是用来对权重矩阵进行归一化操作,以及计算得到多头注意力机制的输出;第13行代码便是用来对多个注意力的输出结果进行线性组合;第15行代码用来返回线性组合后的结果,以及多个注意力权重矩阵的平均值。
4.4 示例代码
在实现完类MyMultiHeadAttention的全部代码后,便可以通过类似如下的方式进行使用。
xxxxxxxxxx111if __name__ == '__main__':2 src_len = 53 batch_size = 24 dmodel = 325 num_head = 16 src = torch.rand((src_len, batch_size, dmodel)) # shape: [src_len, batch_size, embed_dim]7 src_key_padding_mask = torch.tensor([[True, True, True, False, False],8 [True, True, True, True, False]]) # shape: [src_len, src_len]910 my_mh = MyMultiheadAttention(embed_dim=dmodel, num_heads=num_head)11 r = my_mh(src, src, src,key_padding_mask = src_key_padding_mask)在上述代码中,第6-11行其实也就是Encoder中多头注意力机制的实现过程。同时,在计算过程中还可以打印出各个变量的维度变化信息:
xxxxxxxxxx181进入多头注意力计算:2 多头num_heads = 1, d_model=32, d_k = d_v = d_model/num_heads=323 query的shape([tgt_len, batch_size, embed_dim]):torch.Size([5, 2, 32])4 W_q 的shape([embed_dim,kdim * num_heads]):torch.Size([32, 32])5 Q 的shape([tgt_len, batch_size,kdim * num_heads]):torch.Size([5, 2, 32])6 ----------------------------------------------------------------------7 key 的shape([src_len,batch_size, embed_dim]):torch.Size([5, 2, 32])8 W_k 的shape([embed_dim,kdim * num_heads]):torch.Size([32, 32])9 K 的shape([src_len,batch_size,kdim * num_heads]):torch.Size([5, 2, 32])10 ----------------------------------------------------------------------11 value的shape([src_len,batch_size, embed_dim]):torch.Size([5, 2, 32])12 W_v 的shape([embed_dim,vdim * num_heads]):torch.Size([32, 32])13 V 的shape([src_len,batch_size,vdim * num_heads]):torch.Size([5, 2, 32])14 ----------------------------------------------------------------------15 ***** 注意,这里的W_q, W_k, W_v是多个head同时进行计算的. 因此,Q,K,V分别也是包含了多个head的q,k,v堆叠起来的结果 *****16 多头注意力中,多头计算结束后的形状(堆叠)为([tgt_len,batch_size,num_heads*kdim])torch.Size([5, 2, 32])17 多头计算结束后,再进行线性变换时的权重W_o的形状为([num_heads*vdim, num_heads*vdim ])torch.Size([32, 32])18 多头线性变化后的形状为([tgt_len,batch_size,embed_dim]) torch.Size([5, 2, 32])5 总结
在本篇文章中,笔者首先介绍了多层Transformer的网络结构以及其解码过程;接着详细总结了Transformer中会用到的两种掩码情况,以及为什么需要进行掩码操作;然后再次回顾了多头注意力机制的计算过程;最后,详细的介绍了通过Pytorch来实现整个多头注意力机制的过程。在下一篇文章中,笔者将会基于此处实现的多头注意力机制来一步步介绍如何实现整个Transformer网络结构。
本次内容就到此结束,感谢您的阅读!如果你觉得上述内容对你有所帮助,欢迎分享至一位你的朋友!若有任何疑问与建议,请添加笔者微信'nulls8'或加群进行交流。青山不改,绿水长流,我们月来客栈见!
引用
[1] https://pytorch.org/docs/stable/generated/torch.bmm.html?highlight=bmm#torch.bmm


